深度确定性策略梯度(Deep Deterministic Policy Gradient, DDPG)是受Deep Q-Network启发的无模型、非策略深度强化算法,是基于使用策略梯度的Actor-Critic,本文将使用pytorch对其进行完整的实现和讲解
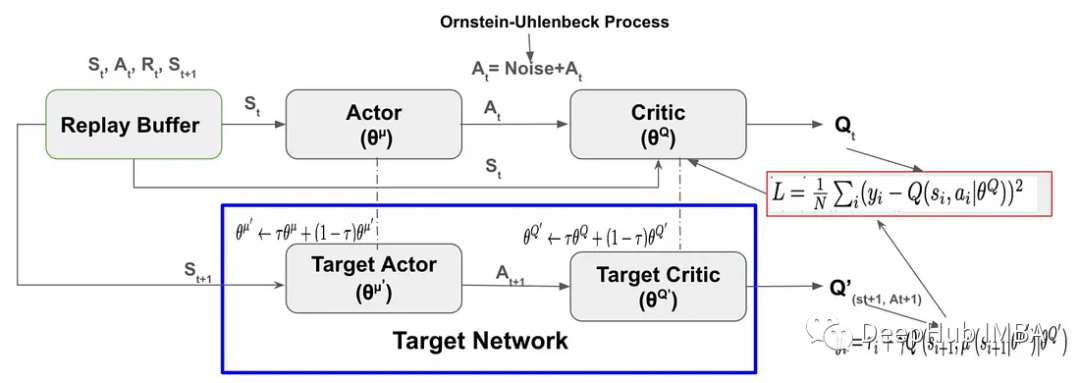
DDPG的关键组成部分是
下面我们一个一个来逐步实现:
DDPG使用Replay Buffer存储通过探索环境采样的过程和奖励(Sₜ,aₜ,Rₜ,Sₜ+₁)。Replay Buffer在帮助代理加速学习以及DDPG的稳定性方面起着至关重要的作用:
#Set Hyperparameters # Hyperparameters adapted for performance from capacity=1000000 batch_size=64 update_iteration=200 tau=0.001 # tau for soft updating gamma=0.99 # discount factor directory = './' hidden1=20 # hidden layer for actor hidden2=64. #hiiden laye for critic class DDPG(object): def __init__(self, state_dim, action_dim): """ Initializes the DDPG agent. Takes three arguments: state_dim which is the dimensionality of the state space, action_dim which is the dimensionality of the action space, and max_action which is the maximum value an action can take. Creates a replay buffer, an actor-critic networks and their corresponding target networks. It also initializes the optimizer for both actor and critic networks alog with counters to track the number of training iterations. """ self.replay_buffer = Replay_buffer() self.actor = Actor(state_dim, action_dim, hidden1).to(device) self.actor_target = Actor(state_dim, action_dim,hidden1).to(device) self.actor_target.load_state_dict(self.actor.state_dict()) self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=3e-3) self.critic = Critic(state_dim, action_dim,hidden2).to(device) self.critic_target = Critic(state_dim, action_dim,hidden2).to(device) self.critic_target.load_state_dict(self.critic.state_dict()) self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=2e-2) # learning rate self.num_critic_update_iteration = 0 self.num_actor_update_iteration = 0 self.num_training = 0 def select_action(self, state): """ takes the current state as input and returns an action to take in that state. It uses the actor network to map the state to an action. """ state = torch.FloatTensor(state.reshape(1, -1)).to(device) return self.actor(state).cpu().data.numpy().flatten() def update(self): """ updates the actor and critic networks using a batch of samples from the replay buffer. For each sample in the batch, it computes the target Q value using the target critic network and the target actor network. It then computes the current Q value using the critic network and the action taken by the actor network. It computes the critic loss as the mean squared error between the target Q value and the current Q value, and updates the critic network using gradient descent. It then computes the actor loss as the negative mean Q value using the critic network and the actor network, and updates the actor network using gradient ascent. Finally, it updates the target networks using soft updates, where a small fraction of the actor and critic network weights are transferred to their target counterparts. This process is repeated for a fixed number of iterations. """ for it in range(update_iteration): # For each Sample in replay buffer batch state, next_state, action, reward, done = self.replay_buffer.sample(batch_size) state = torch.FloatTensor(state).to(device) action = torch.FloatTensor(action).to(device) next_state = torch.FloatTensor(next_state).to(device) done = torch.FloatTensor(1-done).to(device) reward = torch.FloatTensor(reward).to(device) # Compute the target Q value target_Q = self.critic_target(next_state, self.actor_target(next_state)) target_Q = reward + (done * gamma * target_Q).detach() # Get current Q estimate current_Q = self.critic(state, action) # Compute critic loss critic_loss = F.mse_loss(current_Q, target_Q) # Optimize the critic self.critic_optimizer.zero_grad() critic_loss.backward() self.critic_optimizer.step() # Compute actor loss as the negative mean Q value using the critic network and the actor network actor_loss = -self.critic(state, self.actor(state)).mean() # Optimize the actor self.actor_optimizer.zero_grad() actor_loss.backward() self.actor_optimizer.step() """ Update the frozen target models using soft updates, where tau,a small fraction of the actor and critic network weights are transferred to their target counterparts. """ for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()): target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data) for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()): target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data) self.num_actor_update_iteration += 1 self.num_critic_update_iteration += 1 def save(self): """ Saves the state dictionaries of the actor and critic networks to files """ torch.save(self.actor.state_dict(), directory + 'actor.pth') torch.save(self.critic.state_dict(), directory + 'critic.pth') def load(self): """ Loads the state dictionaries of the actor and critic networks to files """ self.actor.load_state_dict(torch.load(directory + 'actor.pth')) self.critic.load_state_dict(torch.load(directory + 'critic.pth'))
这里我们使用 OpenAI Gym 的“MountainCarContinuous-v0”来训练我们的DDPG RL 模型,这里的环境提供连续的行动和观察空间,目标是尽快让小车到达山顶。

下面定义算法的各种参数,例如最大训练次数、探索噪声和记录间隔等等。 使用固定的随机种子可以使得过程能够回溯。
test_iteration=100
for i in range(test_iteration):
state = env.reset()
for t in count():
action = agent.select_action(state)
next_state, reward, done, info = env.step(np.float32(action))
ep_r += reward
print(reward)
env.render()
if done:
print("reward{}".format(reward))
print("Episode t{}, the episode reward is t{:0.2f}".format(i, ep_r))
ep_r = 0
env.render()
break
state = next_state我们使用下面的参数让模型收敛:
训练了75轮之后的效果如下:
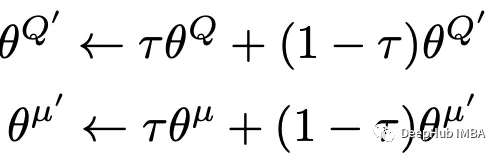
DDPG算法是一种受deep Q-Network (DQN)算法启发的无模型off-policy Actor-Critic算法。它结合了策略梯度方法和Q-learning的优点来学习连续动作空间的确定性策略。
与DQN类似,它使用重播缓冲区存储过去的经验和目标网络,用于训练网络,从而提高了训练过程的稳定性。
DDPG算法需要仔细的超参数调优以获得最佳性能。超参数包括学习率、批大小、目标网络更新速率和探测噪声参数。超参数的微小变化会对算法的性能产生重大影响。