标签中。它只显示与前端所选条目数量匹配的10行。 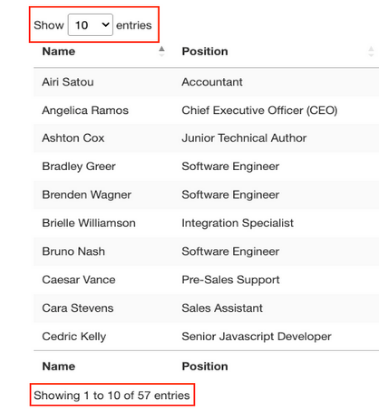
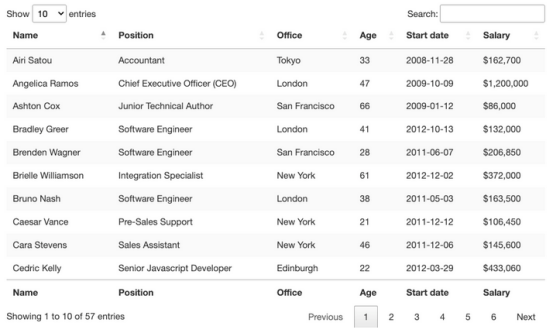
关于这个表还有一些需要了解的事情,即想要抓取的条目共有57个,并且似乎有两种访问数据的解决方案。第一种是点击下拉菜单,选择“100”,显示所有条目:
或者单击“下一步”按钮以浏览分页。

那么哪一种方案会更好?这两种解决方案都会给脚本增加额外的复杂性,因此,先检查从哪里提取数据。
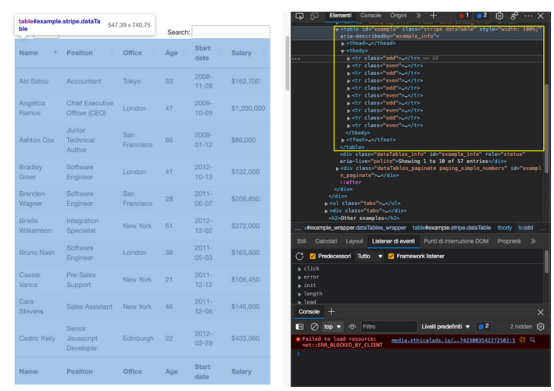
当然,因为这是一个HTML表,因此所有数据都应该在HTML文件本身上,而不需要AJAX注入。要验证这一点,需要右击>查看页面来源。接下来,复制一些单元格并在源代码中搜索它们。

对来自不同分页单元格的多个条目执行了相同的操作,尽管前端没有显示,但似乎所有目标数据都在其中。
有了这些信息,就可以开始编写代码了。
使用Python的Beautiful Soup删除HTML表
因为要获取的所有员工数据都在HTML文件中,所以可以使用Requests库发送HTTP请求,并使用Beautiful Soup解析响应。
注:对于网页抓取的新手,本文作者在Python教程中为初学者创建了一个网络抓取教程。尽管新手没有经验也可以学习,但从基础开始总是一个好主意。
1.发送主请求
在这个项目中创建一个名为python-html-table的新目录,然后创建一个名为bs4-table-scraper的新文件夹,最后创建一个新的python_table_scraper.py文件。
从终端pip3安装请求beautifulsoup4,并将它们导入到项目中,如下所示:
这是一个包含所有员工姓名的列表! 对于其余部分,只需要遵循同样的逻辑: 以JSON格式存储抓取数据允将信息用于新的应用程序 使用Pandas抓取HTML表 在离开页面之前,希望探索第二种抓取HTML表的方法。只需几行代码,就可以从HTML文档中抓取所有表格数据,并使用Pandas将其存储到数据框架中。 在项目的目录中创建一个新文件夹(将其命名为panda-html-table-scraper),并创建一个新文件名pandas_table_scraper.py。 打开一个新的终端,导航到刚刚创建的文件夹(cdpanda-html-table-scraper),并从那里安装pandas: pip install pandas
在文件的顶部导入它。
import pandas as pd
Pandas有一个名为read_html()的函数,它主要抓取目标URL,并返回所有HTML表作为DataFrame对象的列表。
要实现这一点,HTML表至少需要结构化,因为该函数将查找
之类的元素来标识文件中的表。为了使用这个函数,需要创建一个新变量,并将之前使用的URL传递给它:
employee_datapd.read_html('http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html')当输出它时,它将返回页面内的HTML表列表。
HTMLTables
如果比较DataFrame中的前三行,它们与采用BeautifulSoup抓取的结果完全匹配。
为了处理JSON,Pandas可以有一个内置的.to_json()函数。它将把DataFrame对象列表转换为JSON字符串。
而所需要做的就是调用DataFrame上的方法,并传入路径、格式(split,data,records,index等),并添加缩进以使其更具可读性:
employee_data[0].to_json('./employee_list.json', orient='index', indent=2)如果现在运行代码,其结果文件如下:
Resulting File
注意,需要从索引([0])中选择表,因为.read_html()返回一个列表,而不是单个对象。
以下是完整的代码以供参考
import pandas as pd
employee_data = pd.read_html('http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html')
employee_data[0].to_json('./employee_list.json', orient='index', indent=2)有了这些新知识,就可以开始抓取网络上几乎所有的HTML表了。只要记住,如果理解了网站的结构和背后的逻辑,就没有什么是不能抓取的。
也就是说,只要数据在HTML文件中,这些方法就有效。如果遇到动态生成的表,则需要找到一种新的方法。
原文标题:How to Use Python to Loop Through HTML Tables and Scrape Tabular Data,作者:Zoltan Bettenbuk