本文所整理的技巧与以前整理过10个Pandas的常用技巧不同,你可能并不会经常的使用它,但是有时候当你遇到一些非常棘手的问题时,这些技巧可以帮你快速解决一些不常见的问题。

默认情况下,具有有限数量选项的列都会被分配object 类型。 但是就内存来说并不是一个有效的选择。 我们可以这些列建立索引,并仅使用对对象的引用而实际值。Pandas 提供了一种称为 Categorical的Dtype来解决这个问题。
例如一个带有图片路径的大型数据集组成。 每行有三列:anchor, positive, and negative.。
如果类别列使用 Categorical 可以显着减少内存使用量。
|file|size | +------------------------+---------+ | triplets_525k.csv| 38.4 MB | | triplets_525k.csv.gzip |4.3 MB | | triplets_525k.csv.zip|4.5 MB | | triplets_525k.parquet|1.9 MB | +------------------------+---------+
读取parquet需要额外的包,比如pyarrow或fastparquet。chatgpt说pyarrow比fastparquet要快,但是我在小数据集上测试时fastparquet比pyarrow要快,但是这里建议使用pyarrow,因为pandas 2.0也是默认的使用这个。
计算相对频率,包括获得绝对值、计数和除以总数是很复杂的,但是使用value_counts,可以更容易地完成这项任务,并且该方法提供了包含或排除空值的选项。
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3],
"b": [4, 5, 6],
"category": [["foo", "bar"], ["foo"], ["qux"]]})
# let's increase the number of rows in a dataframe
df = pd.concat([df]*10000, ignore_index=True)
我们想将category分成多列显示,例如下面的
先看看最慢的apply:
def dummies_series_apply(df):
return df.join(df['category'].apply(pd.Series)
.stack()
.str.get_dummies()
.groupby(level=0)
.sum())
.drop("category", axis=1)
%timeit dummies_series_apply(df.copy())
#5.96 s ± 66.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)sklearn的MultiLabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
def sklearn_mlb(df):
mlb = MultiLabelBinarizer()
return df.join(pd.DataFrame(mlb.fit_transform(df['category']), columns=mlb.classes_))
.drop("category", axis=1)
%timeit sklearn_mlb(df.copy())
#35.1 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)是不是快了很多,我们还可以使用一般的向量化操作对其求和:
def dummies_vectorized(df):
return pd.get_dummies(df.explode("category"), prefix="cat")
.groupby(["a", "b"])
.sum()
.reset_index()
%timeit dummies_vectorized(df.copy())
#29.3 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)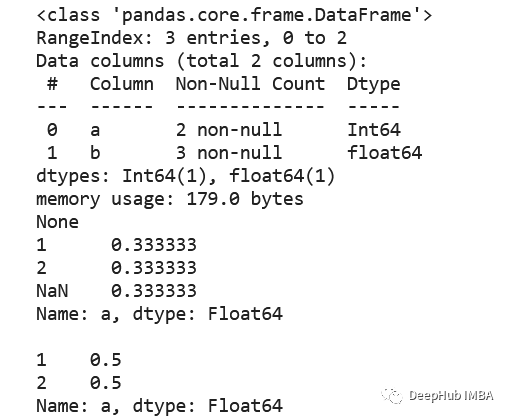
使用第一个方法(在StackOverflow上的回答中非常常见)会给出一个非常慢的结果。而其他两个优化的方法的时间是非常快速的。
我希望每个人都能从这些技巧中学到一些新的东西。重要的是要记住尽可能使用向量化操作而不是apply()。此外,除了csv之外,还有其他有趣的存储数据集的方法。不要忘记使用分类数据类型,它可以节省大量内存。感谢阅读!