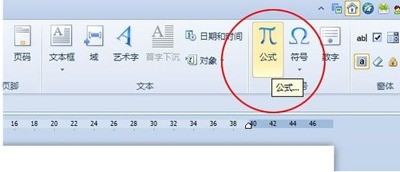
1.单击进入【插入】选项卡,在【符号】选项组中选择【公式】按钮。2.在弹出的【公式编辑器】对话框中输入你想要的公式符号。3.输入完公式后单击【文件】中的【退出并返回到 文档】按钮。4.此时,刚才输入的公式就已经嵌入到了WPS文档中来了!
软件教程 2024-04-28

uc浏览器翻译在哪?在uc浏览器中是有翻译的功能,多数的用户不知道如何使用翻译的功能,接下来就是小编为用户带来的uc浏览器翻译功能寻找方法教程,感兴趣的用户快来一起看看吧! uc浏览器使用教程 uc浏览器翻译在哪1、首先打开uc浏览器进入到
软件教程 2024-04-28

python、GIL、并发性、多线程、多进程Python 的全局解释器锁 (GIL) 是一个内置机制,它确保每次只有一个线程能够执行 Python 字节码。这个锁是为了防止数据损坏,因为它阻止了多个线程同时修改共享数据。GIL 的限制虽然
Python 2024-04-28
小伙伴们知道在使用菜鸟裹裹的时候是怎么来设置送货上门的吗?菜鸟裹裹手机免费App我们子啊使用这款平台的时候,可以看到自己包裹的一些动向对不对,有些快递站点可能离你比较远,所以过去不是很方便,这时候我们就需要送货上门了,但是你们还不是很了
软件教程 2024-04-28