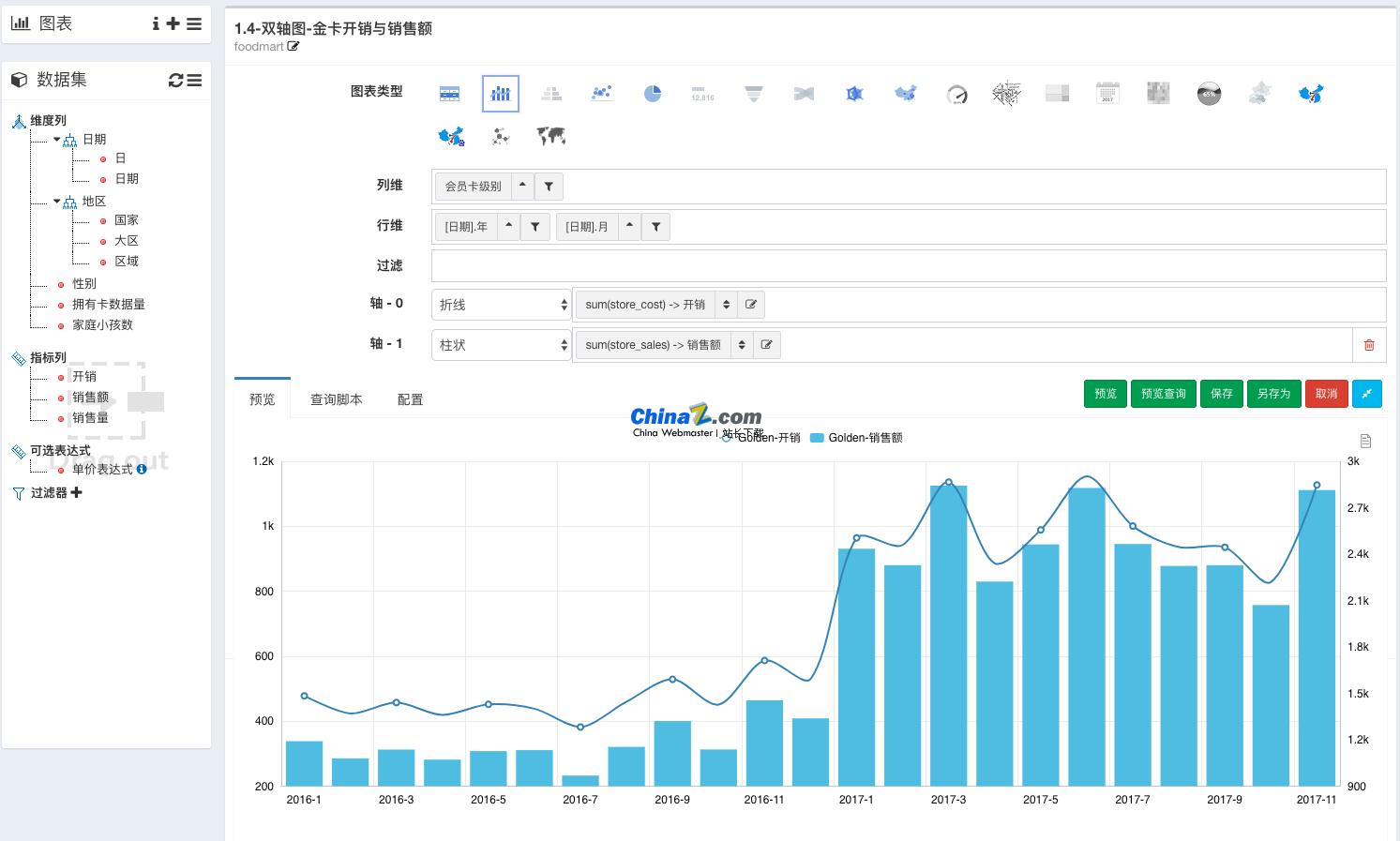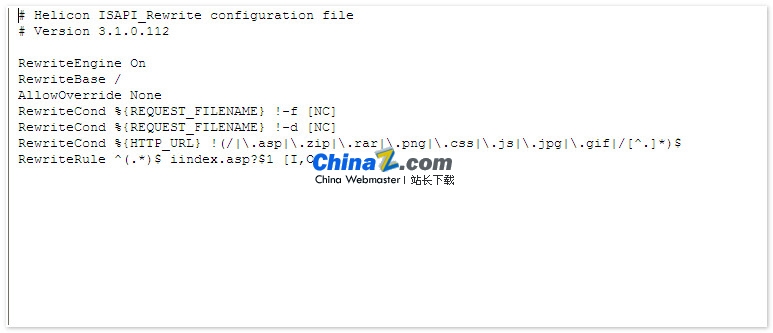
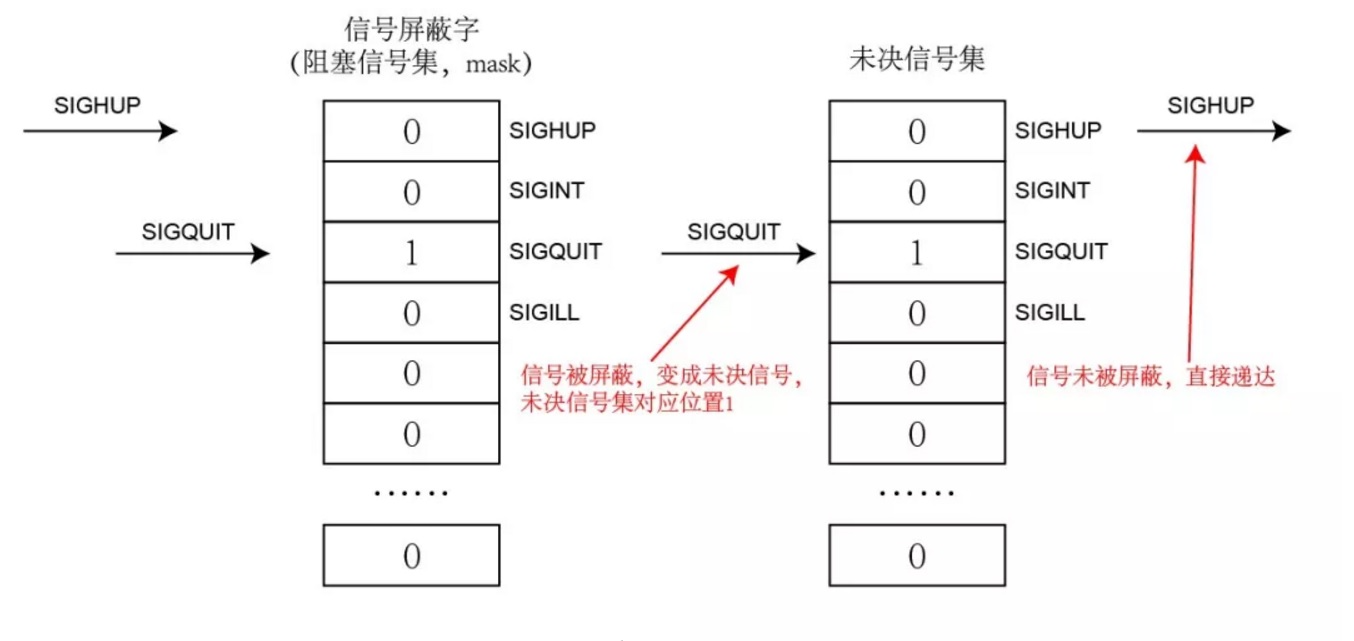
让我们先回顾一下未决信号集是什么。当信号从产生到抵达目的地时,这个过程称为信号递达。而信号从产生到递达的中间状态,则被称为信号的未决状态。产生未决状态的原因可能是信号被阻塞,也就是信号屏蔽字(或阻塞信号集)中的对应位被置为1。阻塞信号集和未
linux 2024-05-17

C++ 模板函数的命名规则要求:1. 选择非依赖名称,避免命名冲突;2. 使用模板参数前缀突出依赖关系;3. 返回辅助类型时,使用该类型作为前缀;4. 重载函数时,使用模板参数作为区分参数,避免默认模板参数。模板函数命名中的特殊注意事项在
C++ 2024-05-17

在游戏开发中,Java 数据结构和算法至关重要,可高效处理数据。数据结构包括数组(存储固定元素)、链表(存储动态数据)、队列(FIFO)。算法包括搜索算法(查找元素)、排序算法(排列元素)、贪心算法(优化决策)。实战案例包括角色寻路(A*
java 2024-05-17
1. git的基本概念Git是一个分布式版本控制系统,它允许您跟踪代码库的变化并协作开发。与其他版本控制系统不同,Git将每个提交存储为一个独立的快照,这使得您可以在任何时候轻松地回退到以前的版本。2. 安装Git在您的计算机上安装Git。
java 2024-05-17