

EPLB-DeepSeek开源专家级并行负载均衡器
作者:互联网
2026-03-28
 ⼤语⾔模型脚本
⼤语⾔模型脚本
EPLB专家并行负载均衡器通过创新的冗余专家策略和智能分配机制,有效解决了大规模模型训练中的资源利用率问题。下面将从技术原理到应用场景全面解析这一创新方案。
EPLB的核心价值
- 智能负载调节:通过实时监测专家模型负载情况,动态调整复制与分配方案,确保各GPU负载差异最小化。
- 资源复制策略:采用冗余专家机制对高负载模块进行智能复制,有效缓解资源分配不均的难题。
- 硬件效能提升:优化GPU资源利用率,消除因负载失衡导致的性能瓶颈,大幅提升训练效率。
- 网络传输优化:通过科学规划专家位置分布,显著降低节点间通信成本,减少延迟影响。
- 多策略适配:提供层次化和全局两种均衡模式,满足不同训练阶段和场景的特殊需求。
- 复杂模型支持:完美适配多层混合专家架构,实现灵活高效的专家分配与映射管理。
EPLB的技术实现
- 冗余专家机制:针对输入数据和模型结构导致的负载差异,通过复制高负载专家实现平衡。重要专家可多副本部署到不同GPU,避免单卡过载。
- 分层均衡方案:首先将专家组均衡分配到各节点,确保节点间负载平衡;然后在节点内部进行二次专家复制分配,实现节点内资源优化。同组专家尽量集中部署,降低跨节点通信频率。
- 全局均衡方案:当节点数与专家组数不匹配时,突破分组限制进行全局专家复制分配。根据实时负载情况动态调整副本数量和位置,确保整体资源平衡。
- 动态评估系统:基于历史统计数据的移动平均值进行负载预测,根据实时评估结果动态优化复制与分配策略,适应训练各阶段需求。
- 资源映射体系:通过rebalance_experts函数生成专家部署方案,建立物理到逻辑的双向映射关系,精确记录每个专家的副本数量。

EPLB的运行模式
- 分层均衡模式:在节点数可整除专家组数时启用,通过分层优化实现节点内外双重负载平衡。
- 全局均衡模式:适用于节点数与专家组数不匹配场景,或需要更大规模并行时,进行全局范围的专家调度。
EPLB的实践案例
- 以两层MoE模型为例,每层12个专家,引入4个冗余专家。最终16个副本部署在2个节点上,每个节点配备4个GPU。
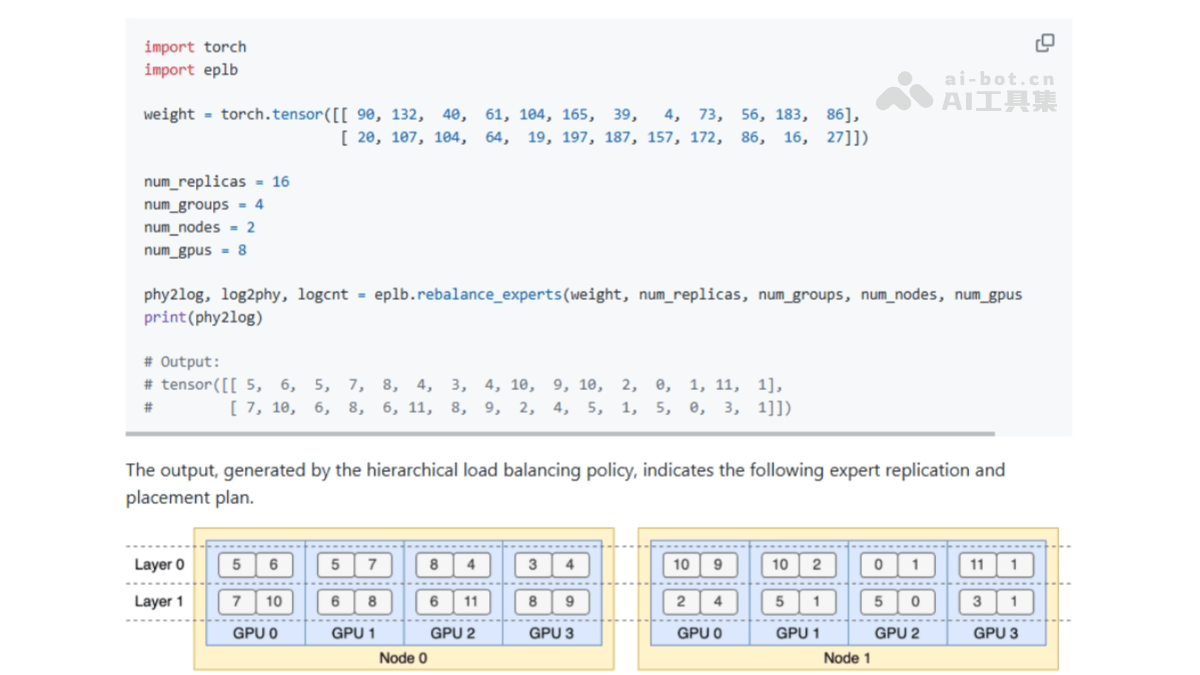
EPLB的适用领域
- 分布式训练:多节点多GPU环境下,根据需求智能切换均衡模式,实现资源最大化利用。
- 训练初期:采用分层均衡减少跨节点通信,提升小规模并行效率。
- 训练后期:启用全局均衡应对大规模并行需求,动态调整负载分配。
- 异构环境:在硬件配置不均衡时,通过全局模式灵活适配,保持高效运行。
- 动态场景:根据训练过程中负载变化实时调整策略,确保系统稳定性。
EPLB通过创新的负载均衡机制和智能调度策略,为大规模模型训练提供了高效稳定的解决方案,显著提升了分布式训练的整体效率。
相关标签:
可灵AI
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字
03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
03/30
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
AI精选