

BabyVision由UniPatAI团队研发的多模态理解评测集
作者:互联网
2026-03-27
 ⼤语⾔模型脚本
⼤语⾔模型脚本
BabyVision作为专业的多模态评测工具,通过精心设计的视觉任务评估模型核心能力,为AI发展提供重要参考。
BabyVision是什么
这款由专业团队研发的评测集专注于评估多模态模型的视觉理解水平。其创新性地设置了MLLM评估和生成评估双赛道,包含四大视觉能力类别下的22项子任务。388道题目经过特殊设计,能有效排除语言干扰,精准测试模型的真实视觉推理能力。
BabyVision的主要功能
- 评估多模态模型的视觉推理能力:通过严谨的视觉任务设计,准确测试各类模型在纯视觉场景下的实际表现,有效识别其视觉理解短板。
- 提供两个评估赛道:MLLM评估针对多模态语言模型,生成评估则面向图像生成模型,实现多模态模型的全方位测评。
- 涵盖四大视觉能力类别:精细辨别、视觉追踪、空间感知和视觉模式识别等多样化任务,全面检验模型在不同视觉场景的推理能力。
- 严格控制语言依赖:确保所有任务必须通过视觉理解完成,防止模型利用语言提示取巧,真实反映其视觉认知水平。
- 提供详细的评测结果和排行榜:采用准确率等量化指标展示模型表现,并与人类基准进行直观对比,为研究提供可靠依据。
- 支持快速启动和灵活配置:配套完整数据集、评估脚本和详细文档,支持通过环境变量灵活调整参数,大幅提升研究效率。
- 推动多模态技术的发展:通过精准定位模型缺陷,为技术优化指明方向,促进视觉任务处理能力的持续提升。
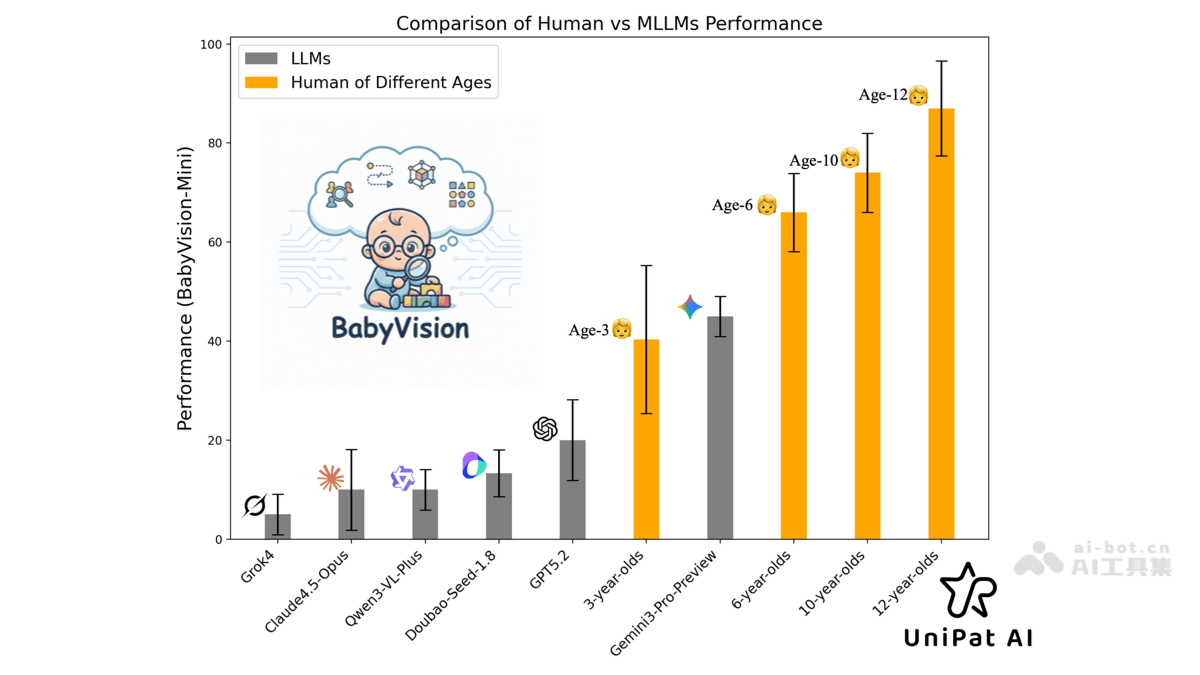
BabyVision的评测结果
- 人类基线表现卓越:测试数据显示,人类在视觉推理任务中保持94.1%的高准确率,显著优于AI模型。
- 闭源模型表现参差不齐:Gemini3-Pro-Preview以49.7%领先,GPT-5.2和Doubao-Seed-1.8分别为34.4%和30.2%,整体与人类存在明显差距。
- 开源模型差距明显:Qwen3-VL-Plus仅19.2%的准确率反映出开源模型在视觉任务上的明显不足。
- 模型在视觉任务上存在短板:连续追踪、空间想象等复杂视觉任务普遍成为各类模型的薄弱环节。
- 生成式评估结果不理想:虽然部分模型展现出类人行为特征,但整体仍缺乏稳定输出正确解的能力。
- 评测结果推动技术改进:通过清晰揭示模型缺陷,为多模态技术的优化创新提供明确方向。
BabyVision的项目地址
- Github仓库:https://github.com/UniPat-AI/BabyVision
BabyVision的应用场景
- 多模态模型评估:系统化测评各类模型在视觉推理任务中的表现,帮助研究人员准确掌握模型能力边界。
- 技术研究与开发:作为标准化测试平台,助力多模态模型的研发优化,推动视觉推理技术进步。
- 模型性能比较:通过统一评测标准,实现不同模型在视觉任务上的客观对比。
- 教育与学习工具:为教学研究提供专业的多模态AI认知能力测评工具。
- 行业应用参考:为自动驾驶等需要视觉推理的领域提供可靠的模型性能参考。
- 学术研究与发表:提供严谨的实验数据支持,促进多模态AI领域的学术发展。
BabyVision通过科学的评测体系揭示了多模态模型的视觉认知短板,为AI技术发展提供了重要参考依据。
相关标签:
Gemini
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字
03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
03/30
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
AI精选