

OmniAvatar-浙江大学与阿里巴巴合作研发音频驱动全身视频生成模型
作者:互联网
2026-03-27
 ⼤语⾔模型脚本
⼤语⾔模型脚本
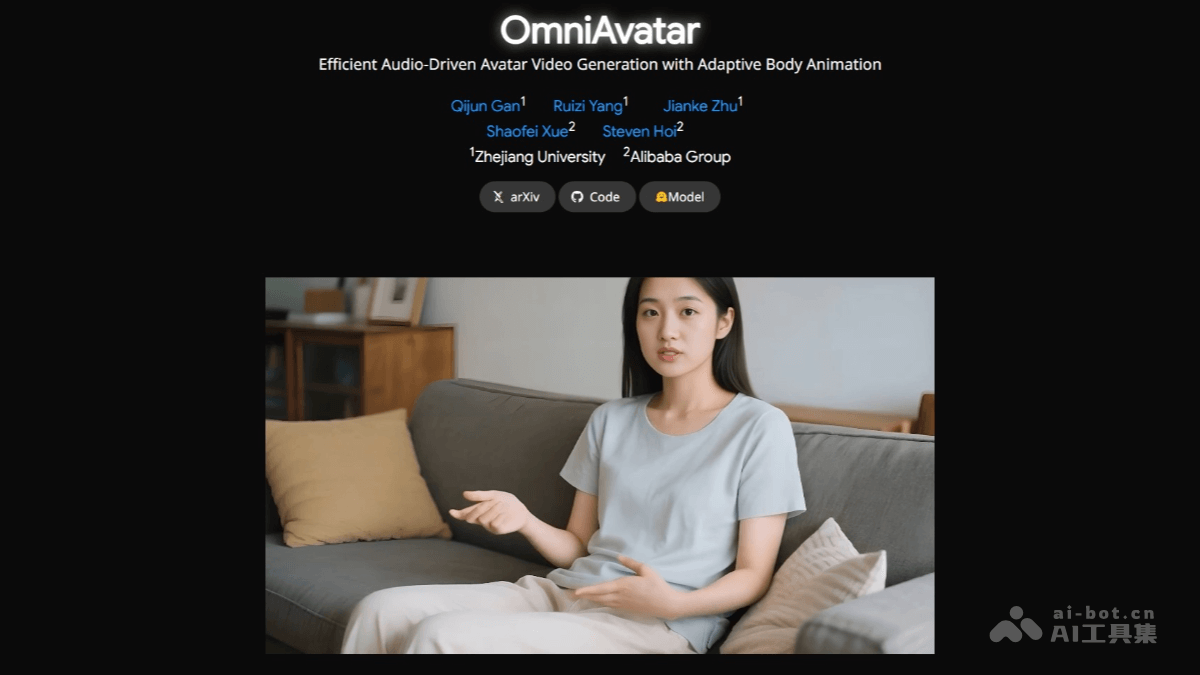
OmniAvatar作为新一代音频驱动视频生成技术,通过创新算法实现了人物动作与语音的高度同步,为数字内容创作带来全新可能。
OmniAvatar的主要功能
- 自然唇部同步:该技术能精确匹配语音节奏,即使在复杂环境下也能确保口型的高度吻合。
- 全身动画生成:系统可流畅呈现人物从头部到脚部的协调运动,大幅提升动画的真实感。
- 文本控制:通过文字指令即可精确调整视频要素,包括人物行为、环境设置及情绪表达等个性化参数。
- 人物与物体交互:能够模拟真实世界的互动场景,比如抓取物品或操作设备等实用功能。
- 背景控制:可根据需求自由切换场景背景,满足多样化的视觉呈现要求。
- 情绪控制:支持调整面部表情和肢体语言,准确传达喜怒哀乐等不同情绪状态。
OmniAvatar的技术原理
- 像素级多级音频嵌入策略:将声波特征精确映射到视觉空间,实现音画在微观层面的完美融合。
- LoRA训练方法:采用低秩适应技术优化模型参数,在保持性能的同时显著提升训练效率。
- 长视频生成策略:通过身份特征锁定和帧间过渡技术,确保长时间视频的连贯性与一致性。
- 基于扩散模型的视频生成:运用去噪过程逐步构建高质量视频画面,特别擅长处理长时间序列数据。
- Transformer架构:借助注意力机制捕捉视频帧间的深层关联,增强整体内容的逻辑连贯性。
OmniAvatar的项目地址
- 项目官网:https://omni-avatar.github.io/
- GitHub仓库:https://github.com/Omni-Avatar/OmniAvatar
- HuggingFace模型库:https://huggingface.co/OmniAvatar/OmniAvatar-14B
- arXiv技术论文:https://arxiv.org/pdf/2506.18866
OmniAvatar的应用场景
- 虚拟内容制作:大幅简化数字形象创作流程,适用于各类新媒体内容产出。
- 互动社交平台:为用户提供高度拟真的虚拟化身交互体验。
- 教育培训领域:创造具有自然教学姿态的虚拟讲师形象。
- 广告营销领域:按需定制品牌代言人的形象特征和行为模式。
- 游戏与虚拟现实:快速生成富有表现力的游戏角色,增强沉浸式体验。
OmniAvatar通过突破性的技术方案,正在重塑数字内容生产方式,为多个行业带来创新解决方案。
相关标签:
Diffusion
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
04|MCP 服务接口:让本地能力变成 Agent 可调用的 Tools
04/18
为什么需要KVCache?
04/18
Claude 一个插件,让全球软件股蒸发 2850 亿美元
04/18
如何创建一个 Agent Skill?
04/18
打造 GitHub 仓库智能推荐系统
04/18
挣脱上下文的枷锁:OpenViking,为 AI Agent 而生的开源上下文数据库
04/18
Claude Opus 4.6 和 GPT-5.3 Codex 同时发布,OpenAI 极限截杀 Opus 4.6!
04/18
数据库巡检进入智能时代:异常检测算法的落地实践
04/18
阿里开源AgentScope多智能体框架解析系列(十八)第18章:企业Skill系统实战 - 用户行为深度分析
04/18
2025年终总结:AI浪潮下的一年
04/18
AI精选