

KimiLinear月之暗面开源混合线性注意力新架构
作者:互联网
2026-03-20
 ⼤语⾔模型脚本
⼤语⾔模型脚本
Kimi Linear作为新一代混合线性注意力架构,通过创新设计显著提升了大语言模型处理长序列任务的效率。其核心KDA模块与全注意力层的混合结构,在保持性能的同时大幅优化了计算资源消耗。
Kimi Linear是什么
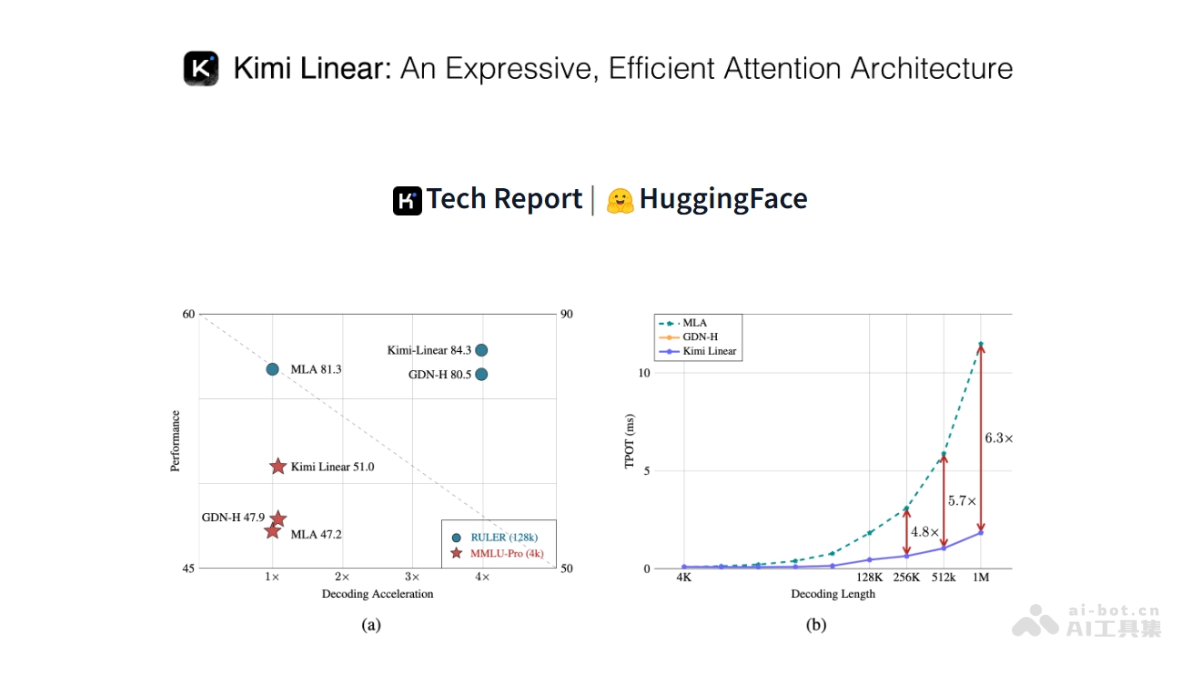
月之暗面推出的Kimi Linear是一种创新的混合线性注意力架构,专为提升大语言模型在长序列任务中的表现而设计。该架构通过独特的Kimi Delta Attention模块和3:1的混合设计,不仅减少了75%的KV缓存使用,更在处理百万级文本时实现了6.3倍的解码速度提升,在各类任务中均展现出优于传统全注意力机制的性能。
Kimi Linear的主要功能
- 高效处理长序列任务:采用混合架构显著降低KV缓存需求,在百万级文本解码中实现6.3倍性能提升。
- 精准信息管理:通道级门控机制可智能筛选关键信息,大幅增强长序列处理能力。
- 强化推理性能:在复杂推理任务中训练效率更高,测试表现优于传统注意力模型。
- 硬件优化设计:利用现代GPU特性提升计算吞吐,有效减少资源消耗。
- 广泛任务适配:在语言理解、代码生成等多样化场景中均展现出优异性能。
Kimi Linear的技术原理
- 混合注意力架构:3:1的KDA与MLA组合设计,兼顾效率与表现力。
- KDA核心技术:
- 精细化门控:各特征维度独立控制,增强位置感知能力。
- 高效块处理:优化算法提升硬件利用率,降低计算复杂度。
- 无位置编码设计:MLA层不采用显式编码,简化架构并提升长文本处理能力。
- MoE技术融合:通过稀疏激活模式扩展参数规模,提升整体效率。
Kimi Linear的项目地址
- HuggingFace模型库:https://huggingface.co/moonshotai/Kimi-Linear-48B-A3B-Instruct
- 技术论文:https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf
Kimi Linear的应用场景
- 长文本创作:百万级文本处理能力使其成为生成长篇内容的理想选择。
- 代码处理:高效解析和生成长代码片段,支持复杂逻辑实现。
- 数学求解:在数学推理任务中展现出快速学习能力和优异表现。
- 语言理解:长短文本处理俱佳,支持深入语义分析。
- 多模态应用:适用于需要长文本描述和复杂推理的跨模态任务。
Kimi Linear凭借其创新架构和卓越性能,为大语言模型的长序列处理开辟了新路径,在多样化应用场景中展现出广阔前景。
相关标签:
Kimi
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
厦门大学DeepSeek大模型助力高校企业政府发展 PDF文件 AI教程资料
03/30
RAG 不一定非得靠向量库:一套更偏工程落地的“结构化推理检索”方案
03/30
北京大学DeepSeek与AIGC应用PDF AI教程资料
03/30
开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
03/30
金灵AI深度体验报告 CSDN推出金融投研AI智能助手
03/30
AI精选