

模型怎样记忆长期上下文全解析
作者:互联网
2026-03-26
 ⼤语⾔模型脚本
⼤语⾔模型脚本
AI模型通过内部记忆与外部记忆两种机制实现长期上下文处理,其工作原理与人类记忆存在本质差异。
内部记忆依赖于模型架构(如Transformer的注意力机制)在单次对话中处理有限长度的信息,被称为"上下文窗口"。
外部记忆通过将信息存储在模型之外的数据库(如向量数据库)中,在需要时检索,实现跨越多次对话的持久化记忆。用户可以通过明确指令、结构化输入等方式帮助模型更好地"记住"关键信息,通过管理记忆功能来控制模型的"遗忘"。

核心概念:AI的"记忆"究竟是什么?
人工智能的"记忆"机制与传统认知存在根本区别。不同于人脑存储具体事件的能力,AI通过数据学习形成抽象关联,这种动态过程源于海量训练和参数调整。
模型如何"学习"而非"记忆"
AI模型的核心能力在于从数据中学习,不是简单地记忆数据。这种学习过程是一个复杂的优化问题,目标是让模型能泛化,对从未见过的数据做出准确的预测或生成合理的响应。
- 训练过程:模型通过调整其内部数以亿计的参数来"学习",这些参数共同定义了模型如何处理和解释输入信息。
- 记忆本质:学习到的关联和规律,而非具体的存储条目。模型学习概念间的统计关联。
模型的"内部记忆"机制
现代AI模型特别是处理序列数据的模型,其架构内置"内部记忆"机制。该功能允许模型在处理当前信息时,动态参考之前处理过的信息。
短期记忆与长期记忆的区分
| 特征 | 短期记忆 (上下文窗口) | 长期记忆 (外部存储) |
|---|---|---|
| 功能 | 保持当前对话的连贯性,处理即时任务 | 实现跨会话记忆,提供个性化服务,存储持久知识 |
| 存储位置 | 模型内部,作为输入的一部分 | 外部系统,如向量数据库、知识图谱 |
| 容量 | 有限,受上下文窗口大小限制 | 理论上无限,取决于外部存储的容量 |
| 持久性 | 临时性,会话结束后即消失 | 持久性,可以长期保存和更新 |
| 实现方式 | 作为模型的输入直接处理 | 通过检索增强生成(RAG)等技术动态检索和整合 |
| 比喻 | 工作记忆、临时笔记本 | 档案库、日记本 |
AI模型的"记忆"并非永久性的。即使是通过训练学习到的"长期记忆",也可能随着时间的推移或新数据的引入而发生变化。
AI的"记忆"是一个动态的、可塑的、并且受到多种因素影响的过程,不是一个静态的、永久的数据库。
技术原理:不同模型的"记忆"方式
注意力机制:像聚光灯一样聚焦关键信息
注意力机制可以被形象地比喻为一个聚光灯。当模型处理一段文本中的某个词时,不会孤立地看待这个词,是会"照亮"文本中的其他所有词,根据它们与当前词的相关性,分配不同的"亮度"或"权重"。
比喻:百科全书式的学者
基于Transformer的模型就像一个拥有百科全书式知识的学者,他不会去逐字回忆某本书中的具体段落,而是会从庞大的知识体系中,迅速地调动和整合相关的概念、事实和逻辑。
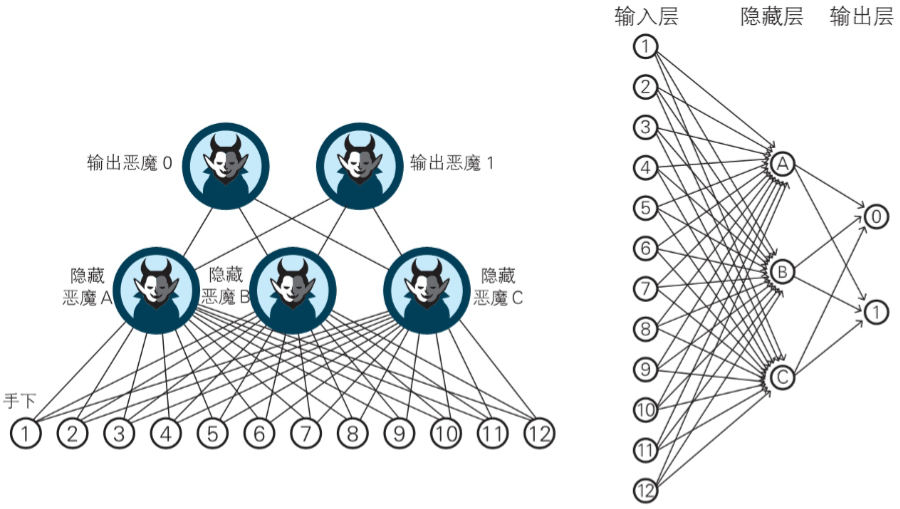
传统模型的"记忆":RNN与LSTM
在Transformer出现之前,循环神经网络(RNN)及其变体,如长短期记忆网络(LSTM),是处理序列数据的主流模型。
比喻:流水账记录员与智能档案管理员
RNN:像流水账一样传递信息,传统的RNN可以被看作一个"流水账记录员"。按顺序处理文本,每次处理一个词,并将当前词的信息与之前积累的信息结合起来,传递给下一步。
LSTM:有选择地"记住"和"忘记",LSTM引入了一种精巧的"门控机制",能像一个"智能档案管理员"一样,有选择地"记住"或"忘记"信息。LSTM的内部结构包含三个关键的"门":遗忘门、输入门和输出门。
模型对比:不同记忆机制的优劣
| 特性 | Transformer (注意力机制) | LSTM (门控机制) | 传统RNN |
|---|---|---|---|
| 记忆方式 | 动态、全局注意力,并行处理 | 选择性记忆,顺序处理 | 顺序传递,信息易衰减 |
| 长期依赖 | 优秀,能直接捕捉任意距离的词间关系 |
相关标签:
ChatGPT
相关推荐 专题 + 收藏 + 收藏 + 收藏 + 收藏 + 收藏 最新数据 相关文章 OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理 03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字 03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准 03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建 03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板 03/30
SkyBot由Skywork研发的云电脑AI助手 03/30
AI Agent 智能体 - Multi-Agent 架构入门 03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程 03/30
一文搞懂卷积神经网络经典架构-LeNet 03/30
一文搞懂深度学习中的池化! 03/30
AI精选 |