

NVILA英伟达视觉语言大模型问世
作者:互联网
2026-03-25
 ⼤语⾔模型脚本
⼤语⾔模型脚本
NVILA作为NVIDIA推出的新一代视觉语言模型,凭借独特的技术架构在效率与精度间取得突破。其创新的"扩展-压缩"策略和系统优化设计,使其在图像视频处理领域展现出卓越性能。
NVILA是什么
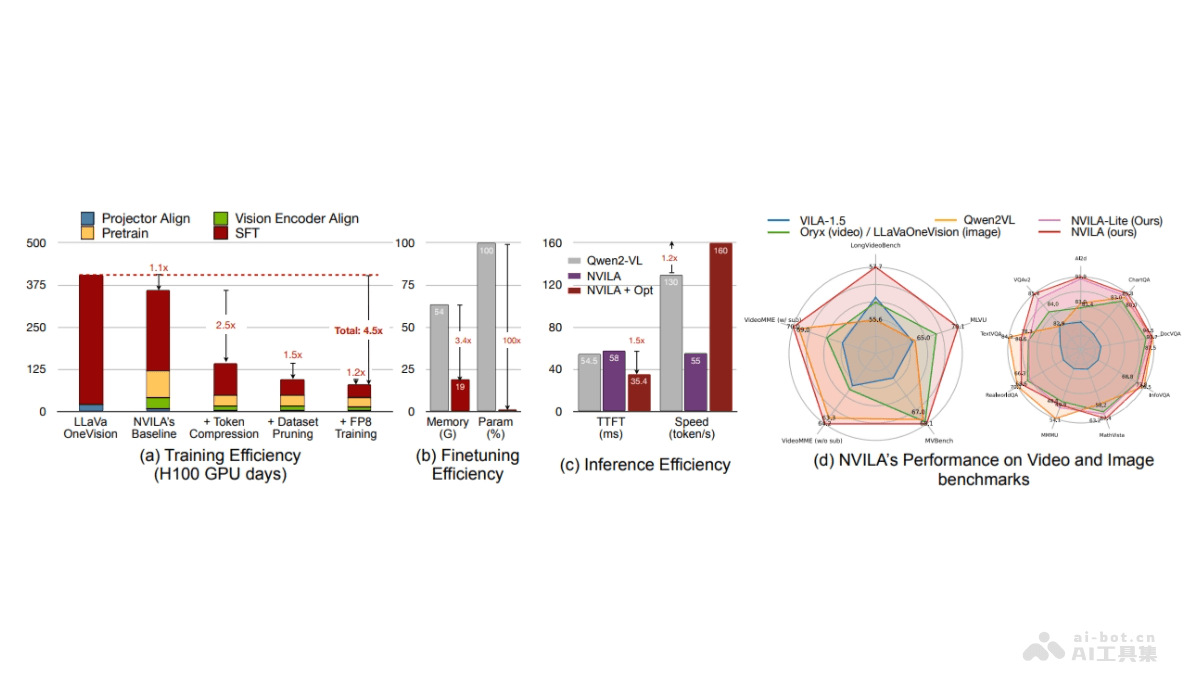
NVILA是NVIDIA研发的先进视觉语言模型系列,采用创新的技术路线实现性能平衡。该模型通过"先扩展后压缩"的独特策略,显著提升高分辨率图像和长视频的处理能力。经过系统优化的训练流程大幅降低资源消耗,在图像视频基准测试中表现优异,性能超越Qwen2VL等主流开源模型,并媲美GPT-4o等商业解决方案。更值得关注的是,该模型开创性地支持时间定位、机器人导航等前沿应用场景。
NVILA的主要功能
- 高分辨率图像和长视频处理:NVILA突破性地实现高分辨率图像和长视频的高效解析,同时保持卓越的准确度。
- 效率优化:从模型训练到实际部署,NVILA全程贯彻效率优化理念。
- 时间定位:提供精准的视频时间定位能力。
- 机器人导航:作为机器人视觉导航系统核心组件,支持实时运行。
- 医疗多模态应用:通过整合多专家模型,显著提升医疗诊断的准确性。
NVILA的技术原理
- "扩展-压缩"方法:先提升时空分辨率,再压缩视觉令牌实现效率与精度平衡。
- 动态S2:自适应处理不同比例图像,提取多尺度高分辨率特征。
- FP8混合精度训练:采用先进训练技术加速过程,同时确保模型精度。
- 数据集修剪:运用DeltaLoss方法智能筛选训练数据,优化样本质量。
- 量化技术:结合W8A8和W4A16量化方案,提升部署效率。
- 参数高效微调:针对不同任务需求,选择性微调特定模块降低内存占用。
NVILA的项目地址
- GitHub仓库:https://github.com/NVlabs/VILA(即将开源)
- HuggingFace模型库:https://huggingface.co/collections/Efficient-Large-Model/nvila(即将开源)
- arXiv技术论文:https://arxiv.org/pdf/2412.04468
NVILA的应用场景
- 图像和视频理解:广泛应用于视觉问答、内容分类和视频摘要等场景。
- 机器人导航:作为智能导航系统核心,帮助机器人融合视觉与语言信息进行决策。
- 医疗成像:提升医学图像分析能力,优化病理诊断和放射影像处理流程。
- 时间定位:精准识别视频中的时间节点,赋能内容检索和事件检测。
- 多模态交互:为智能助手等交互系统提供更精准的多模态理解能力。
NVILA凭借其创新技术架构和广泛适用性,正在重塑视觉语言处理领域的格局,为各行业智能化转型提供强劲动力。
相关标签:
Gemini
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
厦门大学DeepSeek大模型助力高校企业政府发展 PDF文件 AI教程资料
03/30
RAG 不一定非得靠向量库:一套更偏工程落地的“结构化推理检索”方案
03/30
北京大学DeepSeek与AIGC应用PDF AI教程资料
03/30
开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
03/30
金灵AI深度体验报告 CSDN推出金融投研AI智能助手
03/30
GSD 使用指南:高效交付功能的结构化工作流
03/30
AI精选