

Jamba由AI21开源的首款Mamba架构大模型
作者:互联网
2026-03-25
 ⼤语⾔模型脚本
⼤语⾔模型脚本
Jamba作为AI21 Labs推出的创新大语言模型,首次将Mamba架构与传统Transformer相结合,展现出强大的文本处理能力和高效性能。这种混合架构不仅支持256K上下文窗口,更在资源占用和输出质量间取得了突破性平衡。
Jamba是什么
作为首个基于Mamba架构的生产级大模型,Jamba突破了传统Transformer的局限。该模型创造性地融合了结构化状态空间模型与Transformer架构,在保持高质量输出的同时,显著提升了吞吐效率。其256K上下文窗口设计,使长文本处理能力达到行业领先水平。
采用Apache 2.0开源许可的Jamba,目前以研究模型形式开放权重。虽然暂未针对商业场景优化,但AI21 Labs已预告将推出经过微调的安全版本,为后续应用奠定基础。

Jamba的官网入口
- 官方项目主页:https://www.ai21.com/jamba
- 官方博客介绍:https://www.ai21.com/blog/announcing-jamba
- Hugging Face地址:https://huggingface.co/ai21labs/Jamba-v0.1
Jamba的主要特性
- SSM-Transformer混合架构:创新性地将Mamba SSM与传统Transformer结合,这种生产级混合架构大幅提升了模型效能。
- 大容量上下文窗口:256K的超长上下文支持,使复杂文本处理成为可能。
- 高吞吐量:相比Mixtral 8x7B,在处理长文本时实现3倍效率飞跃。
- 单GPU大容量处理:单块GPU即可支持140K上下文处理,显著降低部署门槛。
- 开放权重许可:Apache 2.0许可赋予开发者自由修改权,推动技术共享创新。
- NVIDIA API集成:通过NVIDIA NIM微服务,为企业级部署提供便捷通道。
- 优化的MoE层:智能参数激活机制,在不增加算力需求下提升模型容量。
Jamba的技术架构
Jamba采用模块化设计,通过精心配置的块层结构,成功整合两种架构优势。每个功能块包含注意力层或Mamba层,配合多层感知器,形成1:8的Transformer层配比。
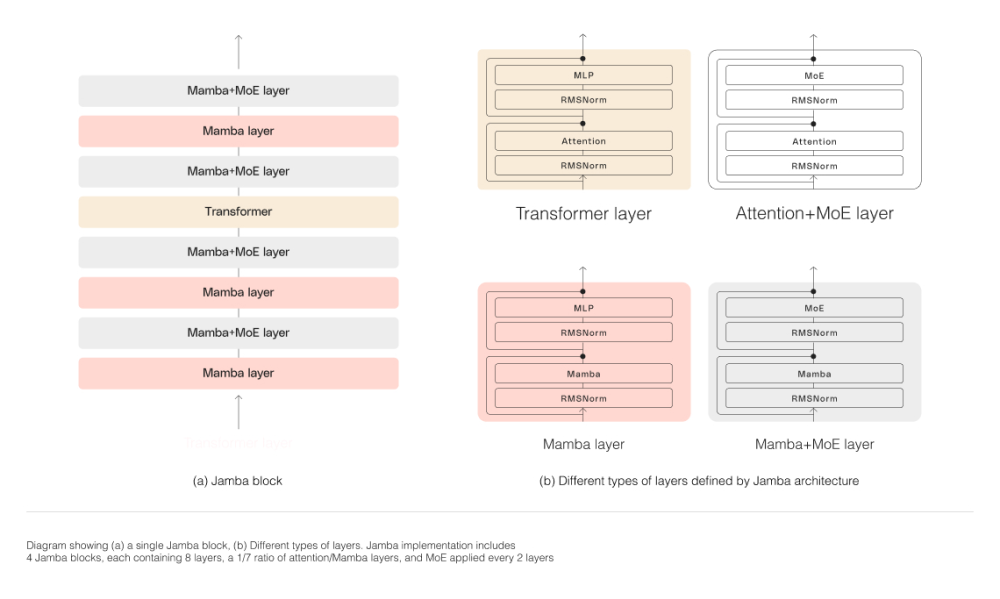
MoE技术的引入使模型在保持计算效率的同时,大幅扩展参数规模。经过特别优化的专家层配置,确保在80GB GPU上实现最佳性能平衡。
Jamba的性能对比
基准测试数据显示,Jamba在HellaSwag、ArcChallenge等多项评估中表现卓越。无论是语言理解还是科学推理任务,其性能均超越同尺寸的主流模型,包括Llama2系列和Gemma等竞争对手。
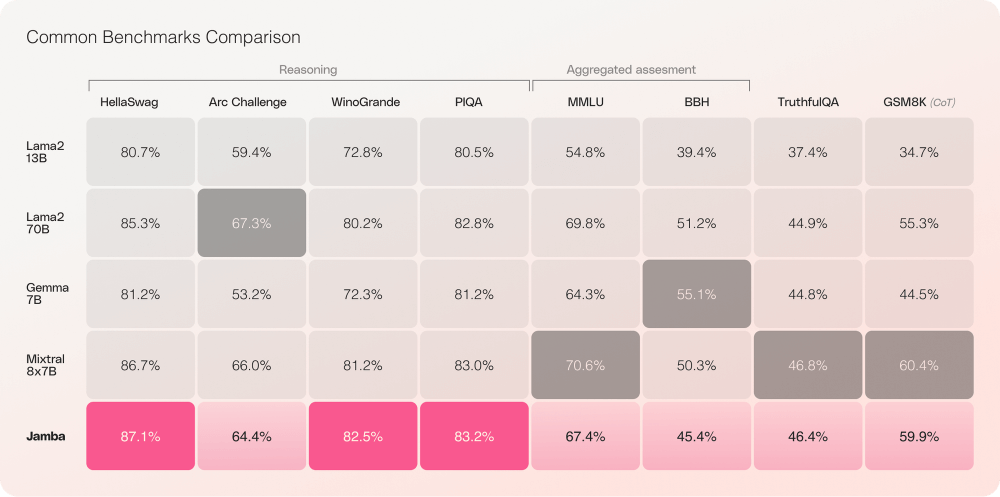
Jamba通过创新架构与前沿技术的融合,为大规模语言处理树立了新标杆。其出色的性能表现和开放生态,预示着AI模型发展的新方向。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
SkyBot由Skywork研发的云电脑AI助手
AI Agent 智能体 - Multi-Agent 架构入门
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
一文搞懂卷积神经网络经典架构-LeNet
一文搞懂深度学习中的池化!
厦门大学DeepSeek大模型助力高校企业政府发展 PDF文件 AI教程资料
RAG 不一定非得靠向量库:一套更偏工程落地的“结构化推理检索”方案
北京大学DeepSeek与AIGC应用PDF AI教程资料
开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
金灵AI深度体验报告 CSDN推出金融投研AI智能助手
AI精选