

人大高瓴AI与蚂蚁集团携手发布多模态大模型LLaDA-V
作者:互联网
2026-03-30
 ⼤语⾔模型脚本
⼤语⾔模型脚本
LLaDA-V作为前沿的多模态大语言模型,通过创新的扩散架构实现视觉与语言的高效融合,在多模态理解领域展现出卓越性能。
LLaDA-V是什么
这款由顶尖研究机构联合推出的多模态大语言模型采用纯扩散模型架构,专注于视觉指令微调技术。它在LLaDA框架基础上创新性地整合了视觉编码器与MLP连接器,成功将视觉特征映射到语言嵌入空间,实现了跨模态的高效对齐。其性能在多模态理解任务中表现突出,超越了当前主流的混合自回归-扩散和纯扩散模型。
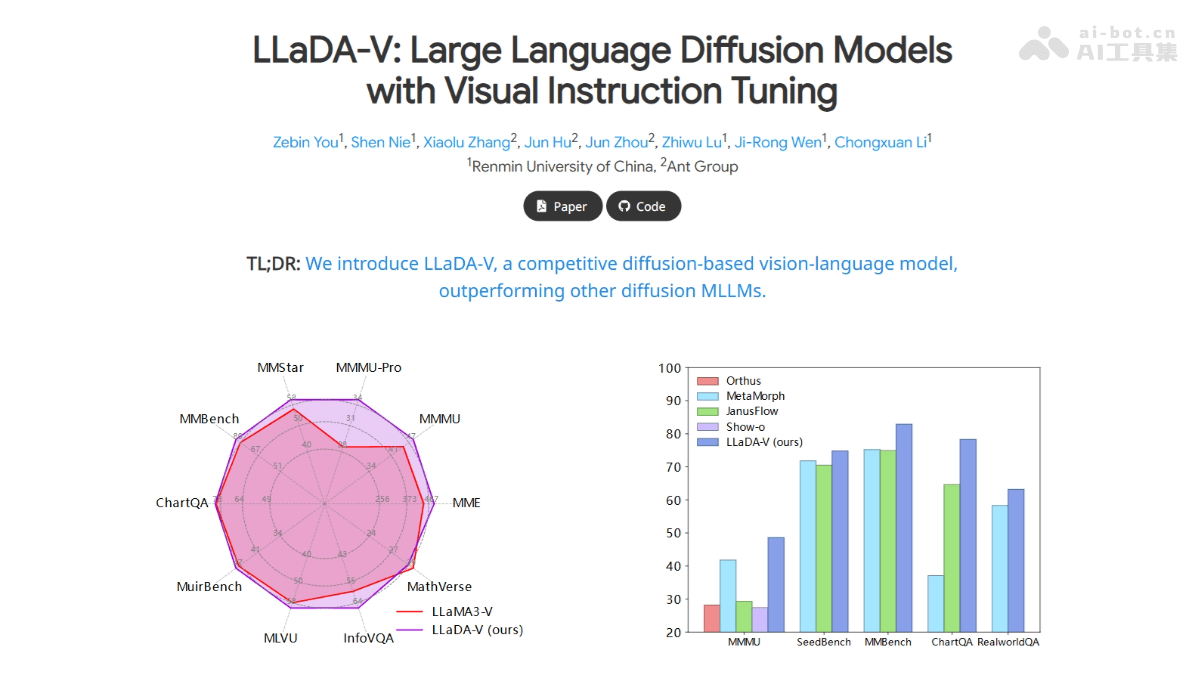
LLaDA-V的主要功能
- 图像描述生成:能够根据输入图像自动产生精准的文字描述。
- 视觉问答:可以准确回答与图像内容相关的各类问题。
- 多轮多模态对话:在图像语境下开展连贯对话,生成符合对话历史和图像内容的回答。
- 复杂推理任务:处理涉及图像与文本的复合型问题,包括数学运算和逻辑推理等。
LLaDA-V的技术原理
- 扩散模型技术:采用逐步去除噪声的数据生成方式,在模型中运用掩码扩散方法,通过预测被掩码词汇的原始内容进行训练。
- 视觉指令微调机制:通过视觉塔和MLP连接器的协同工作,SigLIP 2模型转换的视觉表示被映射到语言模型词嵌入空间,实现跨模态特征对齐。
- 多阶段训练方案:先训练MLP连接器实现特征对齐,再微调整体模型的视觉指令理解能力,最后强化多模态推理功能。
- 双向注意力架构:在多轮对话中通过双向注意力机制,确保模型能够综合考量整个对话上下文进行预测。
LLaDA-V的项目地址
- 项目官网:https://ml-gsai.github.io/LLaDA-V
- GitHub仓库:https://github.com/ML-GSAI/LLaDA-V
- arXiv技术论文:https://arxiv.org/pdf/2505.16933
LLaDA-V的应用场景
- 图像描述生成:为各类图像自动生成专业描述,辅助内容理解。
- 视觉问答系统:在教育、旅游等行业提供基于图像的智能问答服务。
- 多轮对话系统:赋能智能客服和虚拟助手实现多模态对话交互。
- 复杂推理应用:解决需要结合图像与文本的复合型推理问题。
- 多模态内容分析:适用于视频内容理解和监控场景的多图像分析。
LLaDA-V凭借其创新的技术架构和卓越的多模态处理能力,为人工智能领域的视觉语言融合应用开辟了新的可能性。
相关标签:
Diffusion
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
厦门大学DeepSeek大模型助力高校企业政府发展 PDF文件 AI教程资料
03/30
RAG 不一定非得靠向量库:一套更偏工程落地的“结构化推理检索”方案
03/30
北京大学DeepSeek与AIGC应用PDF AI教程资料
03/30
开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
03/30
金灵AI深度体验报告 CSDN推出金融投研AI智能助手
03/30
GSD 使用指南:高效交付功能的结构化工作流
03/30
AI精选