

AI如何实现自然语言处理NLP一文读懂
作者:互联网
2026-03-24
 ⼤语⾔模型脚本
⼤语⾔模型脚本
自然语言处理(NLP)作为人工智能的核心技术,正在深刻改变人机交互方式。本文将系统解析NLP的技术原理、关键方法及前沿应用,带您了解计算机如何实现语言理解与生成。
什么是自然语言处理?
自然语言处理(Natural Language Processing)是人工智能领域的重要分支,致力于让计算机具备处理人类语言的能力。其核心目标包括语言理解、生成与交互,通过融合计算语言学与机器学习技术,打破人机沟通障碍。
这项技术使数字设备能够识别文本语音的深层含义,并输出符合人类表达习惯的内容。从搜索引擎的智能建议到语音助手服务,从实时翻译到智能客服系统,NLP技术支撑着众多智能化应用场景。
NLP研究范围涵盖多个层次:基础层面的文本分析与信息抽取,高级应用如跨语言翻译与智能问答系统。该技术不仅需要解析文字表面含义,更要把握背后的情感倾向和真实意图。以智能客服为例,系统需准确理解用户问题,分析情绪状态,才能给出恰当回应。
NLP的独特价值在于综合把握语境、语义与情感等复杂因素,使计算机能真正理解并生成人类语言,实现自然高效的双向沟通。
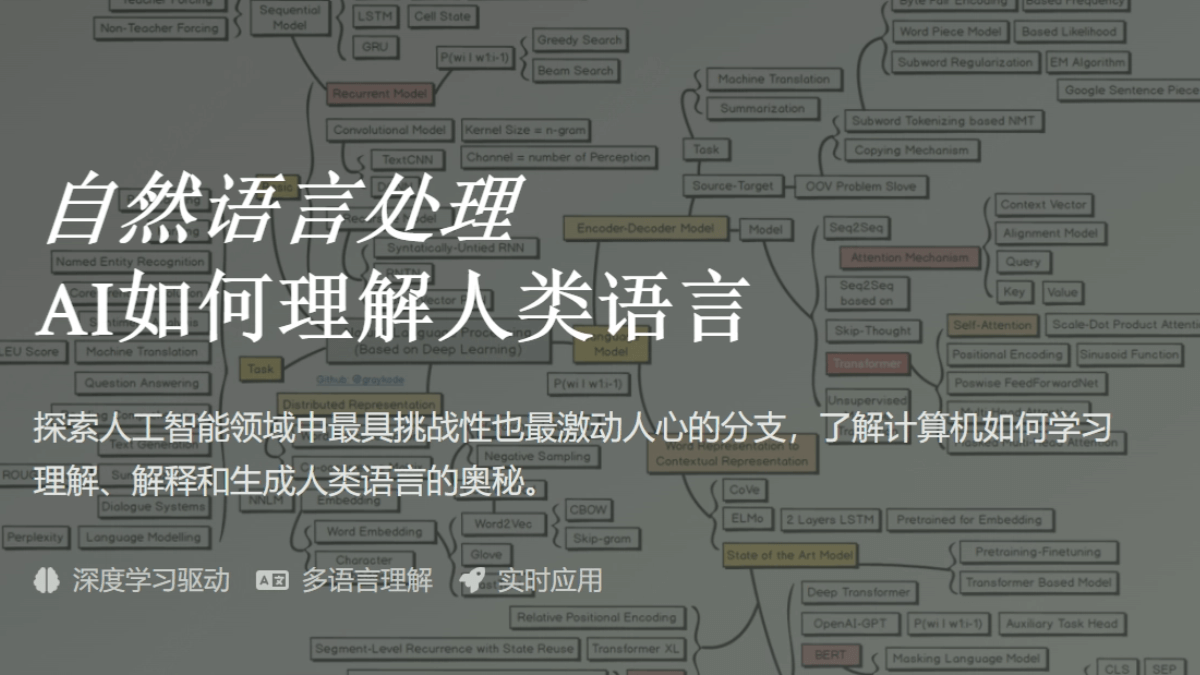
NLP的核心概念:理解语言的不同层面
词法分析:从单词入手
词法分析作为NLP的基础环节,专注于文本中最小的意义单元。其主要任务是将连续文本流切分为具有独立意义的词元(Token),并识别这些词元的各类属性。这一过程被称为分词(Tokenization)。
英文例句"I love NLP!"经分词可得["I","love","NLP","!"]。中文分词更具挑战性,如"我爱自然语言处理!"需切分为["我","爱","自然语言处理","!"]。分词精度直接影响后续处理效果。
词法分析还包含两个重要技术:词形还原(Lemmatization)将单词屈折形式还原为基本形态,如"running"→"run";词干提取(Stemming)则通过去除词缀获取词干,如"happiness"→"happi"。
词性标注(POS Tagging)为每个词元标记语法类别,如名词、动词等。例如"The quick brown fox jumps..."中"fox"标为名词,"jumps"标为动词。这项技术对理解句子结构至关重要。
命名实体识别(NER)识别特定意义的实体并分类,如"苹果公司于1976年创立"中,"苹果公司"标为机构,"1976年"标为日期。准确的分词和词性标注是高级NLP任务的基础。
句法分析:理解句子结构
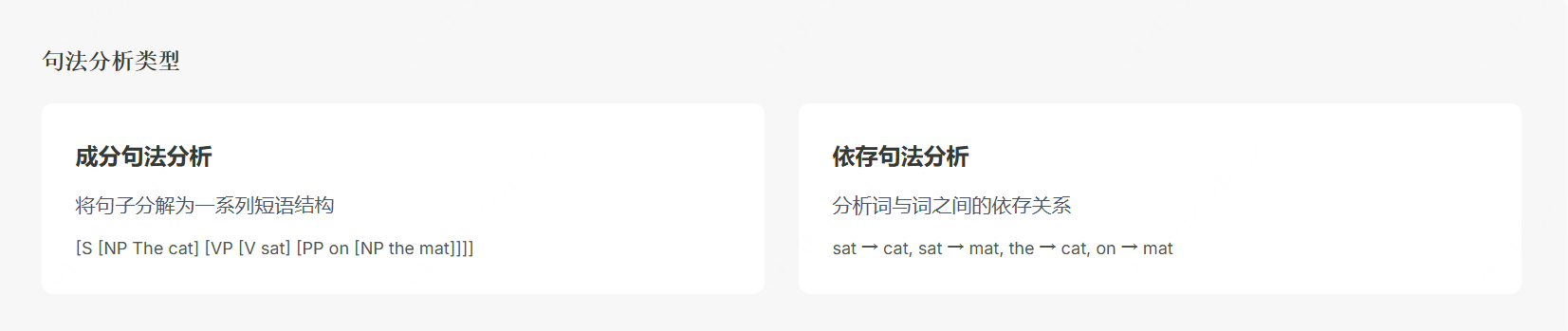
句法分析在词法分析基础上,进一步解析句子的语法结构,明确各成分间的关系。通过构建句法树或依存关系图,清晰展示主谓宾等成分的修饰关系。
分析"The cat sat on the mat"可知主语为"The cat",谓语是"sat","on the mat"为地点状语。理解句法结构对把握长难句含义尤为重要。
句法分析主要分为两类:成分句法分析将句子分解为名词短语等结构;依存句法分析则聚焦词间依存关系,如"She bought a red car"中"bought"为核心动词,"She"为主语,"car"为宾语,"red"修饰"car"。
语义分析:探究语言的含义
语义分析超越表面结构,深入探究语言表达的真实含义。其目标是将文本转化为结构化信息,涉及词义、语境等多维度的理解。
语义歧义是常见挑战,如"The bank is closed"中"bank"可指金融机构或河岸。语义分析需结合上下文消除歧义。主要技术包括:
语义角色标注分析"John gave Mary a book"中"John"为施事者,"Mary"为接受者,"book"为受事者。词嵌入技术如Word2Vec通过向量表示捕捉词语间的语义关联。
语用分析:理解语言的真实意图
语用分析作为最高层级的理解,关注特定语境下的真实意图。例如"It's cold here"可能隐含调高暖气的请求。涉及的核心概念包括:
- 言语行为理论:将说话视为行为,如承诺、指令等
- 会话含义:通过违反合作原则传递言外之意
- 指代消解:确定代词的具体指代对象
AI如何学习和处理语言
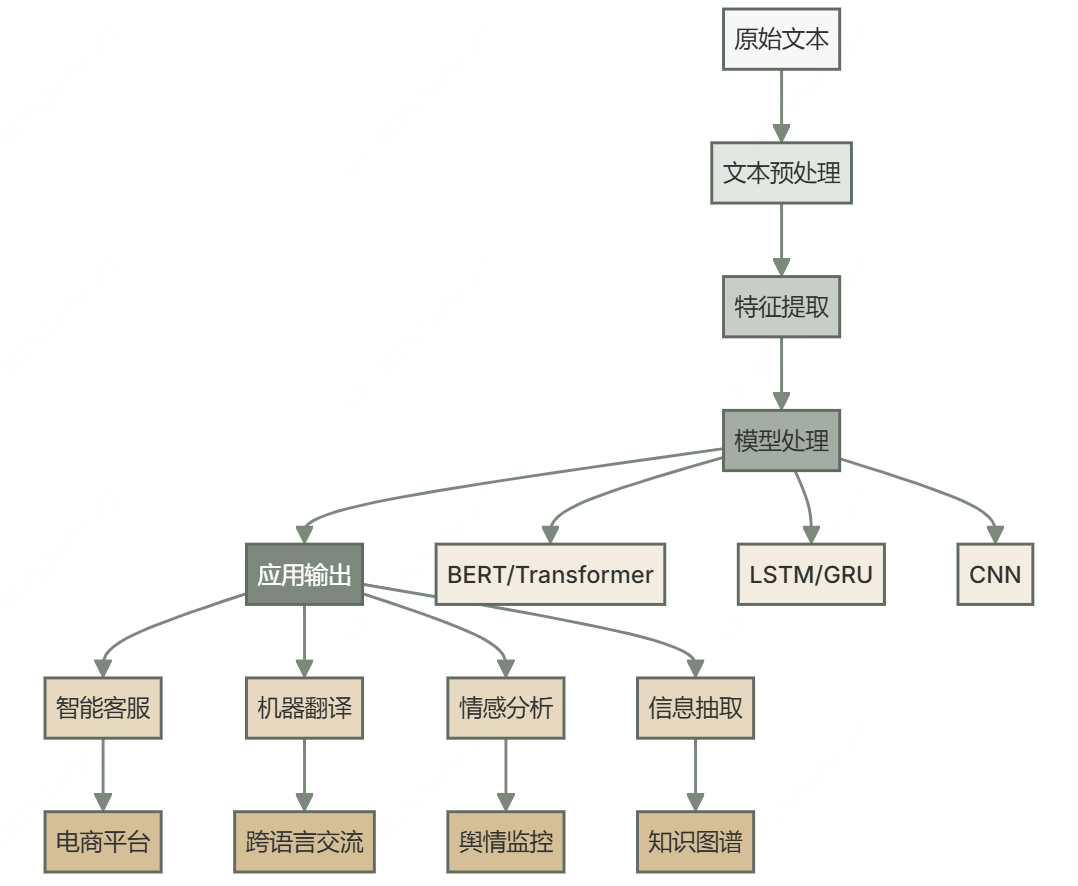
AI系统通过分析海量语料学习语言知识,其处理流程包含三个关键环节:
文本预处理:为分析做好准备
预处理将原始文本转化为规整格式,主要步骤包括:
- 文本清洗:去除无关字符与特殊符号
- 分词:切分连续文本为独立词元
- 去除停用词:过滤高频低信息量词汇
- 词形还原:统一词语的基本形式
- 拼写纠错:修正文本中的拼写错误
文本表示:将文字转化为机器可理解的形式
文本表示方法主要分为三类:
- 基于词频:如词袋模型(BoW)统计词频,TF-IDF评估词的重要性
- 基于词向量:Word2Vec等模型学习词语的分布式表示
- 基于上下文:BERT等模型生成上下文相关的词表示
语言模型:预测和生成文本
语言模型计算词序列概率,预测后续内容,是机器翻译等任务的基础。
NLP的关键技术:实现语言理解与生成
分词(Tokenization)
分词将连续字符切分为有意义的单元,中文分词尤为复杂。常用方法包括基于词典的匹配、统计模型及深度学习方法。
词性标注(Part-of-Speech Tagging)
为每个词语标注语法类别,如名词、动词等。主流方法包括规则标注、统计模型和深度学习。
命名实体识别(Named Entity Recognition, NER)
从文本中识别特定意义的实体并分类。深度学习方法在该任务上表现突出。
词嵌入(Word Embedding)与词向量
词嵌入技术将词语映射为稠密向量,Word2Vec和GloVe是典型代表。
机器翻译(Machine Translation)
历经基于规则、统计到神经网络翻译的演进,当前主流采用端到端的神经机器翻译。
情感分析(Sentiment Analysis)
识别文本中的情感倾向,应用于产品评价分析等场景。
语音识别与合成
实现语音与文本的相互转换,支撑智能语音交互。
NLP的主流模型与方法:从传统到深度学习
传统方法:基于规则和统计模型
早期主要依赖语言学规则和统计规律,如N-gram语言模型。
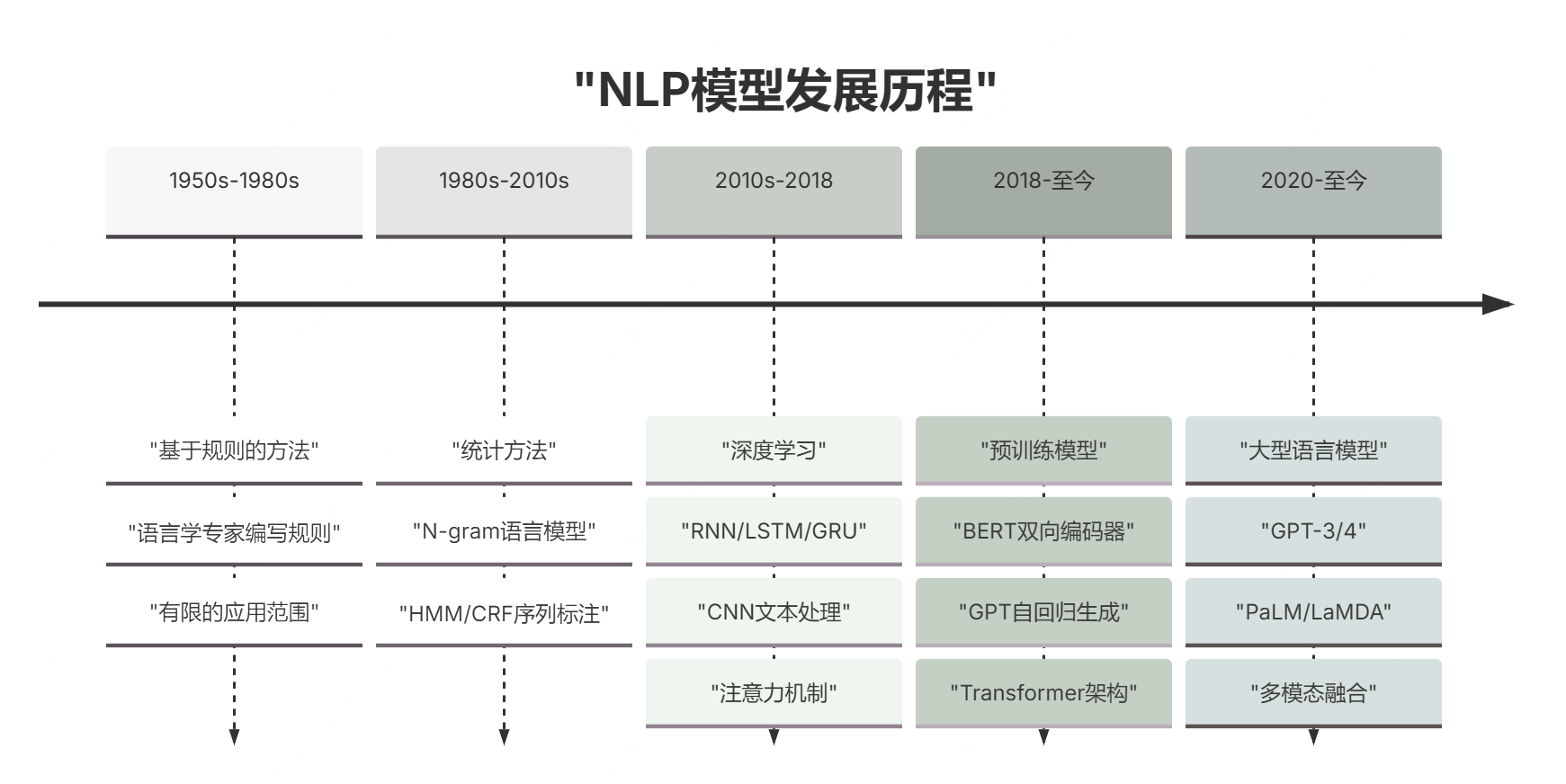
深度学习方法:神经网络的崛起
神经网络自动学习文本特征,显著提升处理效果。
预训练语言模型:BERT与GPT系列
BERT采用双向Transformer编码器,擅长文本理解;GPT基于解码器架构,专长文本生成。
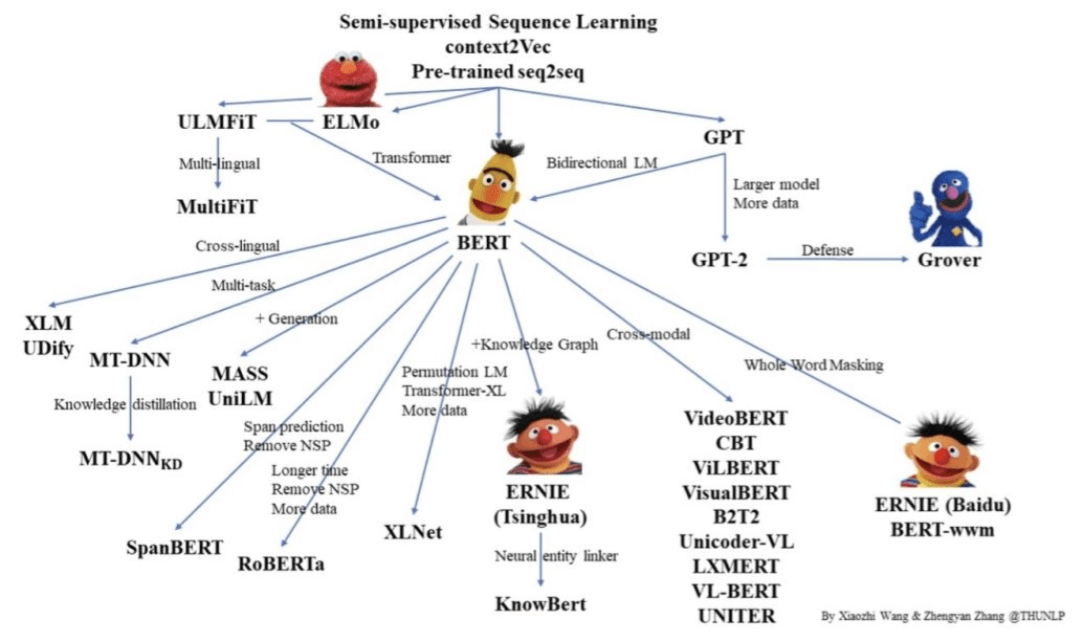
大型语言模型(LL
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
10款免费AI语音输入工具与软件 轻松实现语音转文字
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
SkyBot由Skywork研发的云电脑AI助手
AI Agent 智能体 - Multi-Agent 架构入门
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
一文搞懂卷积神经网络经典架构-LeNet
一文搞懂深度学习中的池化!
AI精选