

两个配置让 Codex 效率翻倍
作者:互联网
2026-04-14
 ⼤语⾔模型脚本
⼤语⾔模型脚本
两个配置让 Codex 效率翻倍
最近我把 Codex 的默认配置改了下,核心就两个:
- 开
fast模式,模型选GPT 5.4 - 给
GPT 5.4配1M上下文
就这两个,体感会明显顺很多。
1. 先说结论
fast 解决响应慢,1M context 解决长对话丢上下文。一个提速,一个减少重复解释,组合起来就是现在我最推荐的 Codex 默认配置:
GPT 5.4 + fast + 1M context
2. 配置一:开启 fast 模式 + GPT 5.4
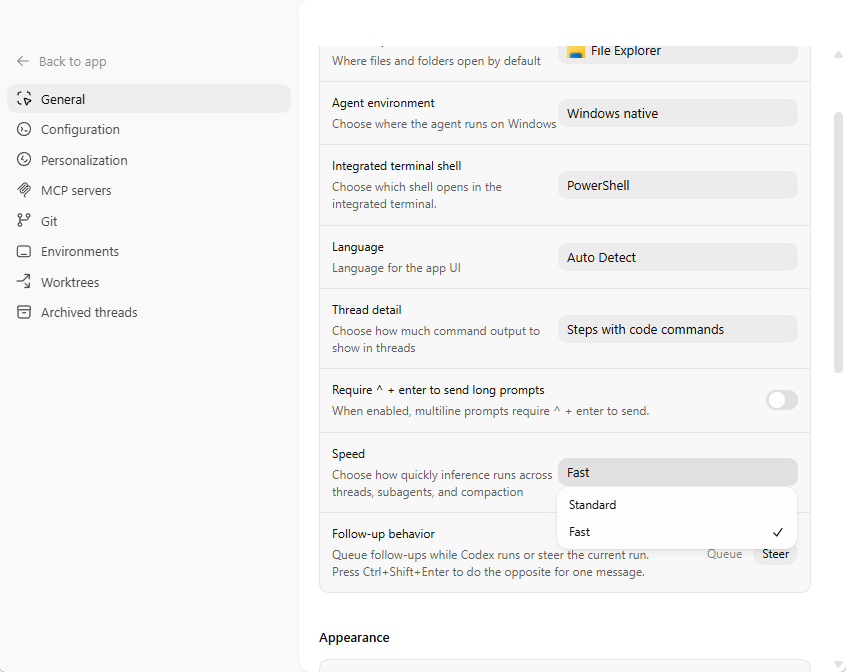
cli 在 terminal 输入 /fast

这一项建议直接当日常默认配置,一般就两步:
- 模型切到
GPT 5.4 - 推理模式切到
fast
这套配置的核心价值就是快。大多数日常任务,比如看代码、改代码、补命令、顺着报错继续查,真正拖效率的不是不会做,而是每一轮都慢半拍。GPT 5.4 + fast 基本就是我现在的主力档位。
3. 配置二:给 GPT 5.4 配 1M 上下文
model_context_window = 1050000 model_auto_compact_token_limit = 900000

第二个配置更简单,如果支持长上下文,直接给 GPT 5.4 配到 1M。
它解决的是长链路里的“失忆”问题。任务一长,前面看过的文件、说过的约束、已经确认的方案都更容易保住,不用你反复补背景,连续做事会稳很多。
相关标签:
相关推荐
2026-04-17
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
一天一个开源项目(第23篇):PageLM - 开源 AI 教育平台,把学习材料变成互动资源
开源大模型涨价策略分析:Llama 3.5 与 GLM-5 的商业化博弈
每周AI论文速递(260209-260213)
anthropic-academy:RAG检索增强生成
90%程序员还在让 AI 补代码,1%已经在指挥 AI 军团
# 从 0 到 1:**黎跃春**详解 AI 智能体运用工程师的工程化方法
Memo Code 安全设计:子进程、命令防护与权限审批的统一方案
Samba WINS 漏洞利用与防御全解析
拒绝“盲盒式”编程:规范驱动开发(SDD)如何重塑 AI 交付
ComfyUI 的缓存架构和实现
AI精选