

智谱AI发布新一代多模态大模型CogVLM2
作者:互联网
2026-03-22
 PPT
PPT
CogVLM2作为新一代多模态大模型,在视觉理解和语言处理方面取得重大突破,支持高分辨率图像与长文本输入,为多模态任务带来全新解决方案。
CogVLM2是什么
作为一款突破性的多模态大模型,CogVLM2在视觉与语言理解领域实现了质的飞跃。其创新之处在于支持8K超长文本输入和1344*1344像素的高清图像处理,特别擅长解析复杂文档图像。该模型采用独特的50亿参数视觉编码器与70亿参数视觉专家模块,通过深度融合技术实现视觉语言模态的完美协同。开源版本具备19亿参数规模,支持中英双语,实际推理时激活约120亿参数,在多模态任务中展现出卓越效率。

CogVLM2的改进点
相较于前代产品,CogVLM2在多个维度实现显著升级:
- 性能突破:关键指标全面提升,OCRbench测试性能提升32%,TextVQA提升21.9%,展现强劲实力。
- 文档解析:强化文档图像处理能力,在DocVQA基准测试中表现尤为突出。
- 高清支持:突破性支持1344*1344像素的高分辨率图像输入。
- 长文本处理:8K文本处理能力可应对复杂文档与深度语言任务。
- 双语能力:开源版本同时支持中英文,拓展多语言应用场景。
CogVLM2的模型信息
CogVLM2开源两款基于Meta-Llama-3-8B-Instruct的模型:cogvlm2-llama3-chat-19B(英文)和cogvlm2-llama3-chinese-chat-19B(中英双语),用户可通过主流平台获取体验。
| 模型名称 | cogvlm2-llama3-chat-19B | cogvlm2-llama3-chinese-chat-19B |
| 基座模型 | Meta-Llama-3-8B-Instruct | Meta-Llama-3-8B-Instruct |
| 语言 | 英文 | 中文、英文 |
| 模型大小 | 19B | 19B |
| 任务 | 图像理解,对话模型 | 图像理解,对话模型 |
| 模型链接 | ? Huggingface ? ModelScope ? GitHub | ? Huggingface ? ModelScope |
| 体验链接 | ? 官方页面 | ? 官方页面 ? ModelScope |
| Int4模型 | 暂未推出 | 暂未推出 |
| 文本长度 | 8K | 8K |
| 图片分辨率 | 1344 * 1344 | 1344 * 1344 |
CogVLM2的模型架构
CogVLM2采用创新架构设计,融合多项前沿技术:
- 视觉编码器:50亿参数规模,专业负责图像特征提取。
- 视觉专家模块:70亿参数模块精细建模视觉语言交互关系。
- 深度融合:突破性策略实现视觉语言模态的紧密协同。
- MLP适配器:有效调节跨模态特征匹配。
- 降采样模块:优化高分辨率图像处理,精炼关键信息。
- 词嵌入层:专业实现文本向量化转换。
- 多专家结构:智能激活约120亿参数,平衡性能与效率。
- 语言基座:采用Meta-Llama-3-8B-Instruct,奠定强大语言基础。

CogVLM2的模型性能
在TextVQA、DocVQA等多项基准测试中,CogVLM2以较小模型尺寸取得SOTA成绩,部分指标媲美GPT-4V等闭源模型。
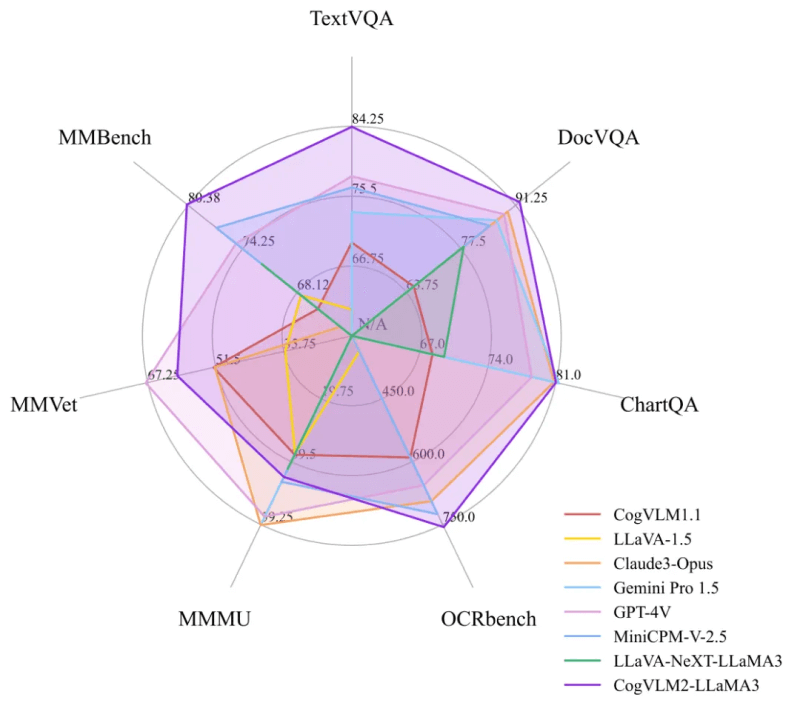
| 模型 | 是否开源 | 模型规模 | TextVQA | DocVQA | ChartQA | OCRbench | MMMU | MMVet | MMBench |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA-1.5 | ✅ | 13B | 61.3 | – | – | 337 | 37.0 | 35.4 | 67.7 |
| Mini-Gemini | ✅ | 34B | 74.1 | – | – | – | 48.0 | 59.3 | 80.6 |
| LLaVA-NeXT-LLaMA3 | ✅ | 8B | – | 78.2 | 69.5 | – | 41.7 | – | 72.1 |
| LLaVA-NeXT-110B | ✅ | 110B | – | 85.7 | 79.7 | – | 49.1 | – | 80.5 |
| InternVL-1.5 | ✅ | 20B | 80.6 |
