

ClaudeOpus4.6-Anthropic发布新一代编程AI模型
作者:互联网
2026-03-22
 Excel
Excel
Claude Opus 4.6作为人工智能领域的重大突破,不仅扩展了上下文处理能力,更在多项专业测试中展现了卓越性能。这款旗舰模型正在重新定义AI技术的应用边界。
Claude Opus 4.6是什么
Anthropic最新发布的Claude Opus 4.6作为4.5版本的升级款,带来了多项突破性改进。该模型率先实现100万token上下文窗口支持,在编程、逻辑推理等复杂任务领域表现突出。Terminal-Bench 2.0和Humanity's Last Exam等权威测试中,其GDPval-AA评分较GPT-5.2高出144个Elo分。创新性的自适应思考机制和上下文压缩功能,使其能够独立完成财务分析、代码审查等高难度工作,标志着AI向自主智能体方向的重要演进。
Claude Opus 4.6的主要功能
- 超长上下文处理:100万token的上下文窗口在MRCR v2测试中获得76%准确率,远超前代18.5%的表现,有效解决上下文信息衰减问题。
- 自适应思考机制:系统能智能判断任务难度,提供low至max四档思考强度选项,帮助用户在响应速度与处理质量间取得平衡。
- 上下文压缩技术:自动将历史对话内容压缩为摘要,为新任务腾出处理空间,确保长时间作业不会因上下文溢出而中断。
- 企业级工作能力:在GDPval-AA测试中以1606分领先GPT-5.2,可独立完成财务分析、法律研究等专业工作。
- 编程与代码审查:Terminal-Bench 2.0编码评估中表现最佳,具备多语言开发、大型代码库维护等专业编程能力。
- 联网信息检索:BrowseComp测试成绩84%,结合超长上下文窗口,可高效处理海量网络信息。
- 办公套件集成:通过专用插件深度集成Excel和PowerPoint,支持数据透视表编辑、幻灯片母版读取等高级功能。
- 安全性与对齐性:在行为审计中展现出优异的安全特性,误导率和谄媚率均处于行业领先水平。
Claude Opus 4.6的性能表现
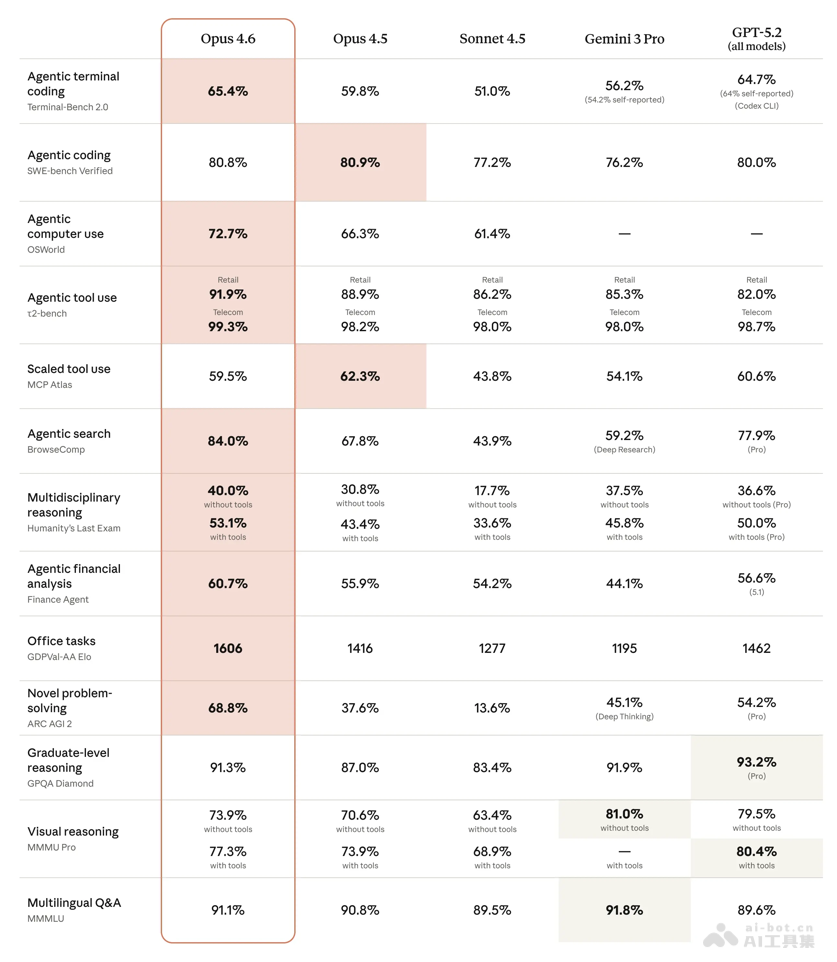
- Terminal-Bench 2.0智能体编码评估:以65.4%的成绩位居所有模型之首。
- Humanity's Last Exam多学科推理测试:在所有前沿模型中保持领先优势。
- GDPval-AA真实知识工作评估:1606分的Elo评分较GPT-5.2高出144分。
- BrowseComp网络检索测试:84%的准确率优于GPT-5.2 Pro的77.9%。
- ARC AGI 2流体智力测试:68.8%的成绩远超GPT-5.2 Pro的50%。
- OSWorld计算机操作测试:72.7%的表现较前代66.3%有明显提升。
- MRCR v2长上下文检索:100万token版本76%的准确率远超Sonnet 4.5的18.5%。
- SWE-bench Verified代码修复:经25次试验平均达到80.8%,优化后可达81.42%。
如何使用Claude Opus 4.6
- 网页端访问:直接登录平台即可使用最新版本,无需额外配置。
- API调用:开发者可通过claude-opus-4-6名称进行接口调用。
- Claude Code集成:安装后支持命令行操作,使用/effort参数调整思考强度。
Claude Opus 4.6的应用场景
- 软件开发:适用于大型代码库审查维护,支持多语言开发环境。
- 代码调试:可自动定位问题并生成修复方案,提升开发效率。
- 持续工作流:在复杂工程任务中保持长时间自主运行。
- 财务分析:执行复杂财务建模,快速生成专业分析报告。
- 法律审查:借助超长上下文处理大规模法律文档。
从技术突破到实际应用,Claude Opus 4.6展现了人工智能处理复杂任务的强大潜力,为各行业智能化转型提供了可靠的技术支持。
相关标签:
办公自动化脚本
相关推荐
