

把RAG融入模型,开源MSA记住1亿Token实现永久记忆
作者:互联网
2026-04-15
 AI快讯
AI快讯
人类大脑能存储约2-3亿token的终身记忆,但现有大模型却被困在128K-1M token的牢笼里。论文指出,当前三大技术路线各有硬伤:
参数记忆(如LoRA):容量受限,容易"灾难性遗忘"外部存储(如RAG):检索与生成分离,精度天花板低线性注意力(如RWKV):固定状态压缩,长文本精度暴跌MSA瞄准的正是这个空白地带:既要端到端可训练,又要能无损扩展到人类级别的记忆容量。
方案亮点
1. 核心架构设计
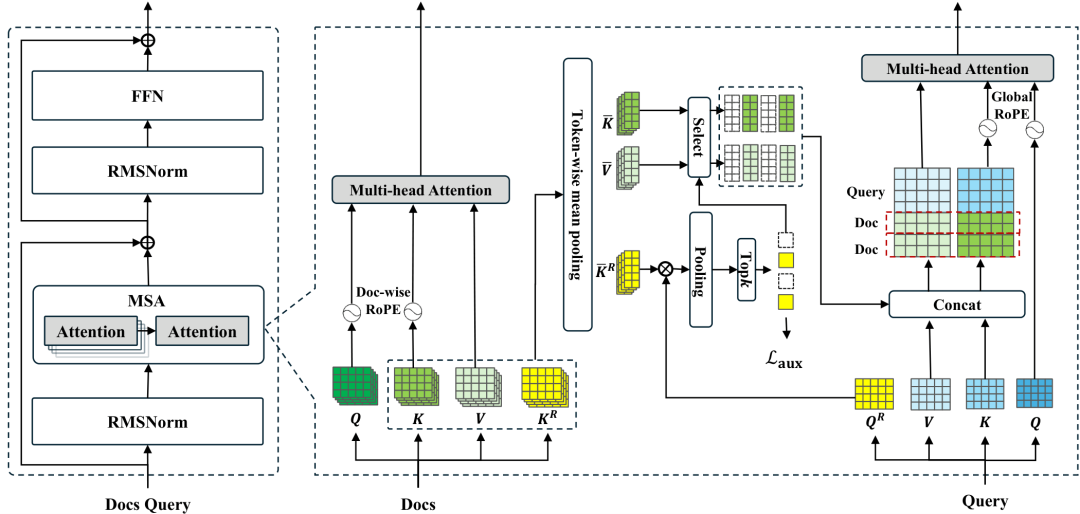
MSA的核心是文档级稀疏注意力机制。工作原理很巧妙:
将海量文档库切分为固定长度的块通过专门的Router Projector生成路由键值,计算查询与文档块的相关性分数只选取Top-k最相关的文档参与注意力计算其余文档的KV缓存保持压缩状态,大幅降低计算开销2. 文档级RoPE:破解位置编码困局
传统全局位置编码在长文本场景会"位置漂移"——训练时见过的位置少,推理时位置ID暴增导致性能崩盘。
MSA的解决方案是Parallel RoPE:每个文档独立编号(都从0开始),查询部分则用Global RoPE承接。这样模型在64K上下文上训练,却能无损外推到1亿token。
3. Memory Interleave:多跳推理神器
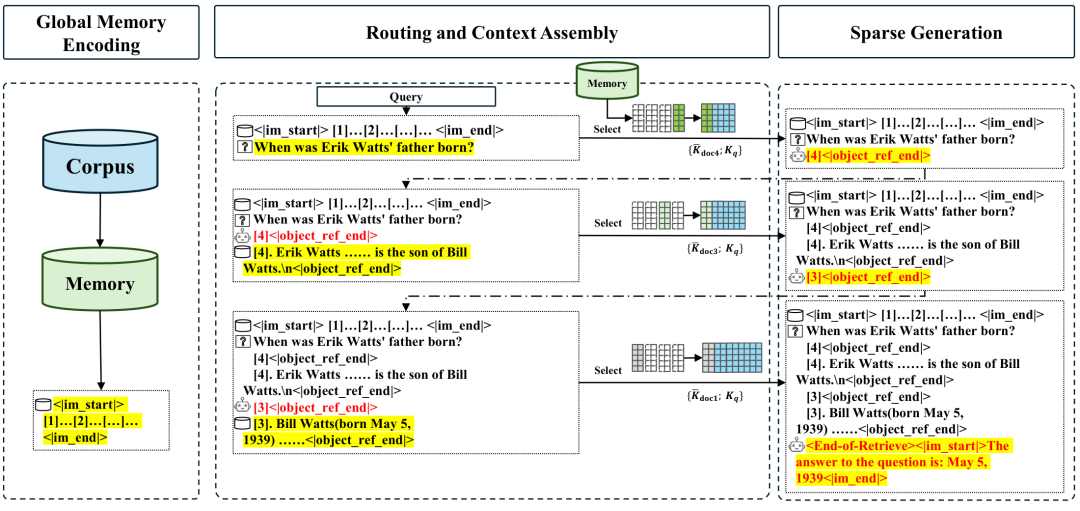
复杂问题往往需要跨文档找线索。MSA的记忆交错机制让模型能迭代检索:
第一轮:根据问题检索相关文档ID将检索到的内容追加到查询中第二轮:基于更新后的查询继续检索直到模型判断证据充足,才输出最终答案实验结果
双卡跑1亿token
论文展示了惊人的工程优化:
Memory Parallel策略:
路由键(Router Keys)常驻GPU显存(约56GB)内容KV缓存放在CPU内存(约113GB)检索时多卡并行打分,只把选中的文档KV异步加载到GPU最终效果:2张A800显卡就能处理1亿token的推理,KV缓存压缩后存储需求降低64倍。
精度几乎不掉线
在MS MARCO长文本问答基准上,MSA-4B展现出恐怖的稳定性:
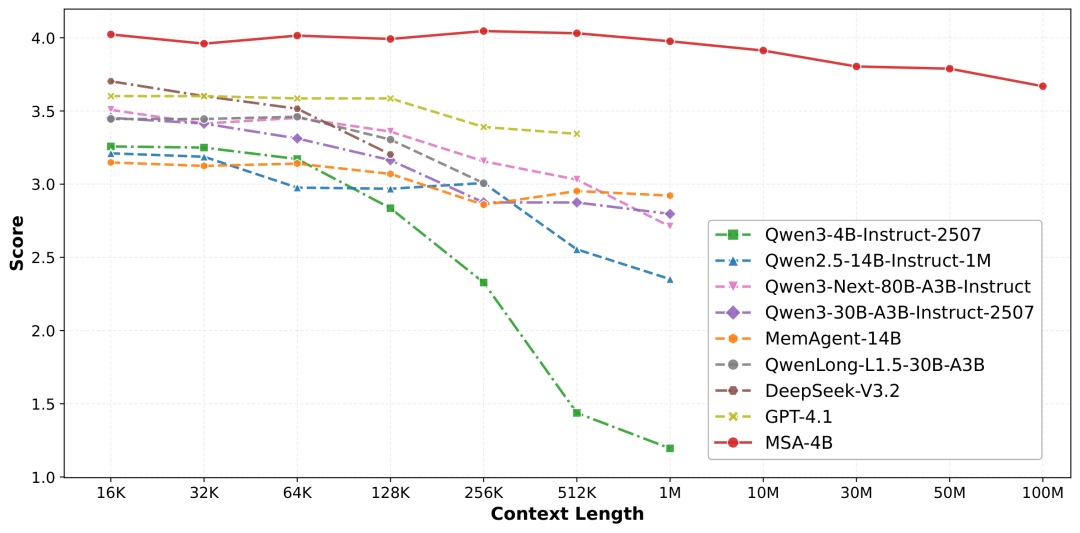
更关键的是,MSA不需要RAG那套复杂的召回策略和超参数调优,端到端训练让检索和生成真正统一。
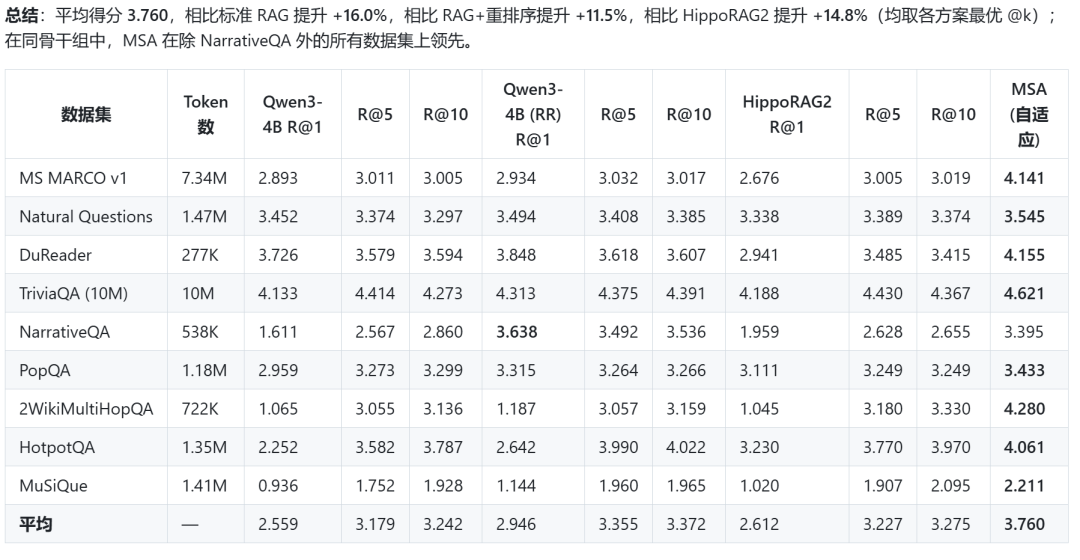
MSA的价值在于解耦了记忆容量与推理能力——用稀疏注意力处理海量记忆,用标准Transformer做精密的逐步推理。
对于需要终身记忆的应用场景(数字孪生、长篇小说理解、多智能体长期协作),这可能就是从"玩具Demo"到"可用产品"的关键一跃。
MSA: Memory Sparse Attention for Efficient End-to-End Memory Model Scaling to 100M Tokens
https://arxiv.org/pdf/2603.23516
https://github.com/EverMind-AI/MSA
PaperAgent开源社区上线了(持续更新):
https://docs.qq.com/aio/DUFpMUmNNamZQS3VH本文转载自PaperAGI 作者:Paper小AI
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
阿里云大模型服务平台百炼新人免费额度如何申请?申请与使用免费额度教程及常见问题解答
办公 AI 工具 OpenClaw 部署 Windows 系统一站式教程
Qwen3.6 正式发布!阿里云百炼同步开启“AI大模型节省计划”超值优惠
【新手零难度操作 】OpenClaw 2.6.4 安装误区规避与快速使用指南(包含最新版安装包)
OpenClaw 2.6.4 可视化部署 打造个人 AI 数字员工(包含最新版安装包)
【小白友好!】OpenClaw 2.6.4 本地 AI 智能体快速搭建教程(内有安装包)
零基础部署 OpenClaw v2.6.2,Windows 系统完整教程
【适合新手的】零基础部署 OpenClaw 自动化工具教程
开发者们的第一台自主进化的“爱马仕”来了
极简部署 OpenClaw 2.6.2 本地 AI 智能体快速启用(含最新版安装包)
AI精选