

RAG当主力,MemPalace把记忆准确率干到 96.6%,token 成本为0
作者:互联网
2026-04-14
 AI快讯
AI快讯
最近在处理一个老项目的代码时,我突然意识到一个问题:我和 Claude 讨论过这个架构决策,但具体为什么选方案 A 而不是方案 B,完全想不起来了。翻了半天聊天记录,发现那已经是三个月前的对话,早就淹没在无数会话窗口里。
这种「我记得我们聊过,但忘了细节」的场景,相信用过 AI 编程助手的人都懂。每次新开一个对话,AI 就像失忆了一样,之前的讨论、决策、踩过的坑,全部清零。
所以我一直在找一个靠谱的 AI 记忆方案。试了几个现有的工具,要么需要把数据传到云端,要么准确率不够,要么成本太高。直到我发现了 MemPalace。
它解决了什么问题
MemPalace 的核心定位很清晰:让你的 AI 记住你们之间的每一次对话,而且完全本地化、零成本。
它解决的是 AI 助手最大的痛点——会话即焚。你和 Claude、ChatGPT、Cursor 讨论的每一个架构决策、每一个调试过程、每一个被否决的方案,默认情况下都会随着会话结束而消失。六个月的高强度使用,可能积累了近 2000 万 token 的宝贵上下文,但你能用的只有当前窗口里的几千 token。
现有的解决方案主要有两类:
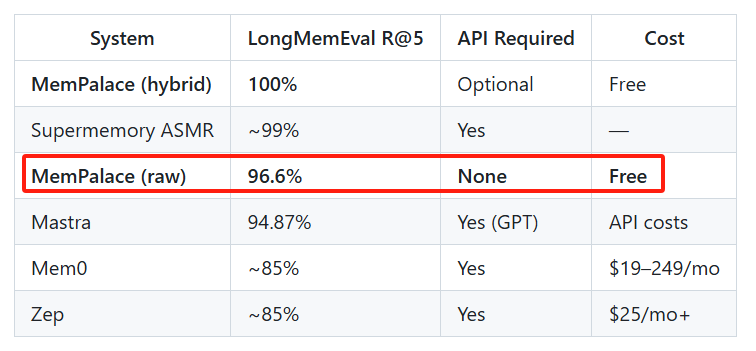
第一类是云端记忆服务,比如 Mem0、Zep。它们帮你存储和检索历史对话,但需要订阅费($19-249/月),而且你的数据要上传到别人的服务器。
第二类是本地摘要方案,用 LLM 把历史对话总结成关键要点。但问题是,总结会丢失上下文。AI 记住了「你选了 Postgres」,但忘了「当时为什么没选 MySQL」的具体讨论过程。
MemPalace 走了第三条路:本地存储 + 原始文本检索 + 结构化组织。
我的使用场景
我实际用 MemPalace 跑了一周,说几个让我印象深刻的场景。
场景一:找回三个月前的架构决策
我最近在重构一个微服务模块,隐约记得之前和 Claude 讨论过接口设计。用 MemPalace 搜索「为什么用 REST 而不是 gRPC」,直接返回了当时的完整对话片段:
> "Chose REST over gRPC because the team is more familiar with HTTP semantics, and we don't need the streaming capabilities yet. Decided 2025-11-03."
不只是结论,还有当时的推理过程。这让我避免了一次重复讨论——之前我们确实考虑过 gRPC,但基于团队熟悉度和需求优先级否决了。
场景二:跨项目的经验复用
我同时在维护三个项目。上周在 Project A 里解决了一个关于 JWT 刷新 token 的边界 case,这周在 Project B 又遇到了类似问题。
MemPalace 的「宫殿结构」允许我给不同项目分配不同的 wing(翼楼)。搜索「JWT refresh」时,它不仅能找到当前项目的结果,还能提示我:「你在 Project A 的 auth-migration 房间有过相关讨论,要看看吗?」
这种跨项目的知识关联,是简单的关键词搜索做不到的。
场景三:零成本的事实核查
团队里有人问我:「当时是谁决定用 Clerk 做认证的?」
我直接用 MemPalace 搜索「Clerk decision」,得到:
> "Kai recommended Clerk over Auth0 — pricing + developer experience. Team agreed 2026-01-15. Maya handling the migration."
有决策人、有对比理由、有时间点。而且整个查询过程没有调用任何 LLM API,纯本地的向量检索,成本为 0。
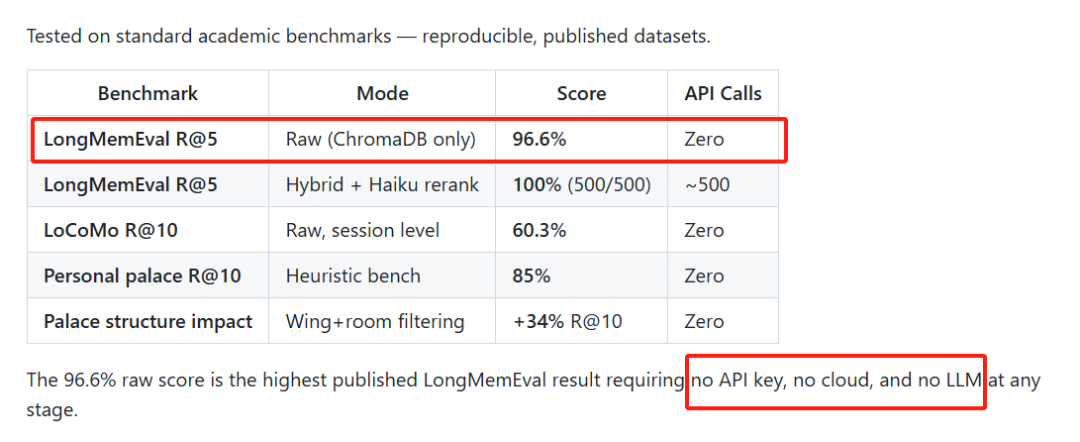
为什么它能做到 96.6% 的准确率
MemPalace 在 LongMemEval 基准测试上拿到了 96.6% 的 R@5 分数,这是目前公开的最高分,而且是零 API 调用的情况下实现的。
它的设计有几个关键差异点:
1. 原始文本存储,不做 LLM 摘要
其他方案倾向于用 LLM 提取「关键记忆」,但 MemPalace 选择存储完整的对话原文。这意味着你检索到的是当时的原话,而不是被压缩后的二手信息。
2. 宫殿结构:Wing → Room → Closet → Drawer
这是 MemPalace 最有意思的设计。它借鉴了古希腊的「记忆宫殿」技巧:
Wing(翼楼):代表一个人或一个项目Room(房间):具体的话题,比如 auth-migration、graphql-switchHall(大厅):连接同一翼楼内的相关房间Tunnel(隧道):连接不同翼楼的相同话题Closet(壁橱):指向原始内容的摘要Drawer(抽屉):存储原始文件的精确文本这种结构化的组织方式,让检索准确率比无过滤搜索提升了 34%。当你搜索「auth」相关的内容时,MemPalace 知道该去哪个翼楼、哪个房间找,而不是在全量文本里盲目匹配。
3. 四层记忆栈
MemPalace 把记忆分成四层加载:
L0(身份层):AI 是谁,约 50 token,始终加载L1(关键事实):团队、项目、偏好,约 120 token,始终加载L2(房间回忆):近期会话、当前项目,按需加载L3(深度搜索):跨所有内容的语义查询,按需触发这意味着 AI 每次「醒来」只需要加载约 170 token 就能了解你的世界,需要时才去搜索更多内容。
局限和适用边界
当然,MemPalace 也不是万能的。
首先,它需要前置的数据整理。你需要把历史对话导出、整理成特定格式,然后用 mempalace mine 命令导入。对于已经有大量分散聊天记录的用户,这个整理成本不低。
其次,它是为「回顾」设计的,不是为「实时学习」。它擅长回答「我们之前是怎么决定的」,但不擅长让 AI 在对话中实时记住你刚说的偏好。后者还是需要依赖 AI 产品本身的记忆功能。
最后,AAAK 压缩方案还在实验阶段。虽然作者宣传了 30x 压缩的概念,但实际测试显示在小文本上反而会增加 token 数,且会降低检索准确率。目前建议用 raw 模式。
总结
MemPalace 给我最大的启发是:AI 记忆不一定要靠 LLM 总结,好的结构化组织 + 向量检索,可以在零成本的情况下达到很高的准确率。
https://github.com/milla-jovovich/mempalace
PaperAgent开源社区上线啦(持续更新):
https://docs.qq.com/aio/DUFpMUmNNamZQS3VH本文转载自PaperAGI 作者:Paper小AI
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
可计算元认知:工程实现与封装说明——跨领域、跨语言文本对齐的开源工具箱
2026 最新版 OpenClaw 部署指南:Windows 一键安装,新手也能轻松上手
2026 最新版 OpenClaw,一键汉化安装,无捆绑无弹窗(包含新安装包)
阿里云计算巢搭建OpenClaw、配置百炼Coding Plan、接入WhatsApp保姆级图文教程
深度解析商场智能试妆镜的腮红渲染协议
真心推荐!2026 最新版 OpenClaw,小白装完都夸香(包含新安装包)
跳出 SOTA 内卷,我们发了个“好用至上”的文档解析模型
花了几百万办完一场AI大会后,想跟你分享这6个感悟
预测你的职业什么时候被替代,还有突围建议!
猛料:硅谷企业们正大量采用中国开源模型!
AI精选