

LLM连均匀分布都采不好,还怎么当Agent?
作者:互联网
2026-04-16
 AI快讯
AI快讯
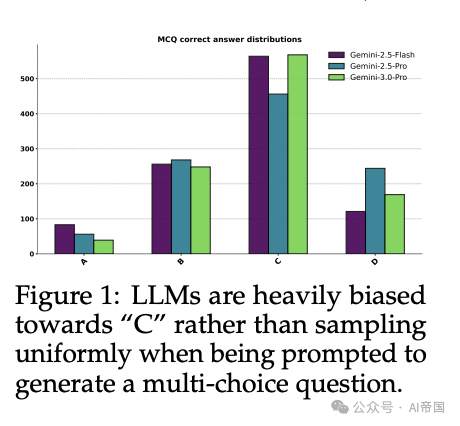
让Gemini系列模型生成一道选择题,要求随机安排正确答案的位置(A/B/C/D四个选项)。结果呢?模型表现出对"C"选项的强烈偏好,远非均匀分布。 这个看似简单的任务,暴露了当前大语言模型一个被严重低估的根本缺陷:它们无法可靠地从指定的概率分布中进行随机采样。
 图片
图片
[Figure 1: LLM在生成选择题时严重偏向"C"而非均匀采样]论文对Gemini-2.5-Flash、Gemini-2.5-Pro、Gemini-3.0-Pro进行测试,要求生成选择题并随机放置正确答案,结果显示模型对"C"位置存在显著偏好。
这篇来自Google DeepMind和新加坡国立大学的工作,系统性地揭示了这一问题:LLM输出的随机性只是一种"幻觉"——它们看起来在随机行动,实际上受训练数据偏差驱动,而非遵循目标分布。
为什么Agent必须会"掷骰子"
当LLM被部署为与环境交互的agent时,它不仅需要推断最优策略,还需要按照策略进行随机行动。此前研究发现LLM在多臂老虎机、Tic-Tac-Toe等任务中缺乏探索能力,即便推理正确也无法执行,这被称为"knowing-doing gap"。论文提出,这一差距的一个潜在根源在于:即使模型知道正确的策略,按该策略进行随机采样对LLM来说本身就是非平凡的。 因为LLM的采样机制作用于token层面的词表概率,而非语义动作空间——例如"向左走"和"向右走"共享相同的首token,连续分布(如高斯分布)的映射就更加困难。
全面的失败:多模型、多分布、多方法
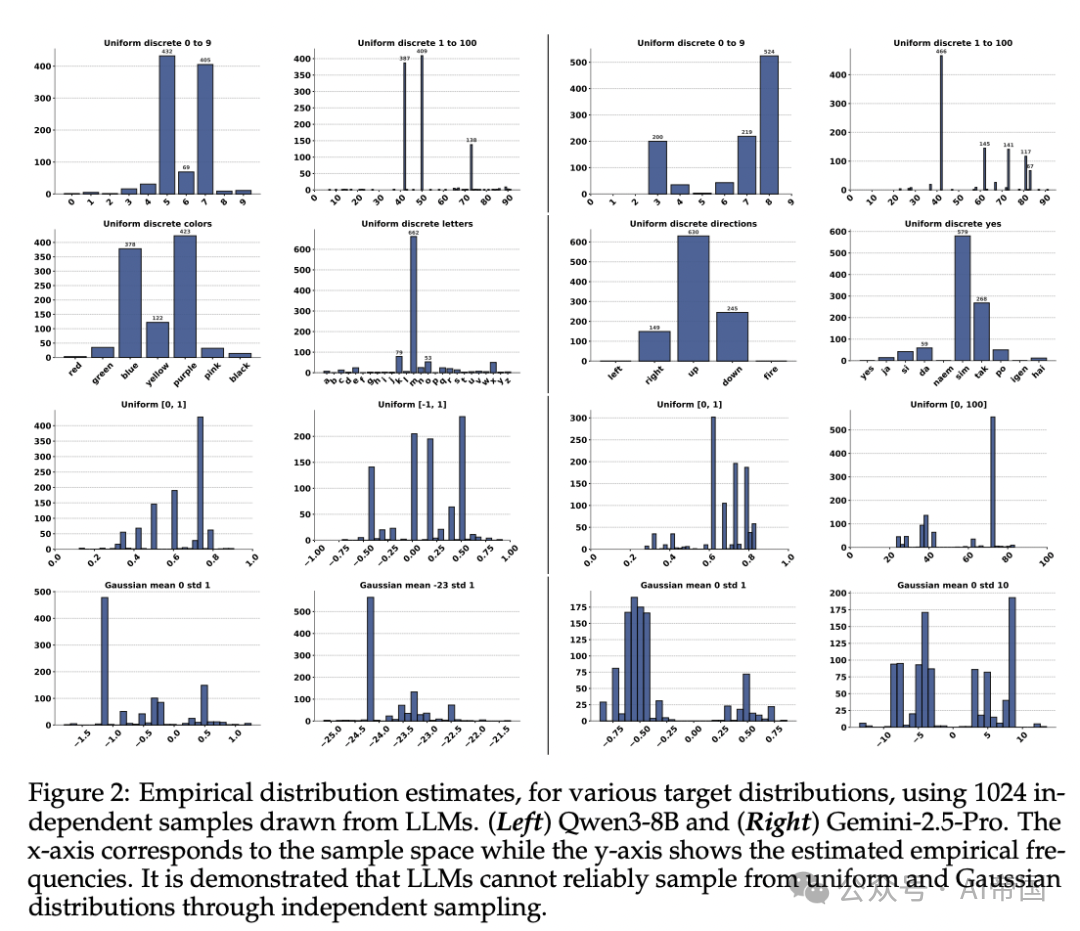
论文在Gemini(包括2.5-Flash、2.5-Pro、3.0-Pro)和Qwen3(包括8B、32B等多个尺寸)等多个模型族上进行了系统实验,测试了均匀离散分布、均匀连续分布和高斯分布三类场景。每次独立调用LLM生成一个样本,重复N=1024次后统计经验分布。
 图片
图片
[Figure 2: 多种目标分布下LLM独立采样的经验分布] 左侧为Qwen3-8B,右侧为Gemini-2.5-Pro。结果显示LLM在离散分布中偏好特定数字(如7、42),在连续分布中偏好特定区间,无法逼近目标分布。
 图片
图片
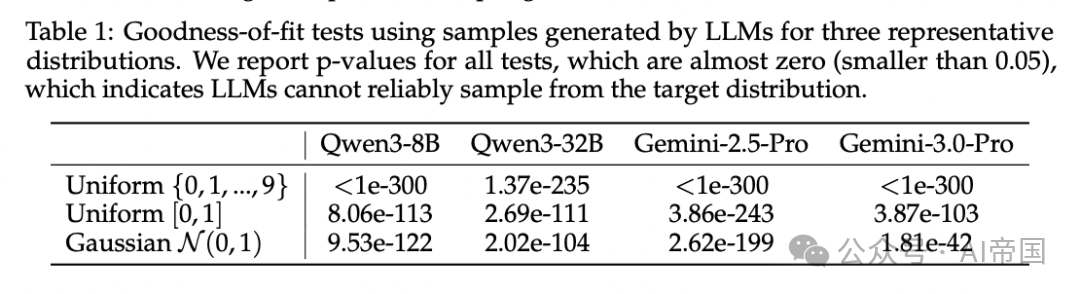
[Table 1: 拟合优度检验的p值] 对均匀离散{0,...,9}、均匀连续[0,1]、高斯N(0,1)三种分布,四个模型(Qwen3-8B/32B、Gemini-2.5-Pro/3.0-Pro)的p值几乎全部小于1e-42,远低于0.05的显著性阈值,量化确认了采样失败。
关键发现是:使用更大或更先进的模型(如Qwen3-32B、Gemini-3.0-Pro)并不能修复这一问题。 论文还发现偏差不仅是语义层面的(比如偏好数字42和7),还存在位置偏差——当提示中随机集合的排列顺序改变时,模型的偏好也会随之改变。
调参也救不了
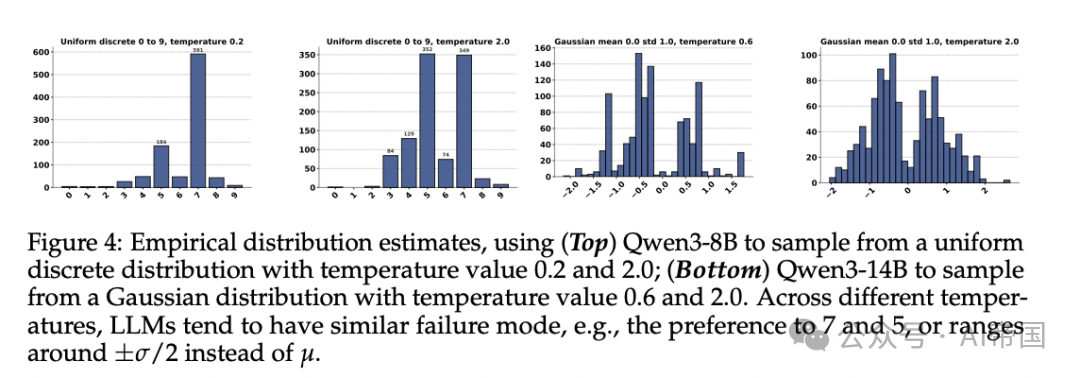
论文对解码参数进行了详细消融实验,包括temperature从0.0到2.0、top-p从0.1到1.0、top-k从10到10000等。结果是:p值在所有配置下始终接近零,即使将temperature提升到极高值(2.5至10.0),虽然经验分布看起来稍微接近目标,但p值仍显著小于0.05,且模型开始出现严重的解析错误。
 图片
图片
[Figure 4: 不同temperature下的采样分布] 论文展示Qwen3-8B和Qwen3-14B在不同temperature设置下的采样结果,发现模型在不同温度下倾向于陷入相似的失败模式,如对数字7和5的偏好。
论文还测试了关闭思维链(chain-of-thought)的效果。结果表明,即便去除冗长的推理过程,LLM仍然无法可靠采样,某些情况下偏差反而被放大。
序列采样和批量采样:各有各的问题
受伪随机数生成器(PRNG, Pseudo-Random Number Generator, 伪随机数生成器)有状态性的启发,论文探索了将历史样本放入上下文的序列采样方法。携带全部历史的序列采样在均匀分布上表现尚可,但引入了明显的时间偏差——自相关分析显示模型倾向于"排斥"当前状态,即偏好跳到不同的值。
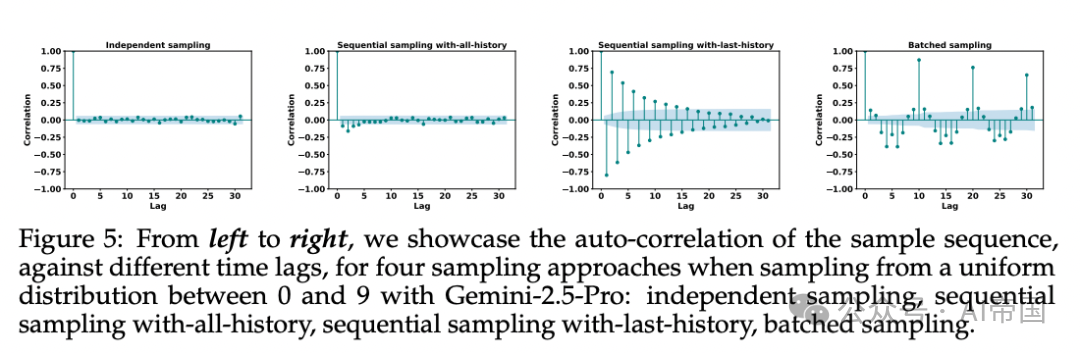 图片
图片
[Figure 5: 四种采样方式的自相关函数对比] 独立采样、全历史序列采样、末位历史序列采样、批量采样的自相关分析。全历史方式虽表现较好,但前几个lag呈负相关,显示排斥效应;末位历史方式则展现强烈的周期性模式。
批量采样(一次生成1024个数)在均匀分布上偶尔可行,但引入了严重的周期性重复模式,且模型难以精确生成指定数量的随机数。
真正有效的方案:分布转换
论文最重要的正面发现来自分布转换实验。方法很简单:不让LLM自己"生成"随机数,而是向其提供一个从均匀分布[0,1]中预采样的随机数,让模型通过确定性算法将其转换到目标分布。
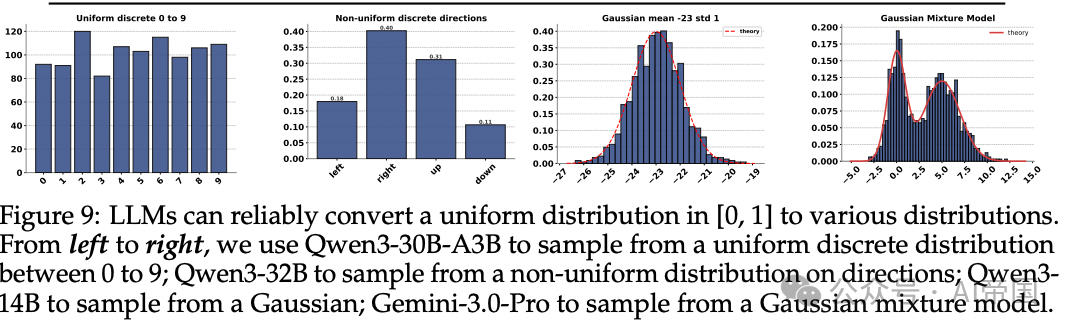 图片
图片
[Figure 9: LLM可靠地将均匀分布转换为多种目标分布] 从左到右展示了Qwen3-30B-A3B转换到均匀离散分布、Qwen3-32B转换到非均匀离散分布、Qwen3-14B转换到高斯分布、Gemini-3.0-Pro转换到高斯混合模型的结果,均与理论曲线吻合。
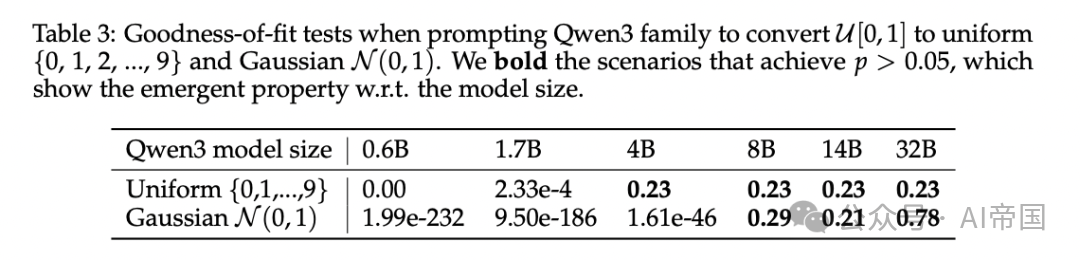 图片
图片
[Table 3: 不同Qwen3模型尺寸的分布转换拟合优度检验] 论文在Qwen3的0.6B到32B六个尺寸上测试。对均匀离散分布,4B及以上模型达到p>0.05;对高斯分布,8B及以上模型达到p>0.05,展现出随模型规模增长的涌现特性。
LLM在这一任务中的推理过程完全是确定性的:对离散分布使用分桶算法,对高斯分布使用逆变换采样。这说明失败的根源不在于LLM不理解目标分布,而在于它们无法将内部概率估计映射到随机输出上。
模拟PRNG:能力与局限
论文还测试了让LLM在不使用工具的情况下,通过思维链模拟PRNG算法。对均匀分布,Qwen3-4B及以上模型的模拟准确率超过92%(如Qwen3-8B达到97.5%)。但对高斯分布,由于需要两次随机数生成,第二次时状态值已经很大,LLM在大数乘法上频繁出错,准确率大幅下降。
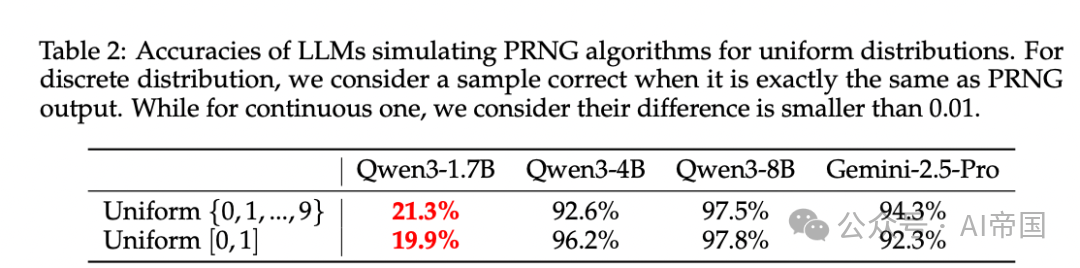 图片
图片
[Table 2: LLM模拟PRNG算法的准确率]Qwen3-8B在均匀离散和均匀连续分布上分别达到97.5%和97.8%的准确率,而Qwen3-1.7B仅约20%。
X说
论文的结论直指要害:当前LLM的随机行为是训练数据偏差驱动的"随机性幻觉",而非受控的概率采样。分布转换虽然有效,但每次采样都需要昂贵的推理计算,对需要频繁采样的agent系统来说代价过高。论文认为,一个务实的解决方案是为LLM提供一个有状态的外部采样器,在调用之间追踪状态。这种有状态工具的概念,可能对采样之外的其他agent流程同样有价值。
原文标题:The Illusion of Stochasticity in LLMs
原文链接:https://arxiv.org/abs/2604.06543
本文转载自AI帝国,作者:无影寺
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
一步到位!OpenClaw Windows 完整部署,小白无压力上手
小白友好 OpenClaw 2.6.2 一键安装详细步骤
阿里云AI产品特惠:Qwen3.6全模型通享4.5折,至高享7000万免费tokens,加速Al应用落地
【从零上手】OpenClaw 2.6.2 新手技能选择与配置全攻略
OpenClaw 绑定飞书教程:一键接入企业IM的完整指南(包含最新2.6.4版本)
【手把手教你】新手入门 OpenClaw 2.6.2 技能选择推荐
大模型竞赛——从参数膨胀到效能革命的转折
开源 AI 智能体 OpenClaw 安装 电脑自动化操作部署指南
小龙虾 AI OpenClaw v2.6.2 安装步骤 无需手动配环境
阿里云大模型服务平台百炼新人免费额度如何申请?申请与使用免费额度教程及常见问题解答
AI精选