

VLA大模型做长任务总断片?同济KC-VLA用关键帧链给治好了
作者:互联网
2026-04-16
 AI快讯
AI快讯
VLA大模型让机器人动作越来越流畅,但记性仍是短板。面对"刚才加过盐了吗"这类需要回忆过去状态的非马尔可夫任务,现有模型往往束手无策。
强行让模型记住过去会引发三大问题:
转瞬即忘:刚做的事下一秒就忘场景混淆:相似画面导致决策混乱算力爆炸:超长视频让推理慢如蜗牛根源在于主流VLA依赖短时密集观察,缺乏长程时间理解能力。同济大学等提出的Keyframe-Chaining VLA(KC-VLA)框架给出了新思路——不再死记硬背连续视频,而是通过提取和链接语义关键帧,赋予机器人全局的时间感知能力。

arXiv: https://arxiv.org/abs/2603.01465
Github: https://github.com/TJ-Spatial-Intelligence-Lab/KC-VLA1.现有 VLA 输入范式的局限
既然“记不住”是个大问题,那直接给大模型喂入更长的视频流不就行了吗?
图1:不同 VLA 输入范式的对比
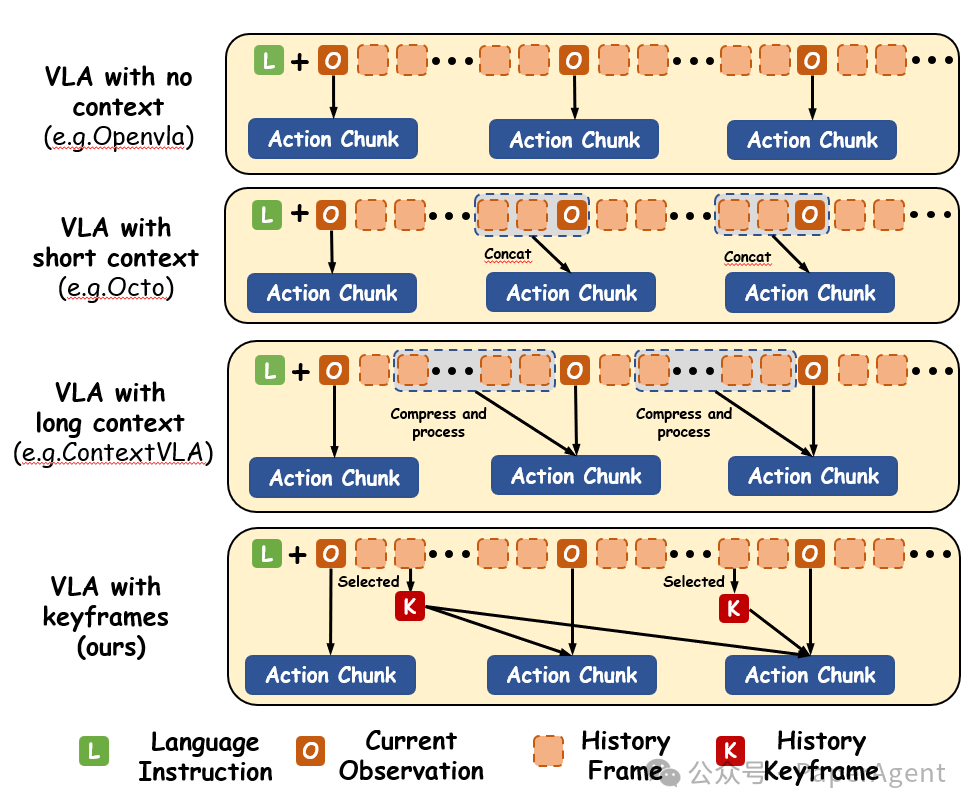
实际上,现有的 VLA 模型在输入范式上并非没有尝试过,但往往陷入了“算力爆炸”与“有效视野受限”难以兼顾的死胡同。结合目前的行业主流做法,主要面临以下局限:
范式一:无上下文 / 短上下文拼接(如 OpenVLA, Octo 等)这是目前最普遍的做法。它隐式地遵循了“马尔可夫假设”——假定当前或最近几帧的观测,就足够推断下一步动作。这种“走一步看一步”的方式在短平快任务中够用,但在复杂的非马尔可夫场景中,关键信息早就滑出了短视窗,模型就会立刻陷入“状态混叠”。范式二:扩展上下文窗口(如 ContextVLA 等)尽管此类方法在一定程度上扩大了模型的观测范围,但受限于计算复杂度和内存瓶颈,其窗口容量终究是有限的,依然难以有效捕获和利用时间跨度较远的关键历史信息。这正是 KC-VLA 想要打破的僵局,提出放弃低效的“密集连续采样”,转而采用 “关键帧链接(Keyframe-chaining)”:像人类做笔记一样,只把发生关键语义变化的瞬间提取并缓存下来。这不仅有效规避了计算冗余,更让策略模型以极低的成本获取了真正的全局时间感受野。
2.时间抽象与动作生成的架构解耦
为克服上述时序局限,KC-VLA 框架的核心思想是摒弃处理冗余的连续视频流,转而采用将时间抽象与动作生成原语进行架构级解耦的设计。
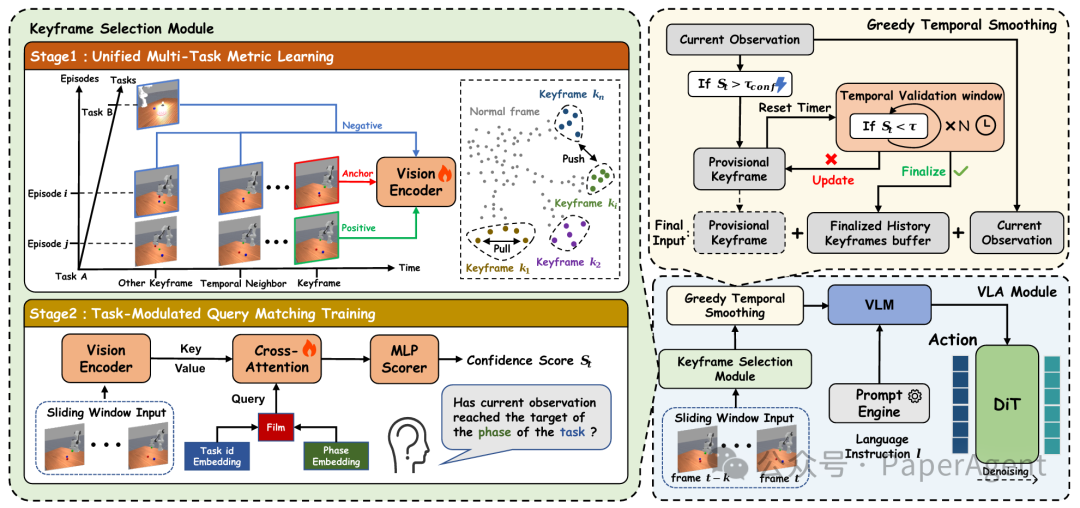
图2:KC-VLA 的系统架构概览:左侧为基于任务调制的关键帧选择模块 (KSM) ,右侧为结合了稀疏语义历史输入与流匹配(Flow Matching)策略的动作生成模块。
该系统主要由以下两个关键组件构成:
轻量级关键帧选择模块 (KSM)
该模块作为视觉流的时间过滤器在线运行。为了在避免计算冗余的前提下精准捕获语义过渡,KSM 采用了精心设计的“两阶段训练与部署协议”:
阶段一:统一多任务度量学习与“三模态负采样” (Tri-modal Negative Sampling)

基于稀疏语义历史的动作生成

3.打造高难度长程记忆 Benchmark
现有的基准测试在评估具身策略的记忆能力时往往存在明显的局限。如对比表所示,诸如 CALVIN 和 LIBERO-Long 等测试集虽然具备长时序特征(Long-Horizon),但普遍存在“马尔可夫偏见”(缺乏 Non-Markovian 属性),即最优动作仅凭当前观测即可推断;而类似 Mikasa-Robo 的测试集虽引入了非马尔可夫约束,但其任务序列较短(平均长度仅 72 步),难以对模型构成真正的长程记忆挑战。
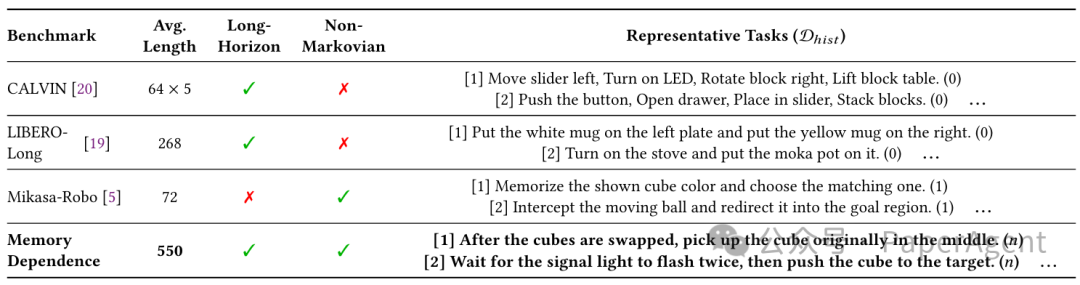
图3:VLA长程任务benchmark对比
为了填补这一评估空白,本研究基于 ManiSkill 模拟器,构建了一个严苛的长时序记忆依赖基准测试 (Memory Dependence Benchmark)。该基准的平均任务长度高达 550 步,是首个同时兼具超长时序跨度、严格非马尔可夫性以及对历史信息高度依赖的综合测试平台。它包含四大核心挑战:
**空间重构 (Spatial Reconfiguration)**:推倒乱序积木,完全凭记忆复原初始的垂直顺序。**时间排序 (Temporal Sequencing)**:按红-绿-蓝的严格顺序搬运,考验模型对已完成进度的确认。**计数延迟 (Counting & Latency)**:观察随机闪烁的信号灯,仅在第二次闪烁后行动。**身份追踪 (Identity Tracking)**:在外观完全相同的方块被机械臂快速“洗牌”后,精准抓取最初位于中间的那个目标。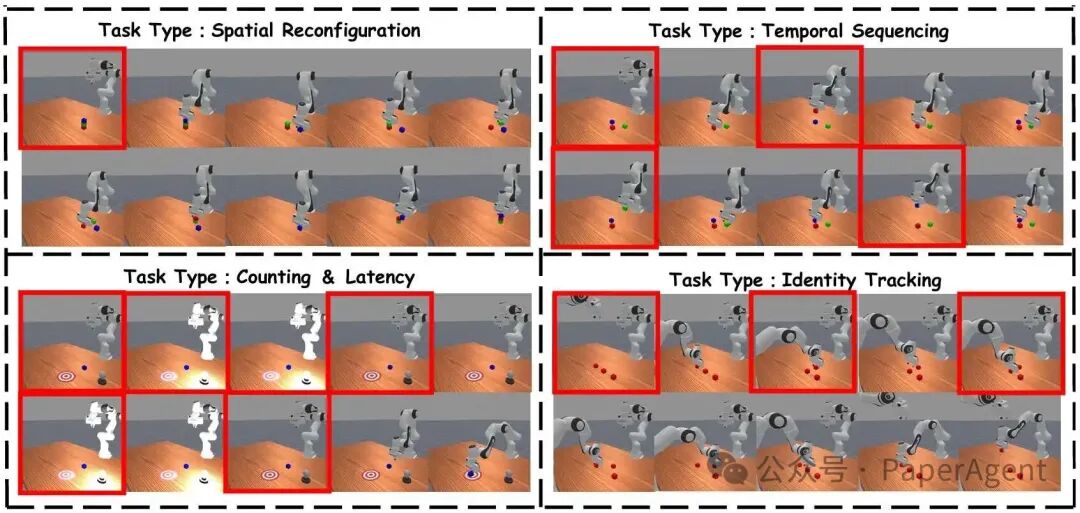
图4:四个非马尔可夫任务
4.仿真 & 真实世界实验
自制仿真benchmark实验结果
在仿真实验中,KC-VLA 展现出了统治级的性能,最终实现了 92.0% 的整体平均成功率,而最强的长视窗基准模型(Long-term GR00T)仅为 57.0%。
抗干扰性与分布外(OOD)泛化
面对光照变化、未知背景、视角偏移等视觉扰动,KC-VLA 展现出极强的鲁棒性。实验数据显示,KSM 模块在各类严苛扰动下仍保持极高精度(F1 > 95),使得模型在 OOD 变体下依然维持 71.5% - 88.5% 的高成功率。
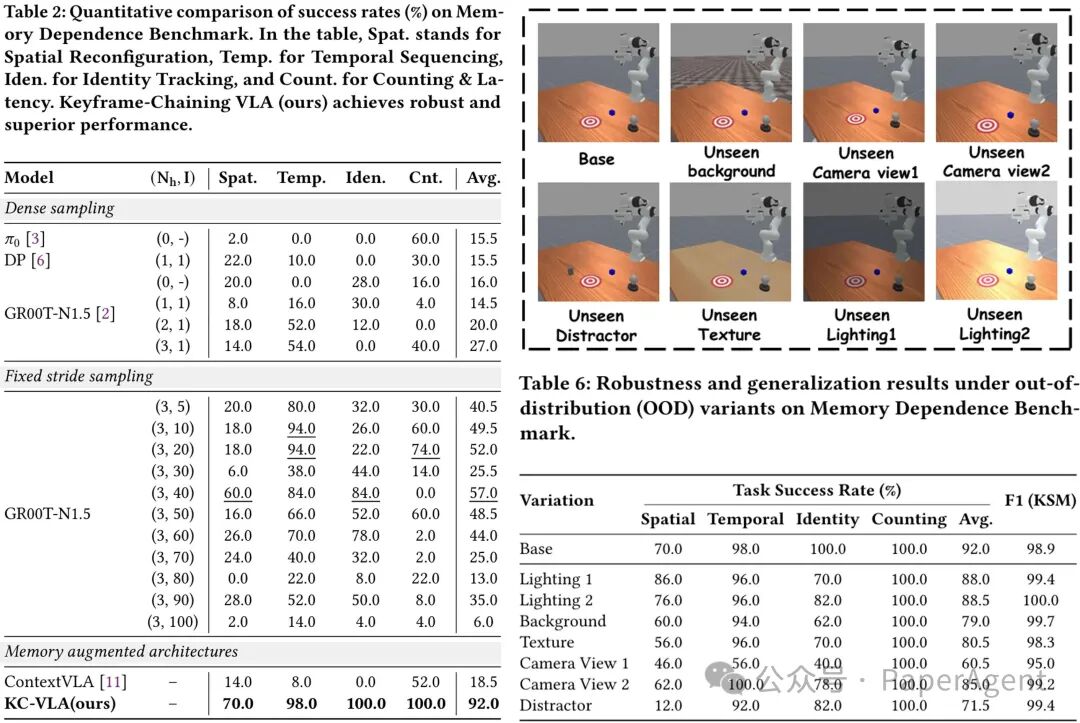
图5:仿真实验结果
真实世界物理部署
在真实的 AgileX Piper 机械臂平台上,仅通过 50 条专家演示进行策略微调,KC-VLA 便成功应对了复杂的长时序多阶段推理任务。长时序多阶段任务的复杂性导致传统基准模型的表现受到显著限制:Diffusion Policy (DP) 与 GR00T 的平均成功率分别仅为 3.8% 和 6.3%,平均阶段完成率(Completion Rate)分别为 32.6% 和 43.1%。相比之下,KC-VLA 展现出了更优的物理环境鲁棒性与长时序一致性,其平均成功率提升至 48.75%,平均阶段完成率达到 75.3%。
图6:真实世界实验的结果
本文转载自PaperAgent
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据

相关文章
阿里云大模型服务平台百炼新人免费额度如何申请?申请与使用免费额度教程及常见问题解答
办公 AI 工具 OpenClaw 部署 Windows 系统一站式教程
Qwen3.6 正式发布!阿里云百炼同步开启“AI大模型节省计划”超值优惠
【新手零难度操作 】OpenClaw 2.6.4 安装误区规避与快速使用指南(包含最新版安装包)
OpenClaw 2.6.4 可视化部署 打造个人 AI 数字员工(包含最新版安装包)
【小白友好!】OpenClaw 2.6.4 本地 AI 智能体快速搭建教程(内有安装包)
零基础部署 OpenClaw v2.6.2,Windows 系统完整教程
【适合新手的】零基础部署 OpenClaw 自动化工具教程
开发者们的第一台自主进化的“爱马仕”来了
极简部署 OpenClaw 2.6.2 本地 AI 智能体快速启用(含最新版安装包)
AI精选