

训练数据砍掉80%,小模型事实准确率反而更好?
作者:互联网
2026-04-16
 AI快讯
AI快讯
当前最前沿的语言模型在面临SimpleQA等闭卷问答基准测试时,准确率往往低于50%。单纯依靠扩大模型参数规模来提升事实准确率,只能带来极其缓慢的对数线性增长。据预测,如果要让人类级别的准确率覆盖维基百科中的所有事实,甚至需要一个具有10^20个参数的超大模型。面对这一令人绝望的数字,必须追问:事实准确率低下究竟是理论上的宿命,还是糟糕的训练数据分布造成的?
盲目扩大数据规模并不能换来更好的事实记忆,将训练集精简至与模型容量相匹配,才是突破事实准确率瓶颈的关键。
 图片
图片
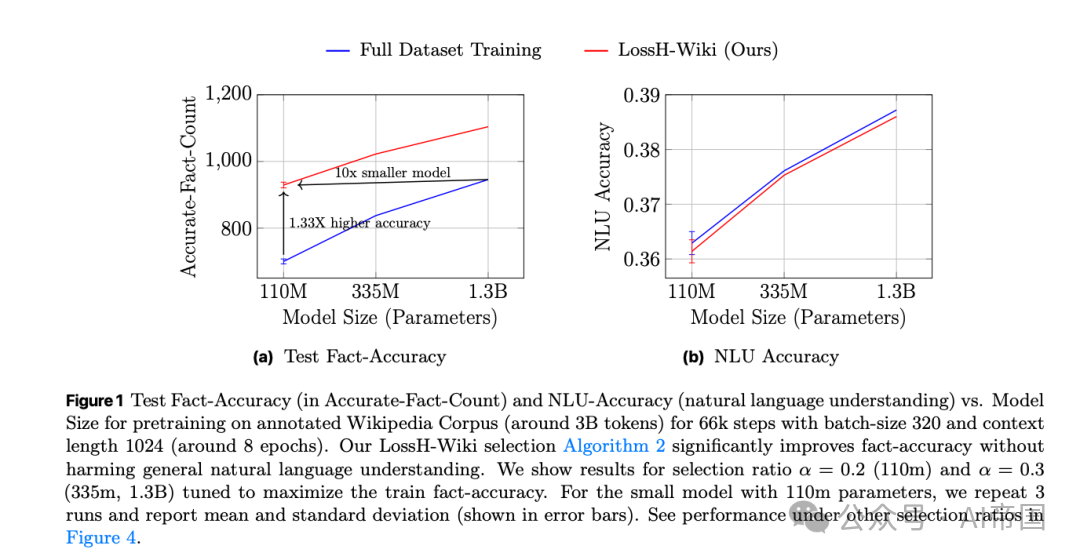
[Figure 1: 测试事实准确率与自然语言理解准确率随模型规模的变化]论文对包含约30亿token的带注释维基百科语料库进行了预训练测试,使用LossH-Wiki算法显著提升了事实准确率,且未损害通用的自然语言理解能力。
苹果的论文从信息论的角度定义了事实记忆,并证明了事实准确率与先前研究确立的每参数2 bits/parameter的记忆容量极限之间的理论联系。在合成的幂律分布电话本记忆基准测试中,论文发现了一个残酷的现实:只要训练数据中包含的信息量超过了模型的容量限制,事实准确率就会呈现次优状态。
 图片
图片
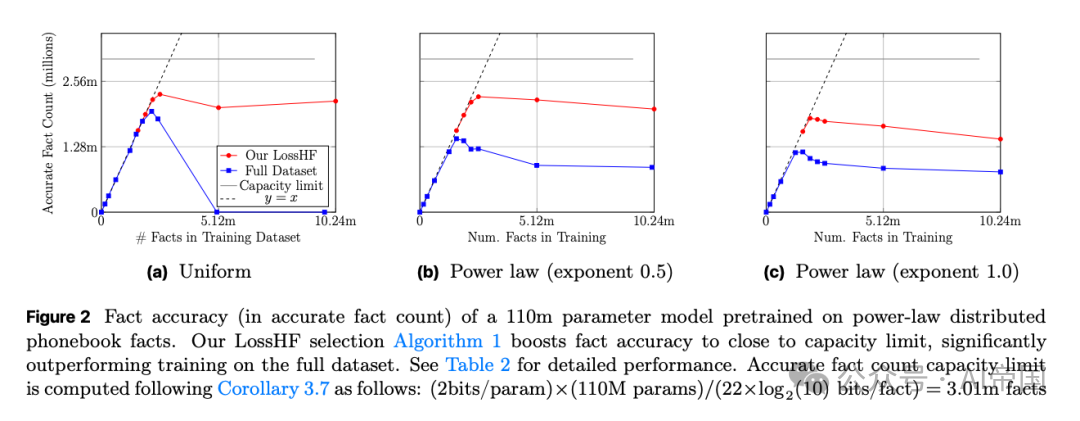
[Figure 2: 预训练在幂律分布电话本事实上的准确率]论文展示了110M参数模型在不同数据规模上的表现,LossHF筛选算法将事实准确率提升至接近容量极限,大幅超越在全量数据集上的标准训练效果。
当数据呈现高度偏态的分布(如幂律分布)时,这种容量缺口会进一步恶化。为了排除是训练步数不足导致罕见事实未被充分学习,论文进行了消融实验验证。结果表明,采用相同训练程序的10倍大模型可以完美回答所有事实;而对小模型进行8倍时长的延长训练,其事实准确率依然表现极低。显然,小型模型与大型模型之间存在事实准确率鸿沟,而在全量非均匀分布的数据集上进行标准训练,注定只能导致次优的记忆结果。
既然全量数据会“撑爆”小模型,论文提出通过限制训练数据中的事实数量,并消除高频事实的过度重复,来逼近理论的记忆极限。但在真实的训练集中,事实的边界和出现频率往往是未知的。论文的突破点在于利用训练损失作为事实频率和信息熵的可靠代理指标。低损失意味着事实频率高或相对简单;高损失则意味着极度罕见或具有高熵。
 图片
图片
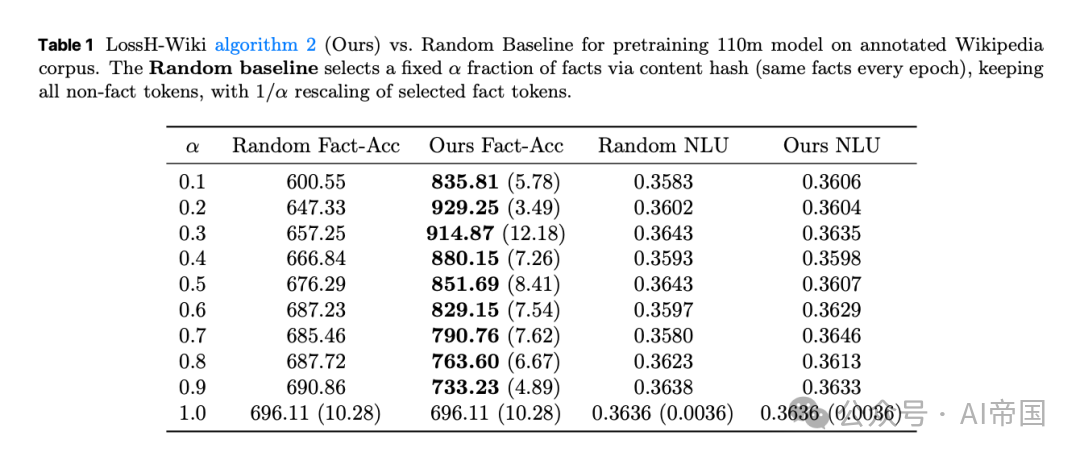
[Table 1: LossH-Wiki算法与随机基线的性能对比] 论文对比了基于损失的筛选与随机事实级修剪的效果,证明简单的随机筛选无法提升事实准确率,仅能在较小筛选比例下勉强维持全量训练的表现。
为此,论文设计了基于损失的数据筛选方案:LossH算法仅选择低损失样本,将训练严格限制在模型可记忆的事实范围内;LossHF算法则在此基础上进一步降低极低损失样本的采样率,以防止过度重复。
具体操作上,论文的筛选算法具备三个核心机制。首先是实施事实级别的筛选,算法计算单个事实的损失并以此为单位进行过滤,因为彻底破坏事实边界的传统词元级筛选并不能改善事实记忆。其次是动态引入在线损失阈值,对于每一个输入批次,实时计算当前模型损失的百分位数作为拦截阈值。最后,为了更好地将损失与底层事实难度对齐,算法使用了特定序列中所有词元的交叉熵损失总和,而非平均值,这一改动被证实与事实的“权重-比特”比率具有更强的秩相关性。
针对包含自然语言的通用预训练语料库,论文对算法进行了深度改进,提出了LossH-Wiki变体。为了不影响非事实内容的学习,该算法变体保留了所有非事实的词元,同时上调被选中事实答案词元的权重,以维持筛选前后的宏观相对权重不变。
 图片
图片
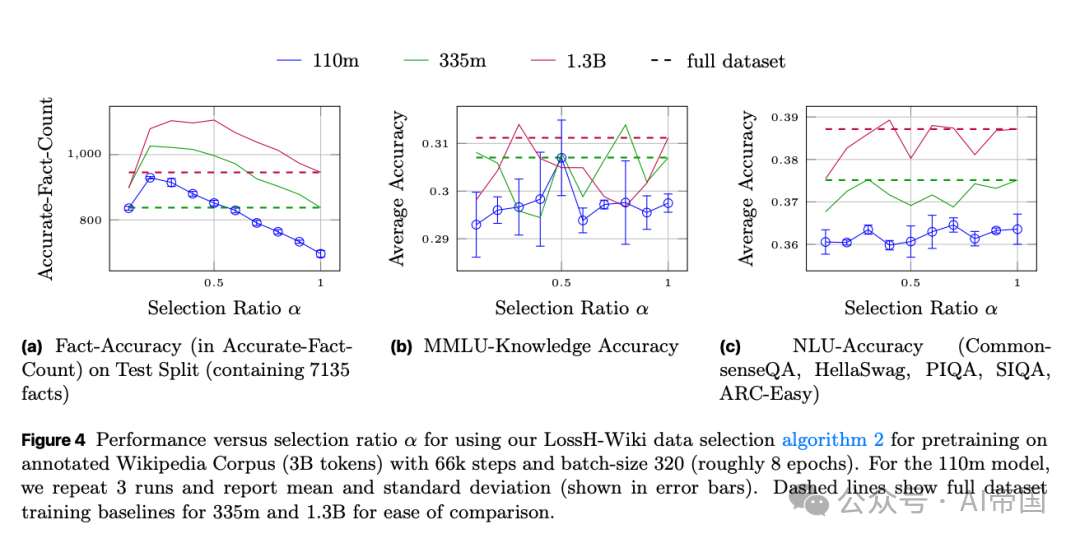
[Figure 4: 预训练模型在不同筛选比例下的性能表现]论文展示了LossH-Wiki算法在不同筛选比例α下的结果,当α等于0.2时事实准确率达到最优,110M模型表现追平了未经筛选的1.3B大模型。
论文在包含30亿词元(3B tokens)的维基百科事实注释语料库上进行了严苛的预训练验证。从头开始训练一个110M参数的GPT2-Small模型,经过大约8个周期的训练后,跑出了极具颠覆性的数据。
使用LossH-Wiki算法,在数据筛选比例α = 0.2(即仅使用20%的精简数据)时,小模型的实体事实准确率直接提升了1.3倍。更为关键的是,这个大幅缩减了训练集的110M模型,其测试集事实准确率完全追平了在全量数据集上训练的10倍大模型(1.3B参数)。
在知识密集型下游任务中,当筛选比例α = 0.5时,该模型的MMLU-Knowledge(基于世界知识的子任务)准确率也持平了在全量数据上训练的3倍体量(335M参数)模型。同时,这种大规模的数据修剪完全没有损害模型通用的NLU(Natural Language Understanding,自然语言理解)能力,其在CommonsenseQA、HellaSwag、PIQA等基准上的综合表现依旧异常稳定。
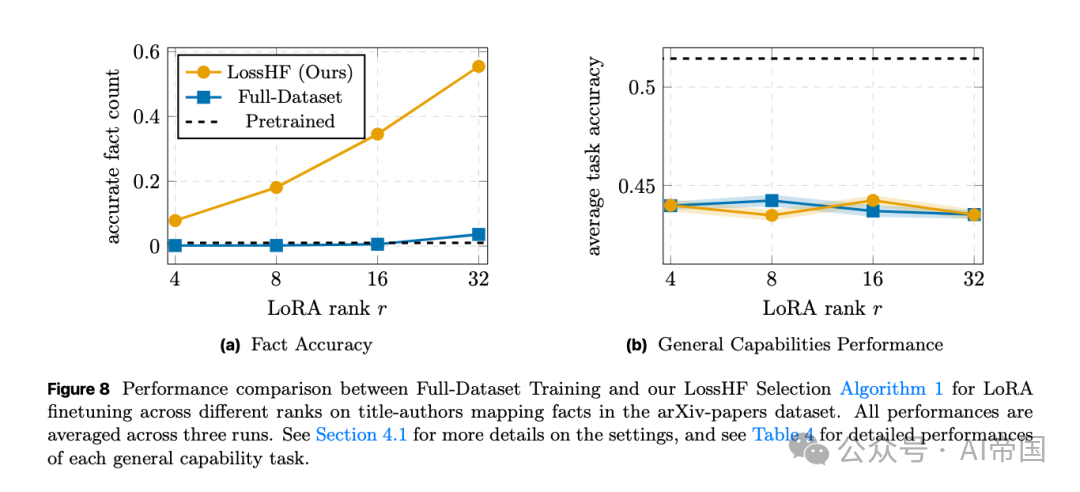 图片
图片
[Figure 8: LoRA微调在arXiv论文数据集上的性能对比] 论文在arXiv论文的标题-作者映射事实上进行LoRA微调,LossHF算法在不同秩下均显著改善了事实准确率,且整体任务准确率与全量训练持平或更优。
除了预训练,在半合成数据的LoRA微调测试中,论文使用Llama-3.2-1B预训练模型,对发表于2025年的171,104篇arXiv论文中的标题-作者映射事实进行学习验证。结果显示,LossHF筛选算法同样能够将事实准确率精准推升至LoRA适配器的容量极限,并且与全量数据集训练相比,没有引发任何额外的灾难性遗忘。
这项研究给整个参数规模竞赛提供了一个冷酷但极具价值的底层启示:一味追求海量训练数据并不可取。实践者应当根据信息论极限精心策划训练集,使其规模与模型的底层记忆容量严格匹配。这不仅意味着研发团队可以用更小规模的模型实现极具竞争力的事实准确率,更为未来以更低计算成本训练高知识密度模型提供了一条切实可行的路线。
https://arxiv.org/abs/2604.08519
本文转载自AI帝国,作者:无影寺
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
(包含安装包)Windows一键部署OpenClaw教程5分钟搭建本地AI智能体
效果广告中点击IP与转化IP不一致?用IP查询怎么做归因分析?
百炼 Coding Plan 是什么?售罄抢不到怎么办?附抢购技巧及平替方案
AI 英语学习 App的开发
阿里云优惠券在哪里领取?一般会通过哪些平台发布优惠券?2026领券入口
OpenClaw本地部署指南
【十分钟教会你】新手向 OpenClaw Windows 一键安装使用指南
【含最新安装包】OpenClaw 2.6.2 本地部署与实操全流程
OpenClaw 2.6.2 安装与网关配置全程教程
从零搭建 AI 智能体:OpenClaw 2.6.2 Windows 一键部署超详细教程
AI精选