

第3篇调度系统运转机制解析
作者:互联网
2026-03-21
 AI教程
AI教程

前文已解析调度系统核心问题与Workflow建模逻辑,接下来将聚焦关键问题:当触发条件满足时,Workflow实例如何被完整执行?
本文将深度剖析DolphinScheduler从触发到执行的全流程,重点解析其分布式调度架构的核心设计理念。
在数据平台里,"调度跑起来"从来不是一句轻描淡写的话。
当你在 UI 上点击 Start ,或者一个 Cron 时间点悄然到达,背后发生的并不是"顺序执行一串任务",而是一套 长期运行、持续决策、状态驱动的系统行为。
DolphinScheduler 的调度机制,本质上更像一个工作流操作系统内核,而不是一个定时器。
理解这一点,是理解它所有架构设计的前提。
在 DolphinScheduler 中,Trigger 只是一个"信号源"。
无论是定时触发、手动触发,还是依赖触发,最终都会被统一处理为一件事:创建一个 Workflow Instance,并进入调度循环。
这一步非常关键,因为从这一刻起,系统关注的对象不再是 Workflow Definition ,而是一个带完整运行状态的实例。
在逻辑上可以简化为:
WorkflowInstance instance = workflowInstanceService.create( workflowDefinitionId, triggerType, executionContext);调度系统真正"跑起来"的起点,并不是任务执行,而是状态被写入元数据存储。
很多调度系统会把大量逻辑堆进执行节点里,但 DolphinScheduler 刻意让 Master 保持"轻"。
Master 启动后,会进入一个持续运行的调度循环,本质类似这样:
while (workflowInstance.isRunning()) { List readyTasks = dag.findRunnableTasks(); for (TaskInstance task : readyTasks) { dispatch(task); } sleep(scheduleInterval);} 注意这里的重点不在 dispatch,而在 findRunnableTasks()。
调度的核心不是"派发",而是"判断"。
在定义阶段,Workflow 是一个 DAG;但在运行阶段,它更像一张 状态不断变化的图。
每个 Task 节点至少包含以下状态维度:
- 当前运行状态(SUBMITTED / RUNNING / SUCCESS / FAILURE)
- 上游节点的完成情况
- 重试次数、失败策略
- 条件分支计算结果(如果存在)
Master 在每一次调度循环中做的事情,本质是:
伪逻辑可以抽象为:
boolean canRun(TaskInstance task) { return task.state == INIT && allUpstreamTasksSuccess(task) && conditionSatisfied(task) && retryPolicyAllows(task);}这也是为什么 调度是状态驱动的,而不是事件驱动的。事件只负责"改变状态",而调度决策永远基于"当前全局状态"。
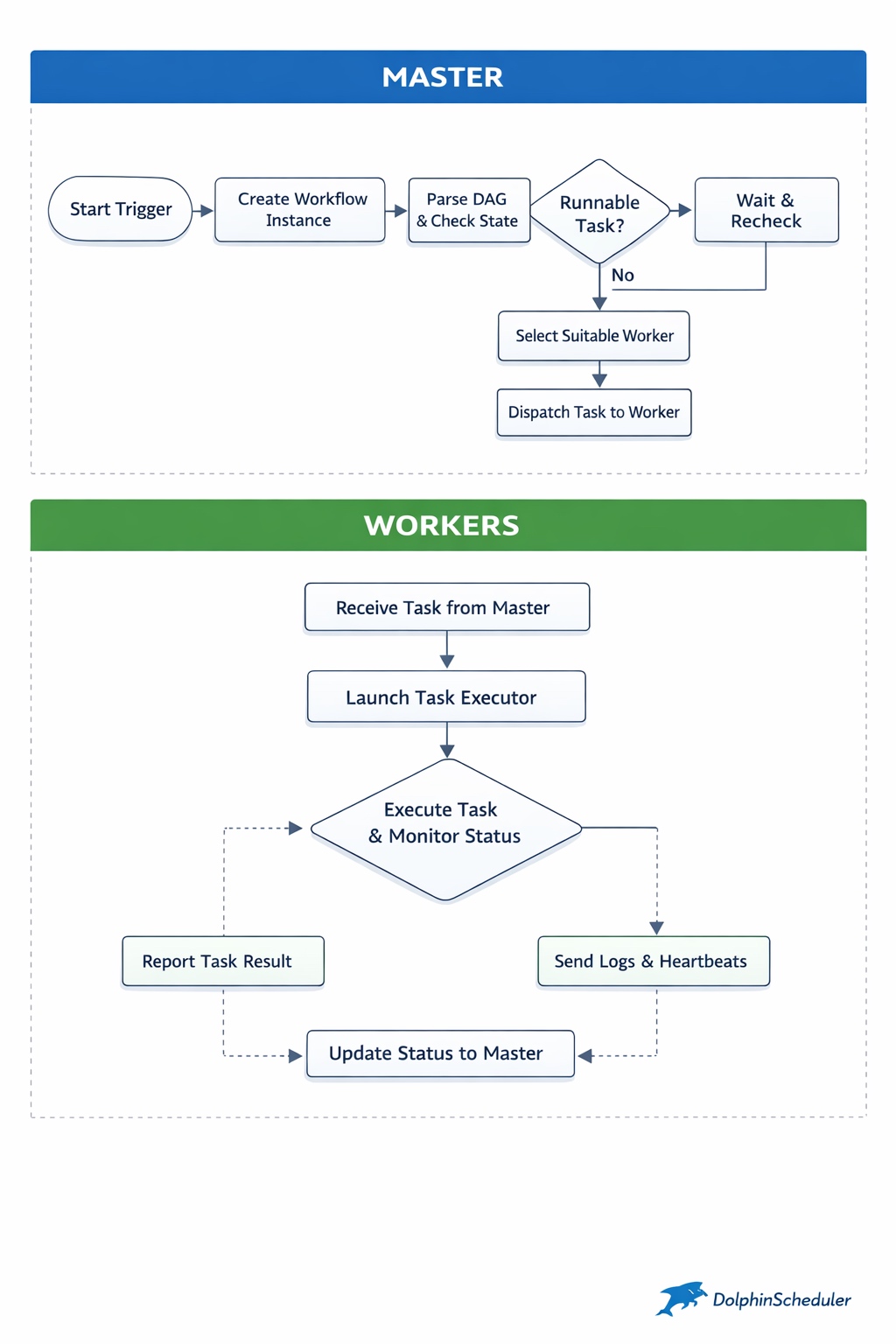
一旦 Master 决定某个 Task Instance 可以运行,它并不会关心"怎么跑"。
它只做一件事:为这个任务选择一个合适的 Worker,并发送执行指令。
Worker worker = workerManager.select(task);workerClient.submit(task);从这一刻起,Master 与任务的直接关系就断开了。
这条边界非常重要,它意味着:
- Master 不维护执行线程
- Master 不感知执行细节
- Master 不承担任何执行风险
Worker 才是真正"跑任务"的地方。
当 Worker 接收到 Task Instance 后,它会:
- 构建执行上下文(参数、环境变量、资源)
- 拉起对应的执行器(Shell / Spark / Flink / Python)
- 持续监控进程状态
- 将执行日志、心跳、结果异步上报
典型执行流程类似:
export DS_TASK_ID=12345export DS_EXECUTION_DATE=2026-02-09/bin/bash run.sh > task.log 2>&1Worker 的世界是混乱、异构、不可预测的,这也是它必须被彻底隔离的原因。
在真实生产环境中,任务具有极强的异质性:
- Spark 作业占内存
- Python 脚本吃 IO
- Shell 脚本可能什么都干
如果 Worker 是中心化或强绑定的,调度系统会迅速失控。
DolphinScheduler 选择了 完全对等的 Worker 模型:
- 任意 Worker 都可以执行任意任务
- Master 只通过心跳和负载感知 Worker 状态
- Worker 随时可以增加、下线、替换
这使得执行层具备了天然的 弹性与容错能力。
调度系统最危险的不是任务失败,而是失败向系统核心蔓延。
如果调度线程被执行阻塞,如果 Master 需要感知执行细节,那么:
- 一个慢任务会拖垮整个系统
- 一个异常执行会污染调度逻辑
- 系统复杂度会指数级增长
DolphinScheduler 通过强制解耦,把复杂性锁死在 Worker 侧:
- 执行失败 → 状态变化
- 状态变化 → 触发下一轮调度判断
- 调度逻辑本身保持纯粹
这是一个非常工程化、非常成熟的系统设计选择。
如果从更高一层抽象来看,DolphinScheduler 的运行并不是"任务在跑",而是:
Trigger 只是状态的起点,Worker 只是状态的制造者,Master 则是状态的裁判。
理解这一点,你就会明白为什么:
- 调度系统一定要有元数据中心
- DAG 必须是可计算状态
- 执行层永远不能反向侵蚀调度层
很多人用调度系统,只关心"能不能跑";真正长期维护调度系统的人,关心的是:
- 它在失败时会不会失控
- 在规模增长时还能不能 hold 住
- 在复杂度上升时还能不能演进
DolphinScheduler 的调度机制,正是为这些长期问题而设计的。
通过以上分析可见,DolphinScheduler通过状态驱动、分层解耦的架构设计,实现了调度系统的稳定性和可扩展性,为复杂数据工作流管理提供了可靠保障。
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
慕尼黑 MVG & S-Bahn 实时追踪命令行工具 - Openclaw Skills
Reddit 研究技能:自动化社群洞察 - Openclaw Skills
豆包聊天:带有联网搜索功能的免费 AI 对话 - Openclaw Skills
NightPatch:自动化工作流优化 - Openclaw 技能
国产 AI 视频生成器:Wan2.6 与可灵集成 - Openclaw Skills
Sonos Announce:智能音频状态恢复 - Openclaw Skills
Hypha Payment:P2P 代理协作与 USDT 结算 - Openclaw Skills
Cashu Emoji:隐藏代币编解码 - Openclaw Skills
技术 SEO 精通:审计、修复与监控 - Openclaw Skills
Teamo Strategy:高级认知任务拆解 - Openclaw Skills
AI精选