

MiniMax推出新一代Agent大模型M2.7并首次公开模型自我进化路径
作者:互联网
2026-03-21
 AI快讯
AI快讯
人工智能领域迎来重大突破,MiniMax最新发布的M2.7大模型开创性地实现了自我进化能力,标志着AI技术迈入新阶段。让我们深入解析这项前沿科技成果。
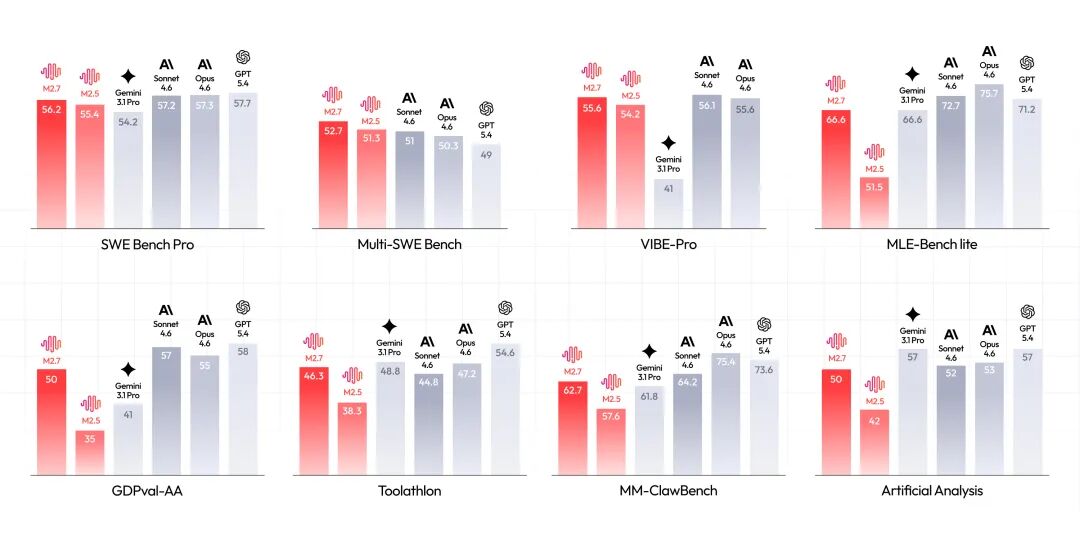
在涵盖多种编程语言的SWE-Pro测试中,M2.7展现卓越性能,以56.22%正确率与GPT-5.3-Codex持平;在Repo级代码生成基准VIBE-Pro上取得55.6%得分,接近Opus 4.6水平。
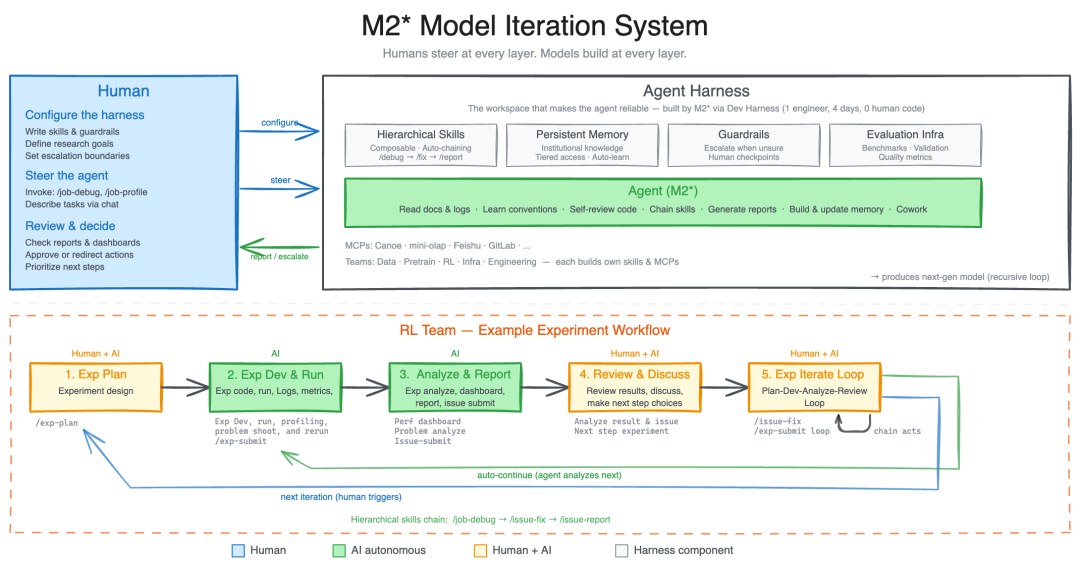
M2.7的核心突破在于构建了完整的Agent Harness体系,整合Agent Teams、复杂Skills和Tool Search tool等模块,实现高度复杂的生产力任务自动化处理。在研发过程中,该模型自主构建了数十个强化学习skills,通过更新记忆系统驱动自身优化,形成独特的自我进化闭环。
在实际应用层面,M2.7在软件工程领域表现突出:
- 端到端项目交付能力显著提升,在VIBE-Pro测试中达到55.6%准确率
- 复杂工程系统理解深度增强,Terminal Bench 2测试得分57.0%
- 线上故障排查效率大幅提高,平均恢复时间缩短至3分钟内
专业办公场景同样取得突破性进展:
- GDPval-AA评测ELO得分1495,位列开源模型首位
- Office三件套编辑能力提升,支持多轮高保真修改
- 复杂skills遵循率高达97%,Toolathon测试正确率46.3%
- 构建模型自我进化智能体
M2.7的自我进化机制基于研究型Agent框架实现,该系统整合数据流水线、训练环境、评测基础设施等模块。以RL实验为例,模型可自主完成文献调研、实验监控、问题排查等全流程工作,承担30-50%的工作量。
在优化过程中,M2.7展示了惊人的自主迭代能力:
- 执行完整优化循环超过100轮
- 发现采样参数最优组合等关键优化点
- 内部评测集效果提升30%
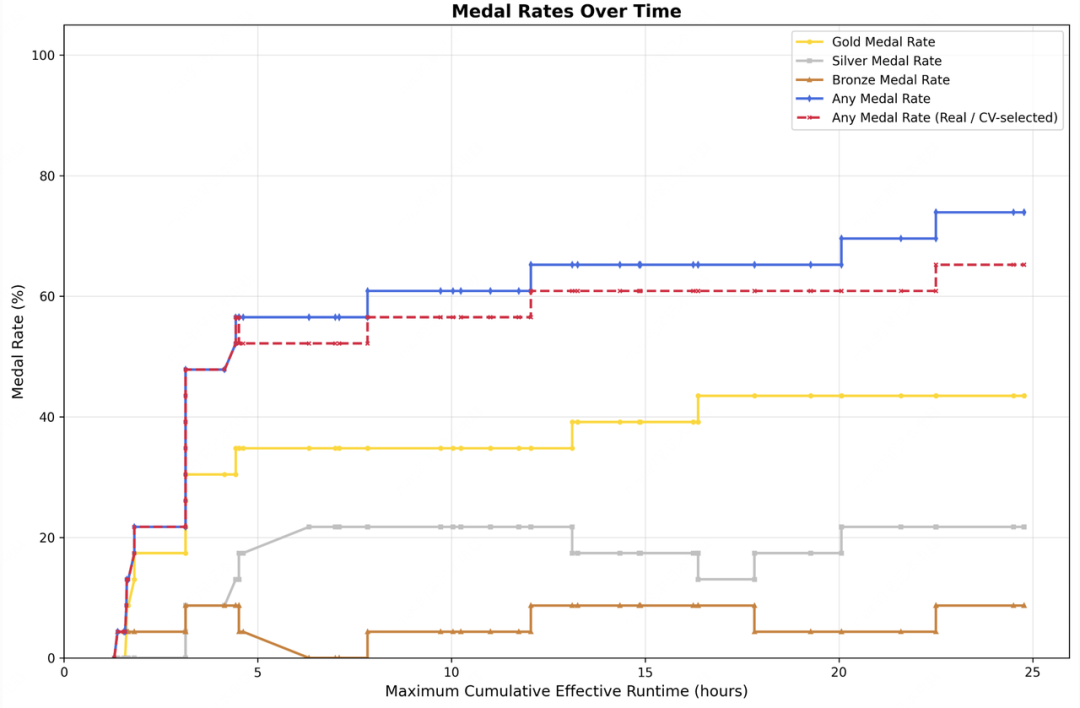
通过短时记忆、自反馈和自优化三模块协同工作,M2.7在MLE Bench Lite测试中平均获得66.6%得牌率,与Gemini-3.1持平。
- 真实的软件工程
M2.7在编程能力方面实现质的飞跃:
- SWE-Pro测试56.22%正确率
- SWE Multilingual得分76.5
- Multi SWE Bench准确率52.7%
特别在复杂系统理解方面:
- Terminal Bench 2得分57.0%
- NL2Repo测试39.8%准确率
Agent Teams功能突破显著:
- 实现角色边界清晰划分
- 支持对抗性推理
- 确保协议严格遵循
- 专业办公
在金融领域应用中,M2.7可自主完成:
- 研报阅读与分析
- 营收预测模型构建
- 专业文档自动生成
测试案例显示,M2.7能:
- 交叉比对多篇研报
- 独立设计假设
- 输出可直接使用的初稿




- 互动娱乐
M2.7在人设保持和对话能力方面取得突破:
- 开发OpenRoom交互系统
- 实现万物皆可互动的Web GUI空间
- 支持实时视觉反馈与场景交互
在MM-Claw测试中达到62.7%正确率,接近Sonnet 4.6水平。
从软件工程到专业办公,再到互动娱乐,M2.7大模型展现了全方位的卓越能力,为人工智能技术的发展开辟了崭新路径,其自我进化特性更预示着AI技术未来无限可能。
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
Elasticsearch93新增bfloat16向量支持
解析OceanBase生态工具链之OAT_obd_OCP_obshell
贝叶斯不确定性引导的早停框架ESTune与OceanBase校企联合研究
杈炬ⅵ&浜哄ぇ閲戜粨閫傞厤瀹炴垬锛歋eaTunnel鍦ㄤ俊鍒涙暟鎹钩鍙颁腑鐨勫簲鐢ㄤ笌韪╁潙鎬荤粨
2026年1月中国数据库流行度排行榜:OB连冠领跑贺新元PolarDB跃居次席显锐气
社区译文解析FUD与真相MySQL是否真的被弃用了
英伟达重新规划AI推理加速布局 暂停Rubin CPU转攻Groq LPU
gpress v1.2.2 全新上线 Web3内容平台迎来更新
CMake 4.3.0 正式推出
短剧采用AI换脸技术使角色酷似明星 制作方与播出方构成侵权
AI精选