

豆包视觉理解模型重磅上线实现精准识别与智能推理
作者:互联网
2026-03-20
 ⼤语⾔模型脚本
⼤语⾔模型脚本
豆包视觉理解模型作为新一代AI技术代表,融合了视觉识别与逻辑推理能力,为用户提供高效精准的图像处理体验。这款创新模型正在推动计算机视觉技术向更智能、更经济的领域发展。
豆包视觉理解模型的核心特性
- 内容识别能力:不仅能准确识别图像中物体的类别、形状和纹理特征,还能深入理解物体间的空间关系及整体场景语义。
- 理解推理能力:具备处理复杂逻辑运算的能力,包括解析数学公式、分析科研图表、调试程序代码等专业级任务。
- 视觉描述能力:可基于图像内容生成细腻的文字描述,例如根据产品设计创作祝福文案,或为儿童绘画编撰完整故事。
- 视觉定位:提供多目标追踪、微小物体检测及三维空间定位等先进功能,适应各类复杂场景需求。
- 视频理解:实现视频语义检索、长视频内容摘要、运动速度分析等视频处理功能。
- 成本优势:每千tokens输入仅需0.003元,处理单张720P图片成本不足4分钱,相比行业标准节省85%费用。
豆包视觉理解模型操作指南
- 访问官方平台:通过官网或指定API接口进入系统。
- 账户登录:完成注册及登录流程。
- 上传素材:提交需要分析的图像文件。
- 添加说明:输入相关文字描述或问题,辅助模型理解图像内容。
- 提交请求:点击确认按钮启动分析过程。
- 获取结果:查看模型返回的详细分析报告。
豆包视觉理解模型实际表现
- 内容识别能力验证

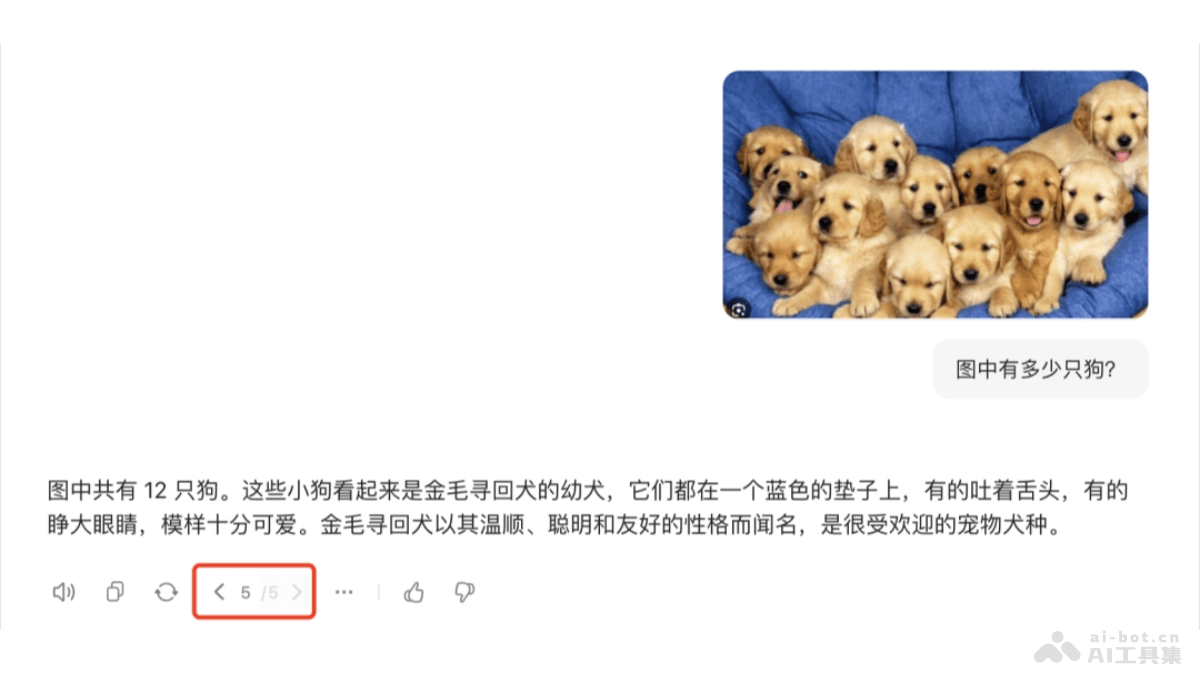
- 理解推理能力验证
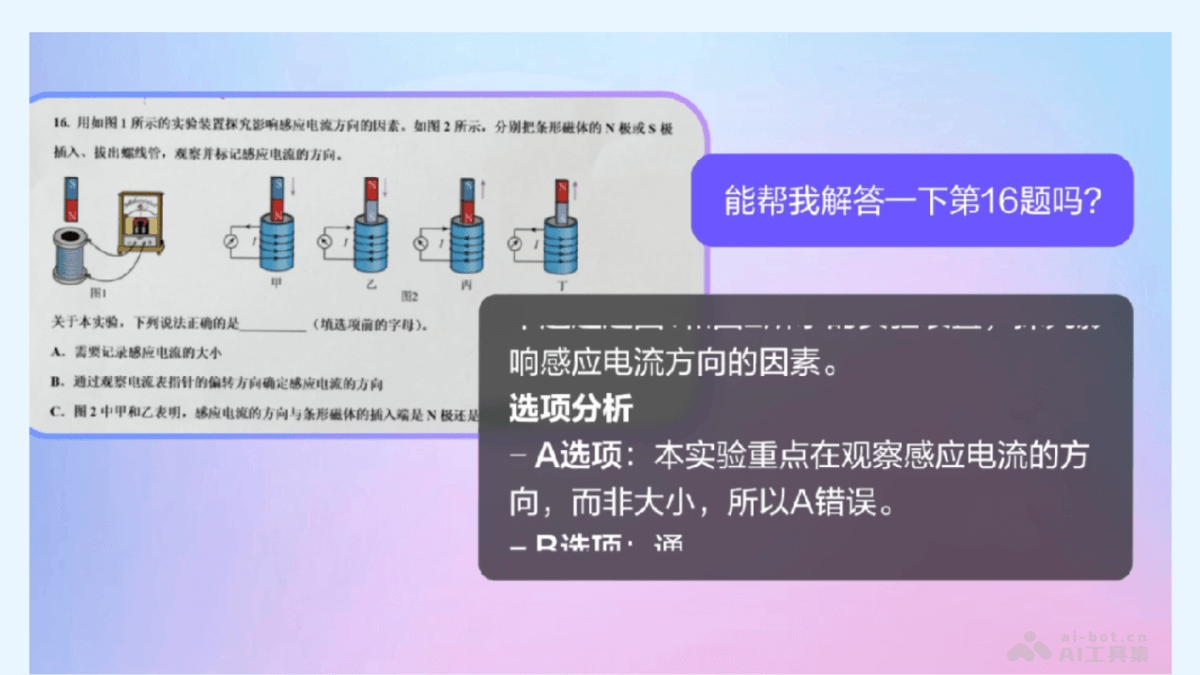
豆包视觉理解模型应用领域
- 智能问答系统:根据用户上传图片提供精准解答。
- 医疗辅助诊断:解析X光、CT、MRI等医学影像,支持临床决策。
- 教育科研支持:协助师生解读实验数据与教学图表。
- 电子商务应用:优化商品展示、智能推荐及客服服务。
- 内容安全审核:自动识别并过滤违规图片内容。
豆包视觉理解模型通过创新的技术架构和实惠的价格策略,为各行业提供了强大的视觉认知解决方案,展现了AI技术在图像处理领域的突破性进展。
相关标签:
豆包
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字
03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
03/30
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
AI精选