

GPT5实测竟算错数学题升级还是噱头
作者:互联网
2026-03-29
 ⼤语⾔模型脚本
⼤语⾔模型脚本
OpenAI最新力作GPT-5正式发布,这款备受期待的大模型能否延续传奇?让我们通过实测一探究竟。
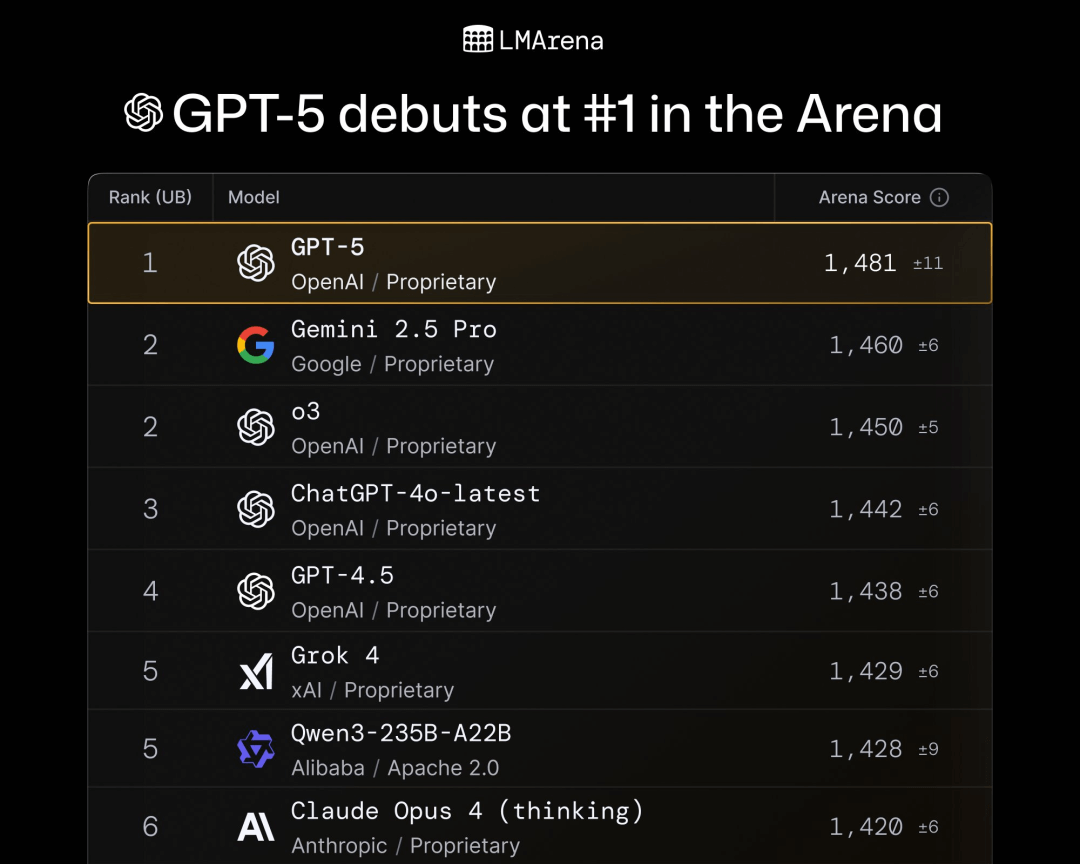
该模型上线后迅速登顶lmarena.ai竞技榜:
- 在文本处理、Web开发和视觉任务领域表现突出;
- 同时在硬提示、编程、数学等专业领域同样占据领先地位。
不过发布会现场出现尴尬一幕:GPT-5生成的图表数据存在明显错误,52.8竟然比69.1显示得更大,30.8和69.1的柱状图高度完全一致。
这款被Sam Altman称为"OpenAI最聪明模型"的产品,实测表现究竟如何?
01. 核心测试
数学能力测试
首先进行经典数学题测试:
提问:比较9.9和9.11的大小关系

GPT-5给出的解释是:比较整数部分相同后,认为小数部分11大于9。若理解为日期,则9月11日晚于9月9日。
编程能力评估
需求:用JavaScript实现六边形内弹跳小球效果,需包含重力、摩擦力等物理特性
实现效果基本达标,物理特性表现尚可,但弹跳效果有待加强。
多模态表现
任务:将给定图片内容翻译成中文,要求忠实原意且通俗易懂

与其他模型对比结果显示:
Gemini 2.5 Pro:

豆包:

GPT‑5:

综合评估显示Gemini翻译最为自然流畅,GPT-5表现与豆包相近但略逊于Gemini。
前端开发测试
开发需求:实现番茄钟应用,需包含计时、统计、主题切换等完整功能
GPT-5实现的界面视觉效果较佳,但存在环形设计不合理等问题;相比之下Gemini实现的功能更完整实用。
02. 总结评价
经过系列测试发现,GPT-5在文案创作、数学推理等方面表现不尽如人意,编程能力保持稳定但未突破,前端设计审美在线但存在细节问题。目前该模型已全面开放使用,建议用户根据实际需求选择适合的AI工具。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据

相关文章
04|MCP 服务接口:让本地能力变成 Agent 可调用的 Tools
为什么需要KVCache?
Claude 一个插件,让全球软件股蒸发 2850 亿美元
如何创建一个 Agent Skill?
打造 GitHub 仓库智能推荐系统
挣脱上下文的枷锁:OpenViking,为 AI Agent 而生的开源上下文数据库
Claude Opus 4.6 和 GPT-5.3 Codex 同时发布,OpenAI 极限截杀 Opus 4.6!
数据库巡检进入智能时代:异常检测算法的落地实践
阿里开源AgentScope多智能体框架解析系列(十八)第18章:企业Skill系统实战 - 用户行为深度分析
2025年终总结:AI浪潮下的一年
AI精选