

四大模型对决KimiK2DeepSeekGrok4Claude4究竟谁能称王
作者:互联网
2026-03-21
 ⼤语⾔模型脚本
⼤语⾔模型脚本

近日开源的Kimi K2模型以1T参数规模震撼亮相,32B激活参数支持免费商用,在多领域基准测试中刷新开源模型记录。
这款万亿级参数模型在编程、工具调用和数学推理等专业领域表现尤为突出,目前已成为官网默认推荐版本。
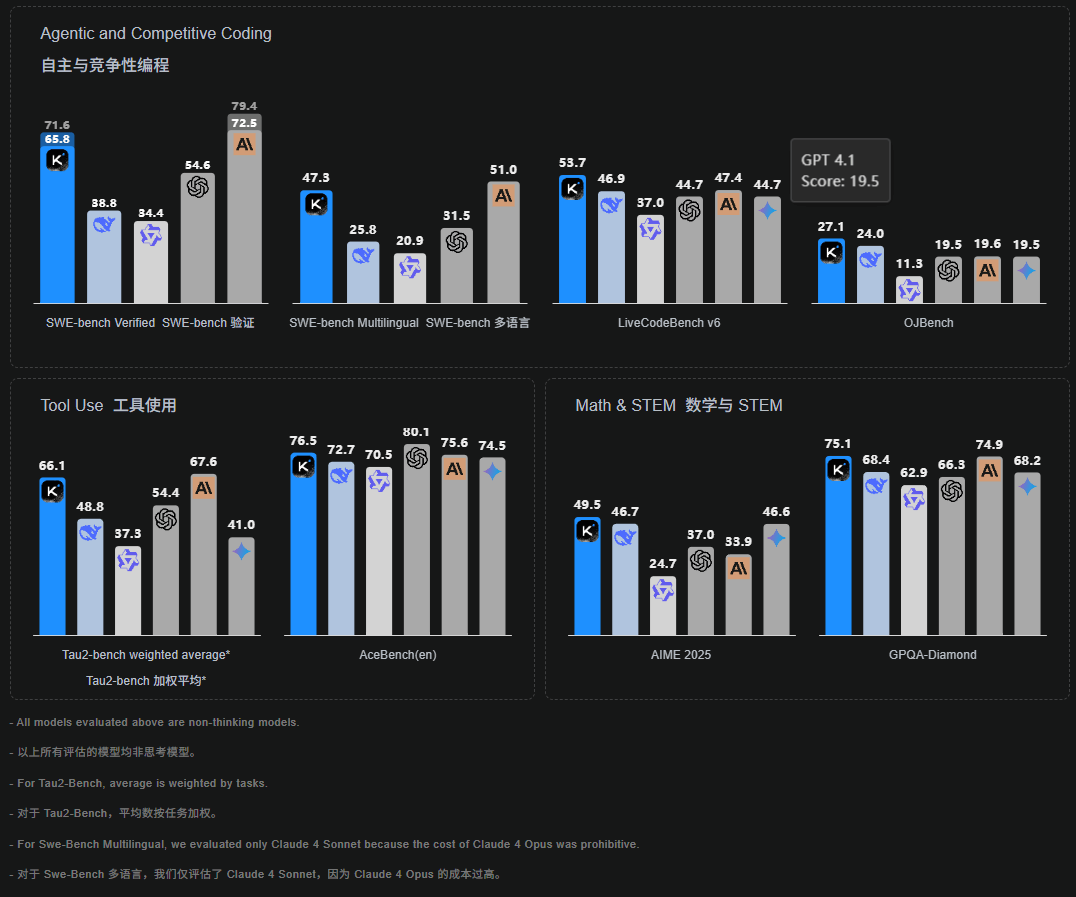
同步开放的API支持128K长文本处理,定价极具竞争力,输入输出费用仅为同类产品的五分之一。

我们针对Claude 4 Opus、DeepSeek R1 0528和Grok 4等主流模型进行了横向对比测试,通过实际应用场景验证各模型性能差异。
测试重点关注可视化页面设计、网页应用开发、3D游戏制作及中文创作四大核心能力,以下为详细评测结果。
- 四大主流大模型横评实测
我们选取了可视化数据看板作为首个测试案例,要求模型生成包含销售趋势图、地区分布图等模块的现代风格网页界面。
Claude 4 Opus虽完成样式设计但图表内容缺失,Grok 4功能完整但审美过时,DeepSeek R1 0528额外添加了无效交互选项。
K2在保持视觉统一性的同时,精准还原了热力图等复杂图表,仅存在轻微数据显示溢出问题。
- 可视化页面测试
- 闹钟应用开发
在Pop Art风格闹钟界面测试中,Claude 4 Opus和DeepSeek R1 0528虽具设计感但功能缺失,Grok 4实现基本功能但交互粗糙。
K2不仅完美呈现漫画风格动效,所有计时功能均可正常使用,展现出全面的开发能力。
- 3D射击游戏制作

Three.js游戏开发测试中,Claude 4 Opus和Grok 4生成代码无法运行,DeepSeek R1 0528实现部分功能但存在严重卡顿。
K2是唯一完整实现星空背景、可交互射击和计分系统的模型,甚至额外添加了玩法提示。
- 中文文学创作



在孙悟空与林黛玉同人小说创作中,Grok 4内容流于表面,Claude 4 Opus结构清晰但文笔普通,DeepSeek R1 0528展现专业级写作功底。
K2通过预先规划故事框架,在保持文学性的同时确保内容连贯性。
- 评测总结
本次测试清晰展现了各模型的差异化优势,K2在工程实现和创意表达方面表现尤为突出。随着开源生态持续发展,大模型技术竞争已进入全新阶段。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
AI Agent 智能体 - Multi-Agent 架构入门
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
一文搞懂卷积神经网络经典架构-LeNet
一文搞懂深度学习中的池化!
厦门大学DeepSeek大模型助力高校企业政府发展 PDF文件 AI教程资料
RAG 不一定非得靠向量库:一套更偏工程落地的“结构化推理检索”方案
北京大学DeepSeek与AIGC应用PDF AI教程资料
开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
金灵AI深度体验报告 CSDN推出金融投研AI智能助手
GSD 使用指南:高效交付功能的结构化工作流
AI精选