

大语言模型是什么一文读懂
作者:互联网
2026-03-28
 ⼤语⾔模型脚本
⼤语⾔模型脚本
大语言模型正重塑人工智能领域,其强大的语言理解和生成能力源于海量数据训练与Transformer架构。本文将深入解析其核心技术原理、训练方法及主流应用场景。

什么是大语言模型
定义与概述
作为人工智能领域的重要突破,大语言模型通过分析TB级文本数据获得类人语言能力。这类模型拥有数百亿参数构成的复杂神经网络,能够完成对话生成、文本创作等多样化任务。以Llama 3为例,其700亿参数架构通过15万亿token训练数据,展现出卓越的语言模式识别能力。
- 数据规模惊人:训练需要TB级别的文本数据支撑
- 参数数量庞大:模型架构包含数百亿至数万亿个参数节点
Meta公司最新开源的Llama 3模型,参数量达到了惊人的700亿,使用了超过15万亿个token的数据进行训练,相当于阅读了数百万本厚厚的书籍。这种规模的学习使大语言模型能捕捉到语言中极其细微的模式和关联,展现出强大的语言处理能力。
核心能力:理解与生成
语义理解
模型能够准确解析输入文本的深层含义,包括情感倾向和用户意图。例如询问天气时,不仅能识别关键词,更能理解这是关于气象信息的需求。
内容生成
基于给定主题或提示,模型可以创作符合逻辑的全新文本。这种能力不仅限于常规写作,还能扩展到代码编写、表格生成等专业领域。
技术基石:Transformer架构
2017年Google提出的Transformer架构革新了自然语言处理领域。其自注意力机制使模型能动态评估词语间关联性,有效处理长距离语义依赖关系。这种架构还具有优异的并行计算能力,可充分利用GPU加速训练过程。
就好比你在阅读一段话时,大脑会自动聚焦于关键的词语和句子,更好地理解整个段落的意思
大语言模型训练机制
模型训练过程类似于培养语言专家,需要消化海量文本资料。训练数据需经过严格预处理,包括字符清理、分词处理等环节,确保覆盖多领域多语言内容。
预训练与微调
训练分为两个关键阶段:
基础训练通过自监督学习任务(如掩码预测)使模型掌握通用语言能力。这个过程需要消耗大量计算资源,但能为模型奠定坚实的语言基础。
专项优化则在特定任务数据集上调整模型参数。例如针对情感分析任务,使用标注数据微调模型,提升其在特定场景下的表现。
Llama 3的开发者也强调了通过指令微调和对齐来提升模型在对话场景下的表现和安全性。
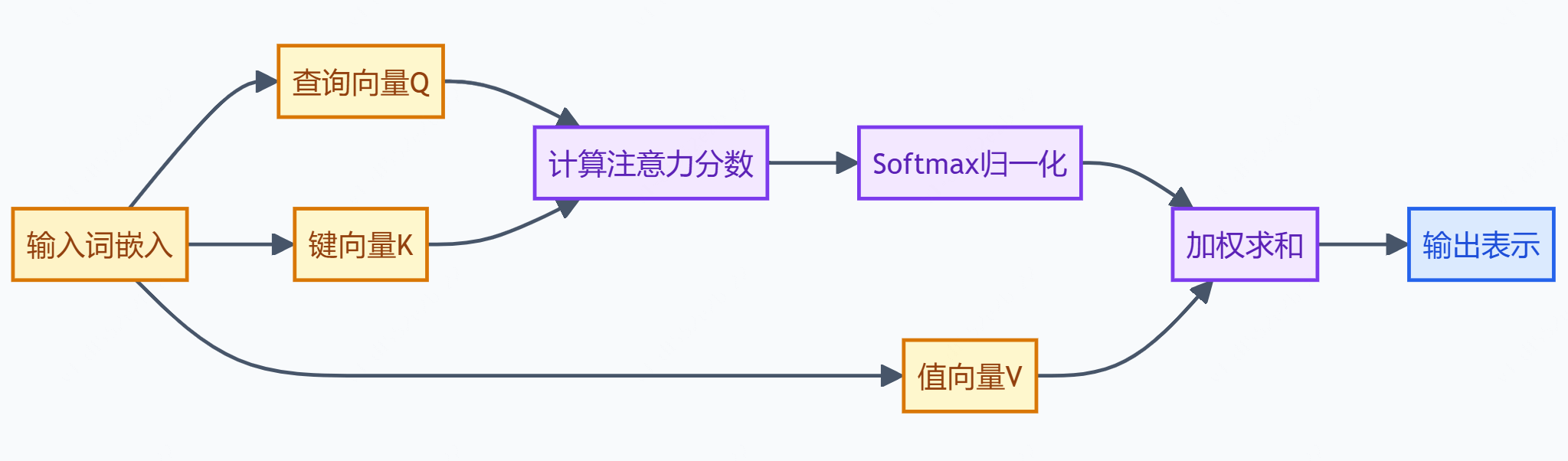
关键技术:自注意力机制
该机制通过查询向量、键向量和值向量的交互计算,动态评估词语间关联程度。这种设计有效解决了传统RNN的长序列处理难题,大幅提升了模型处理复杂语言结构的能力。
主流模型特性对比
DeepSeek:专注于代码与数学
该系列模型在编程和数学领域表现突出,其67亿参数版本在代码生成基准测试中成绩优异,展现出强大的技术问题解决能力。
KIMI:长文本处理能力突出
该模型支持高达200万汉字的上下文处理,擅长分析长篇文档、复杂合同等需要大量文本理解的任务。
| 特性 | DeepSeek | KIMI |
|---|---|---|
| 核心优势 | 代码生成、数学推理 | 长文本处理 |
| 关键能力 | 代码生成,通用语言理解,复杂推理 | 支持200万汉字的上下文输入 |
| 开源情况 | 开源 | 闭源 |
开源与闭源模式对比
开源模型特点
- 促进技术共享和快速迭代
- 提高模型透明度与可信度
- 降低企业技术使用门槛
闭源模型特点
- 通常具备更强大的性能表现
- 提供清晰的商业化路径
- 简化技术集成流程
| 特性 | 开源大模型 | 闭源大模型 |
|---|---|---|
| 核心资源 | 开放源代码和权重 | 由开发公司控制 |
| 主要优势 | 可定制性强,成本较低 | 性能领先,易于集成 |
模型选择指南
根据实际需求选择合适模型:
- 需要定制开发或预算有限时优先考虑开源方案
- 追求顶级性能或快速部署时可选择闭源API服务
代表性模型概览
主流开源模型
| 模型系列 | 代表模型 | 主要特点 |
|---|---|---|
| Meta Llama |
相关标签:
Grok
相关推荐 专题 + 收藏 + 收藏 + 收藏 + 收藏 + 收藏 最新数据 相关文章 OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理 03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字 03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准 03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建 03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板 03/30
SkyBot由Skywork研发的云电脑AI助手 03/30
AI Agent 智能体 - Multi-Agent 架构入门 03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程 03/30
一文搞懂卷积神经网络经典架构-LeNet 03/30
一文搞懂深度学习中的池化! 03/30
AI精选 |