

Meta开源新一代大语言模型Llama3
作者:互联网
2026-03-27
 ⼤语⾔模型脚本
⼤语⾔模型脚本
Llama 3作为开源AI领域的最新突破,凭借8B和70B两种参数规模,为自然语言处理带来了更高效可靠的解决方案。该模型在编程、翻译等场景展现出强大潜力,下文将详细介绍其核心特性。
Llama 3的系列型号
当前Llama 3提供8B和70B两种参数版本,分别针对不同计算需求的应用场景设计,未来还将推出400B参数的升级版本。
- Llama-3-8B:80亿参数规模,专为快速推理设计,在保持高性能的同时降低计算资源消耗。
- Llama-3-70B:700亿参数规模,适合处理复杂任务,具备更深入的语言理解与生成能力。
Llama 3的官网入口
- 官方项目主页:https://llama.meta.com/llama3/
- GitHub模型权重和代码:https://github.com/meta-llama/llama3/
- Hugging Face模型:https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
Llama 3的核心改进
- 参数规模扩展至8B和70B,显著提升复杂语言模式的学习能力。
- 训练数据集扩大7倍,包含15万亿token,代码数据量增加4倍。
- 采用高效分词器与GQA技术,优化推理效率和长文本处理能力。
- 通过预训练改进降低错误率,提升响应准确性与多样性。
- 新增Llama Guard 2等安全工具,强化模型防护机制。
- 支持30+种语言数据,为多语言应用奠定基础。
- 在代码生成和逻辑推理任务中表现尤为突出。
性能评估结果
基准测试显示,Llama 3 8B超越同规模竞品,70B版本性能优于Gemini Pro 1.5等模型。人类评估中,Llama 3在12类场景的平均胜率达52.9%。
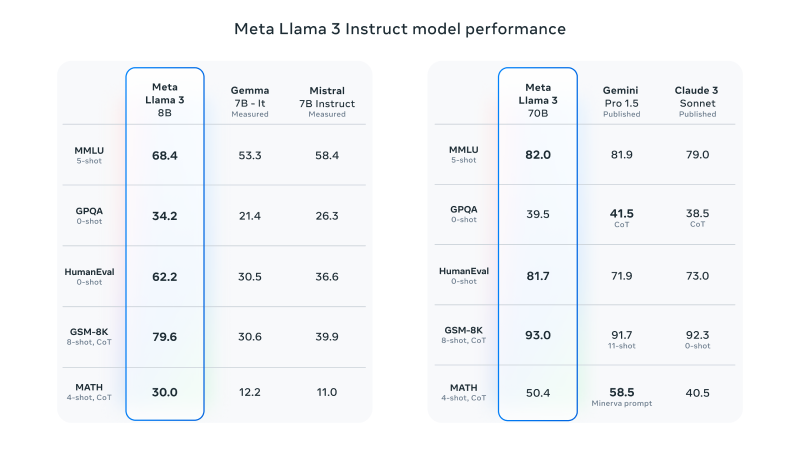
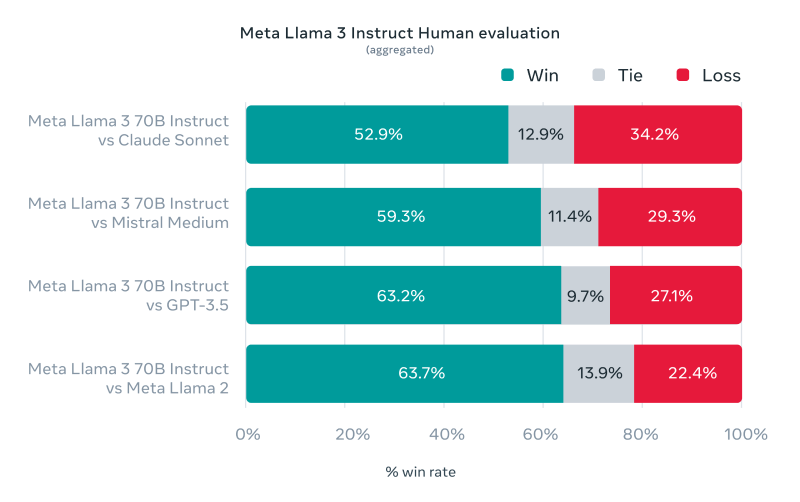
技术架构解析
- 基于解码器架构的Transformer模型,专注文本生成任务。
- 128K token分词器显著提升语言编码效率。
- GQA技术平衡计算量与模型性能。
- 支持8192 token长序列处理,采用边界掩码技术。
- 15TB高质量训练数据包含5%多语言内容。
- 严格的数据过滤机制确保训练质量。
- 采用三重并行化技术实现高效GPU训练。
- 指令微调优化对话与编程等专项任务。
使用指南
开发者操作
通过GitHub等平台获取模型后,可使用torchtune工具进行定制开发。
- 官方模型下载:https://llama.meta.com/llama-downloads
- GitHub地址:https://github.com/meta-llama/llama3/
- Hugging Face地址:https://huggingface.co/meta-llama
普通用户途径
- 通过Meta AI聊天助手体验(部分地区可用)
- 访问Replicate提供的在线对话服务
- 使用Hugging Chat手动切换模型
Llama 3通过技术创新与性能突破,为开源AI树立了新标杆,其多样化应用场景将推动自然语言处理技术的进一步发展。
相关标签:
Gemini
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字
03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
03/30
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
AI精选