

还在乱用MySQL Query Cache?其为何从性能神器到历史尘埃
作者:互联网
2026-03-24
 AI模型库
AI模型库
在MySQL5.7及之前的版本中,query_cache(查询缓存)是很多开发者和DBA都会接触的功能。有人靠它简单优化查询性能,也有人曾被它的“坑”困扰。直到MySQL8.0,官方直接移除了这一功能,让不少习惯用它的人无所适从。
一、query_cache到底是做什么的?
简单来说,query_cache就是MySQL自带的一个“结果缓存器”,核心作用很直白:缓存SELECT查询的完整结果,当后续有完全相同的查询请求时,直接从内存里返回结果,跳过SQL解析、优化、执行这一系列耗时操作,从而节省时间、减轻数据库压力。
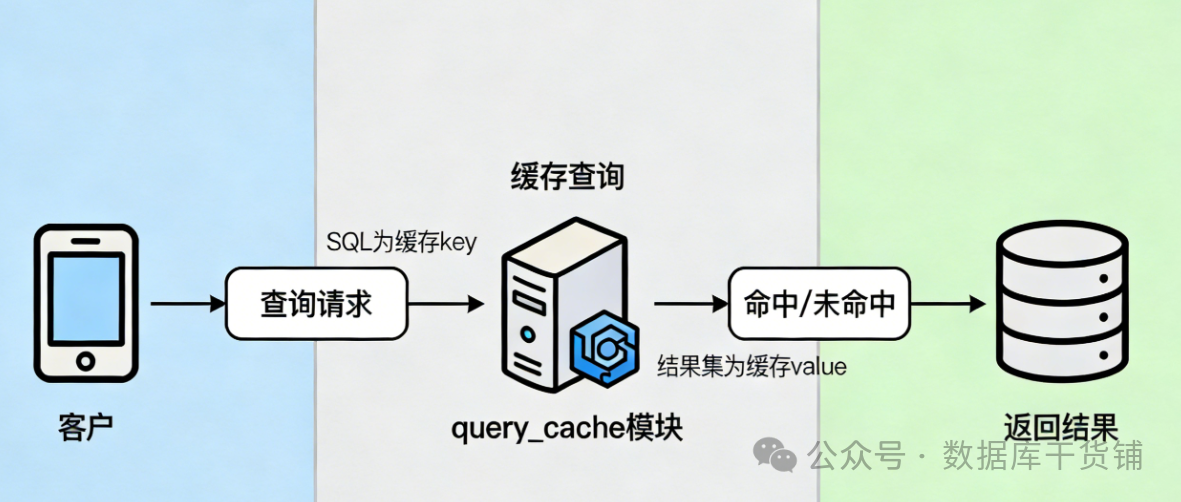
举个最常见的场景:一个电商网站的商品详情页,每天有上万人访问,对应的SQL如下:
如果没有query_cache,每次访问都要去磁盘读取数据、解析SQL、执行查询,反复做重复工作;开启query_cache后,第一次执行这条SQL时,MySQL会把查询结果存到内存里,后续再有人访问同一个商品,就直接从内存拿结果,速度会快很多。
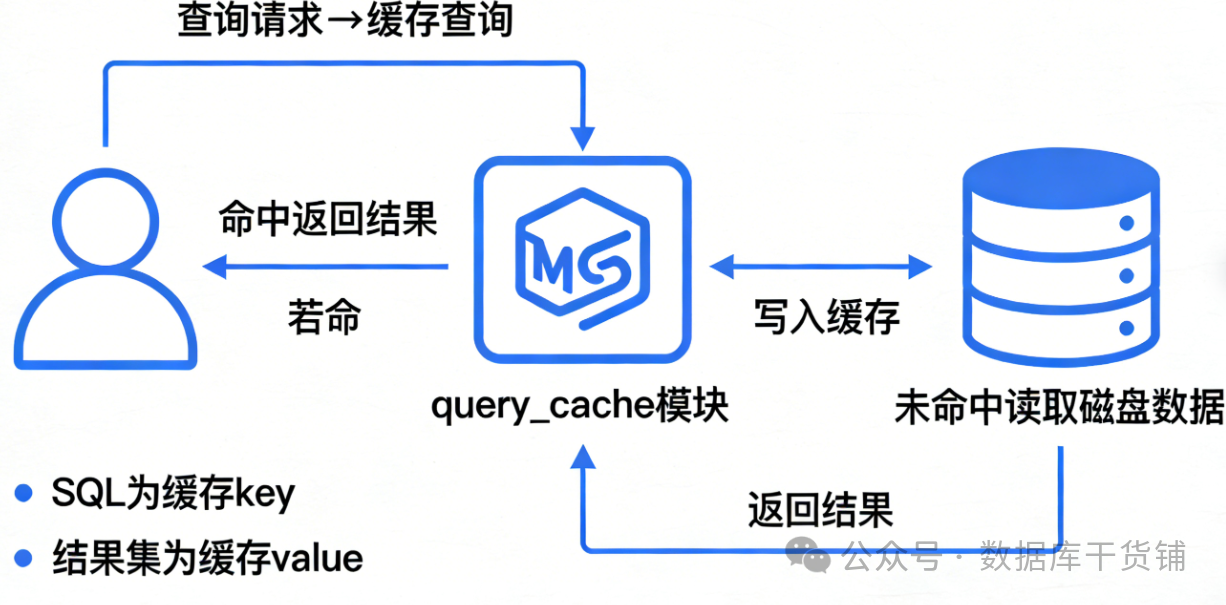
它的工作流程其实很简单,简述就是如下四步:
- 客户端发送一条SELECT查询语句到MySQL服务器
- MySQL先去query_cache里查,看看有没有一模一样的SQL对应的缓存结果
- 如果有(缓存命中),直接把缓存里的结果返回给客户端,跳过后续所有执行步骤
- 如果没有(缓存未命中),就正常解析、执行SQL,拿到结果后,把SQL语句和结果一起存到query_cache里,方便下次复用
除此之外,query_cache的命中条件也极为苛刻,这也是它的一大短板。
这里有个关键注意点:query_cache缓存的是Key(SQL语句)与value(结果集)的对应关系,且要求SQL必须字节级一致才能命中,即大小写、空格、注释哪怕有一点差异,都会被判定为不同SQL,无法命中。比如"select * from user"和"SELECT * FROM user",在query_cache眼里就是两条不同查询,这也是它被诟病的重要原因。
二、为什么MySQL8.0要彻底取消query_cache?
很多人疑惑,既然query_cache能优化查询,官方为何要删除它?答案很简单:在现代互联网高并发、读写频繁的场景下,query_cache不仅无用,反而会拖慢性能,属于“弊大于利”的设计,被淘汰是必然。结合实际项目痛点,主要有4个核心原因。
1.缓存失效太频繁,命中率极低
query_cache有一个致命缺陷:只要某张表发生了任何写入操作(INSERT、UPDATE、DELETE、ALTER等),这张表对应的所有缓存都会被直接清空。举个例子,一张用户表user,里面有1000条缓存记录,哪怕只执行一次"UPDATE user SET age=25 WHERE id=1",这1000条缓存就全没了,后续所有查询都要重新执行、重新缓存。

而现在的互联网系统,几乎都是“读写混合”场景——比如电商商品表,每秒可能有上百次查询、几十次更新,这让query_cache陷入“缓存-清空-再缓存-再清空”的循环,命中率极低。大部分查询仍需走正常执行流程,反而多了一层缓存查询的开销。官方也曾明确,在写多的系统中,query_cache命中率低到几乎无实际价值。
2.全局锁竞争,拖慢高并发性能
query_cache的所有操作(查询缓存、插入缓存、清空缓存)都需要加一个“全局互斥锁”,也就是说,同一时间只能有一个线程操作query_cache。在高并发场景下,大量线程会争夺这个锁,导致线程阻塞、CPU使用率飙升,反而拖慢了整个数据库的吞吐量。
举个极端例子:一个高并发接口每秒有1000次查询请求,开启query_cache后,这些请求会排队争夺全局锁,原本快速的查询因等待锁变慢;反而关闭query_cache后,线程无需等待锁,查询速度更快——这也是很多人开启缓存后性能不升反降的核心原因。
3.命中条件太苛刻,实际复用率低
前面提到过,query_cache要求SQL必须“字节级一致”才能命中,这个条件在实际开发中几乎很难满足。比如:
开发人员写SQL时,有的加空格,有的不加,比如"SELECT id FROM user"和"SELECT id FROM user"(多一个空格)
有的用大写关键字,有的用小写,比如"SELECT"和"select"
ORM框架(MyBatis等)会自动添加注释或调整格式,导致同一个逻辑的SQL,生成的文本不一样
这一点在实际开发中尤为明显,哪怕是ORM框架自动生成的微小格式差异(比如MyBatis生成的SQL末尾多一个空格、带自动注释),都会让query_cache判定为不同SQL,这也是很多人开启缓存后命中率依然偏低的主要原因。
这些细微差异,会让query_cache的实际复用率大打折扣,相当于白占内存、没起作用。
4.维护成本高,与现代缓存方案脱节
query_cache的内存管理非常复杂,它的内存池大小是固定的,无法动态调整,调整参数后需要重启MySQL,而且会导致所有缓存丢失;同时,频繁的缓存失效和更新,还会产生大量内存碎片,浪费内存资源。
更重要的是,随着Redis等专业缓存工具普及,query_cache的优势已被完全替代。Redis支持更细粒度的缓存控制、更高吞吐量和分布式扩容,能灵活处理缓存失效,比MySQL自带的query_cache更高效灵活。官方也意识到,与其耗费精力维护这个“鸡肋”功能,不如将资源投入到InnoDB优化、查询优化器升级等更有价值的方向。
总结来说:query_cache是"理想主义"设计,仅适合“只读、数据几乎不更新”的极端场景(如静态配置表),完全不适应现代互联网高并发、读写混合的需求,被MySQL 8.0移除是顺应技术发展的必然。
三、如何确认一条SQL是否走了query_cache?
这里先明确一个前提:MySQL 8.0及以上版本已彻底移除query_cache所有相关功能,不存在是否走缓存的说法.即便手动配置相关参数,启动时也会报错,提示“Unknown system variable 'query_cache_type'”或者“unknown variable 'query_cache_type'”。
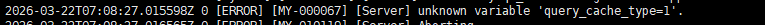
1.如何确定是否走缓存了?
在MySQL 5.7及之前的弃用版本支持query_cache,下面就说说这种场景下,如何确认SQL是否命中缓存——都是实际工作中能直接用的简单方法。
方法1:查看query_cache相关系统变量,确认缓存是否开启
首先要确认MySQL是否开启了query_cache,执行以下命令:
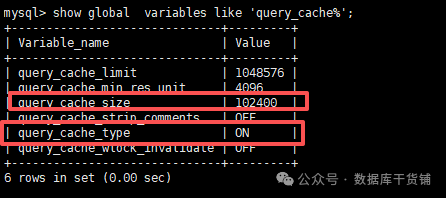
执行后会返回6个变量,我们重点需要关注的两个:
- query_cache_type:缓存模式,0(OFF)表示关闭,1(ON)表示开启(除了带SQL_NO_CACHE的查询),2(DEMAND)表示只缓存带SQL_CACHE的查询
- query_cache_size:缓存内存大小,单位是字节,若为0,说明缓存未开启(哪怕query_cache_type设为ON也没用)
只有query_cache_type不为0且query_cache_size>0时,query_cache才真正开启,否则所有查询都不会走缓存。
方法2:用EXPLAIN分析,查看Extra字段
这是最常用、最直观的方法,在SQL语句前加上EXPLAIN,执行后查看Extra字段的取值。如果Extra显示“Using cache”,说明这条SQL可命中缓存(注意:EXPLAIN不触发缓存,仅模拟查询优化,结果表示“实际执行会走缓存”)
如果Extra显示“Using where; Using cache”,说明查询有过滤条件,且会走缓存
如果没有显示“Using cache”,说明这条SQL不会走缓存(可能是缓存未开启、SQL不满足命中条件,或SQL包含不确定函数等)
方法3:查看缓存命中状态,验证实际命中情况(建议,最靠谱)
前面的方法仅能判断“是否能走缓存”,这个方法可验证“实际是否命中”,执行以下命令查看缓存相关状态变量:
执行以下命令查看缓存相关的状态变量:
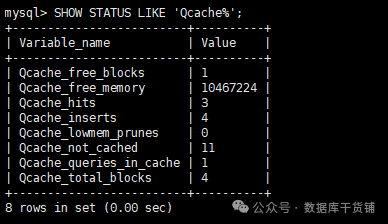
重点关注3个变量:
- Qcache_hits:缓存命中次数,每次有SQL命中缓存,这个数值就会加1。
- Qcache_inserts:缓存插入次数,每次SQL未命中缓存、执行后插入缓存,这个数值就会加1。
- Qcache_lowmem_prunes:缓存内存不足时,被淘汰的缓存数量,若这个数值很大,说明缓存内存不够用,需要调整query_cache_size。
实际操作步骤很简单:
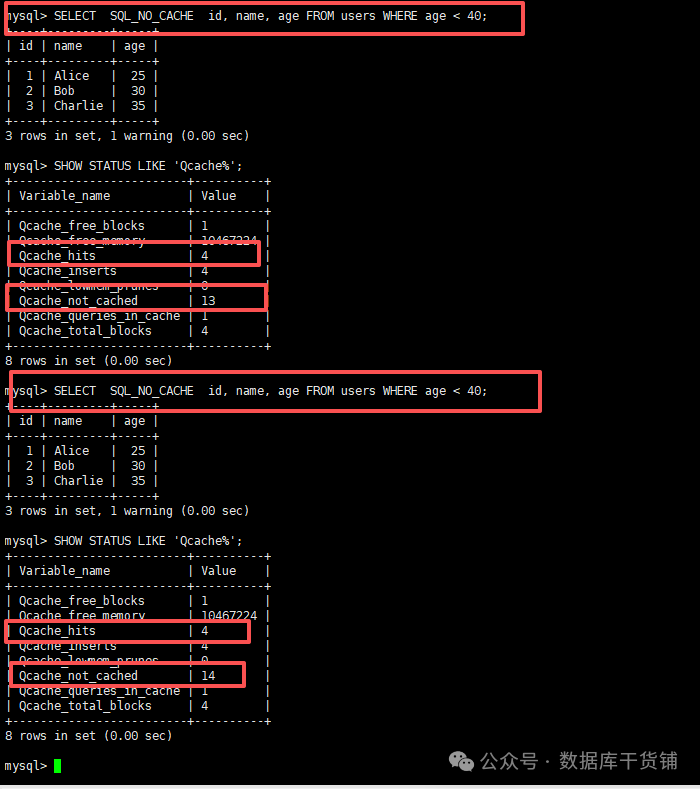
(1)执行
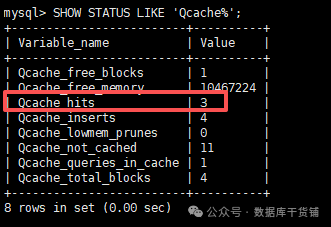
记录当前的命中次数。如此时,Qcache_hits是3。
(2)执行目标
(3)再次执行
如果命中次数加1,说明这条SQL走了缓存;如果没变化,说明未命中。
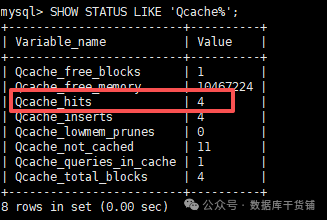
如此时变成了4,即命中了(我的例子在测试环境进行,没有其他SQL干扰)
2.即使开启缓存也不会命中场景
很多人开启query_cache后,SQL始终不命中,其实是踩了这些常见坑,避开它们可提高命中率(仅适用于5.7及之前版本):
SQL包含不确定函数,比如NOW()、RAND()、CURRENT_DATE()等,这类查询的结果不固定,不会被缓存。
SQL涉及临时表、自定义函数、存储过程,或查询了INFORMATION_SCHEMA、PERFORMANCE_SCHEMA等系统表。
SQL语句中带有SQL_NO_CACHE关键字,比如:
查询结果超过了query_cache_limit(默认1MB),太大的结果集不会被缓存。
还有一个易忽略的点:若SQL查询结果为NULL值,query_cache默认也不会缓存,这也是导致缓存未命中的常见原因之一。
四、总结
MySQL 8.0移除query_cache,不是倒退而是优化。它让我们放弃低效鸡肋的缓存方案,转向更高效灵活的优化方式。如今的开发场景中,无需纠结query_cache,可通过以下方式替代其作用:
- 应用层缓存:用Redis、Memcached等专业缓存工具,缓存查询结果,灵活控制缓存粒度和失效策略,这是现在最主流的方案。
- 数据库自身优化:优化SQL语句、建立合适的索引,利用InnoDB的Buffer Pool(缓存数据页和索引页),这才是MySQL性能优化的核心。
- 本地缓存:对于高频访问的静态数据(如配置信息),可以用Caffeine、Guava等本地缓存,进一步提升访问速度。
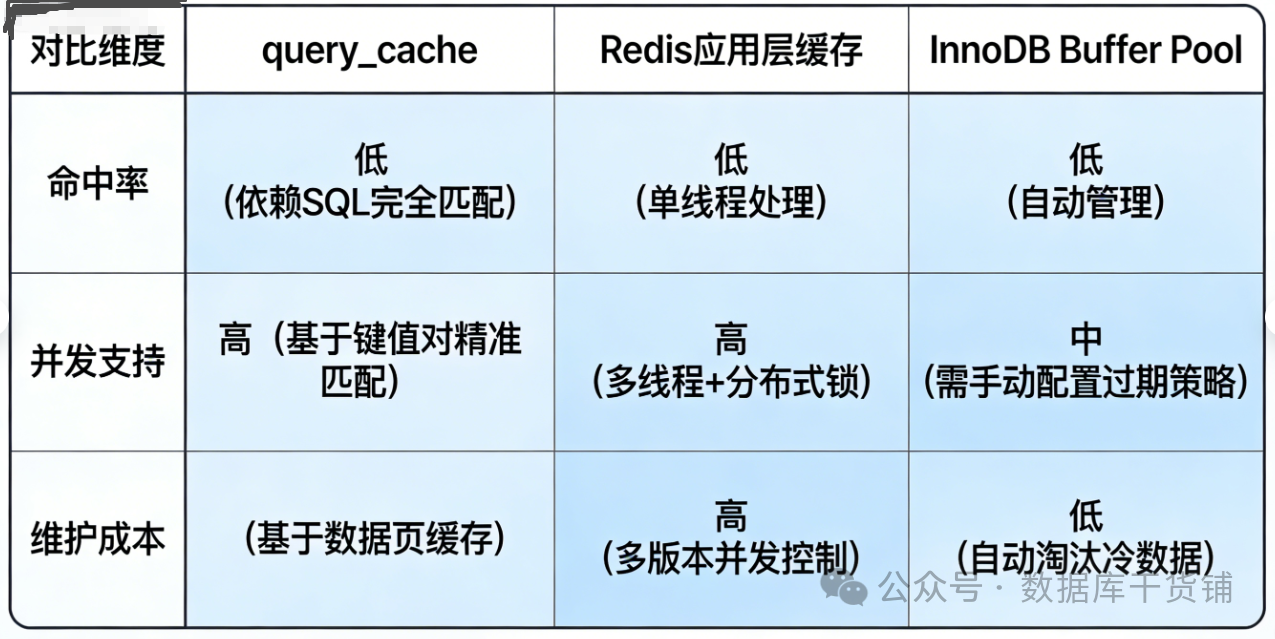
最后强调:若项目仍在使用MySQL 5.7及之前版本,不建议盲目开启query_cache。先评估业务场景,只读、数据几乎不更新的场景可尝试开启;读写混合、高并发场景,关闭query_cache反而能提升性能。而MySQL 8.0及以上版本,直接忘记query_cache,将精力放在更有效的优化上即可。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据

相关文章
NanoClaw 开源轻量级个人AI助手 安全可靠的OpenClaw替代方案
MonsterClaw 采用 OpenClaw 技术打造的本地化AI运行平台
TinyClaw 由TinyAGI推出的开源轻量级多智能体协作框架
携程酒店业务借助NebulaGraph实现月均风控止损逾百万元
稀宇科技开源MiniMax Office Skills生产级办公文档引擎
ToClaw由ToDesk打造的专业定制AI智能体
TypeNo 免费开源的中文AI语音输入法 无需配置直接使用
Sub2API 开源人工智能API中转网关平台 具备多账户管理功能
阿里通义推出视频生成音频框架PrismAudio
Luma AI发布Uni-1模型实现图像理解与生成一体化
AI精选