

携程酒店业务借助NebulaGraph实现月均风控止损逾百万元
作者:互联网
2026-03-30
 AI模型库
AI模型库
在线旅游平台每天面临海量交易请求,黑灰产团伙通过批量账号、设备等手段进行规模化套利,传统风控手段难以应对。本文将分享如何运用NebulaGraph吐数据库实现高效团伙识别,每月成功挽回数百万元损失。
使用NebulaGraph并对图计算进行相应优化升级后,每月可为平台带来数百万元的增量止损。本文将从技术选型、数据建模、算法演进、工程优化等方面,详细介绍我们基于NebulaGraph的实践历程。
风控的目标是研究和治理黑灰产,保障平台安全。
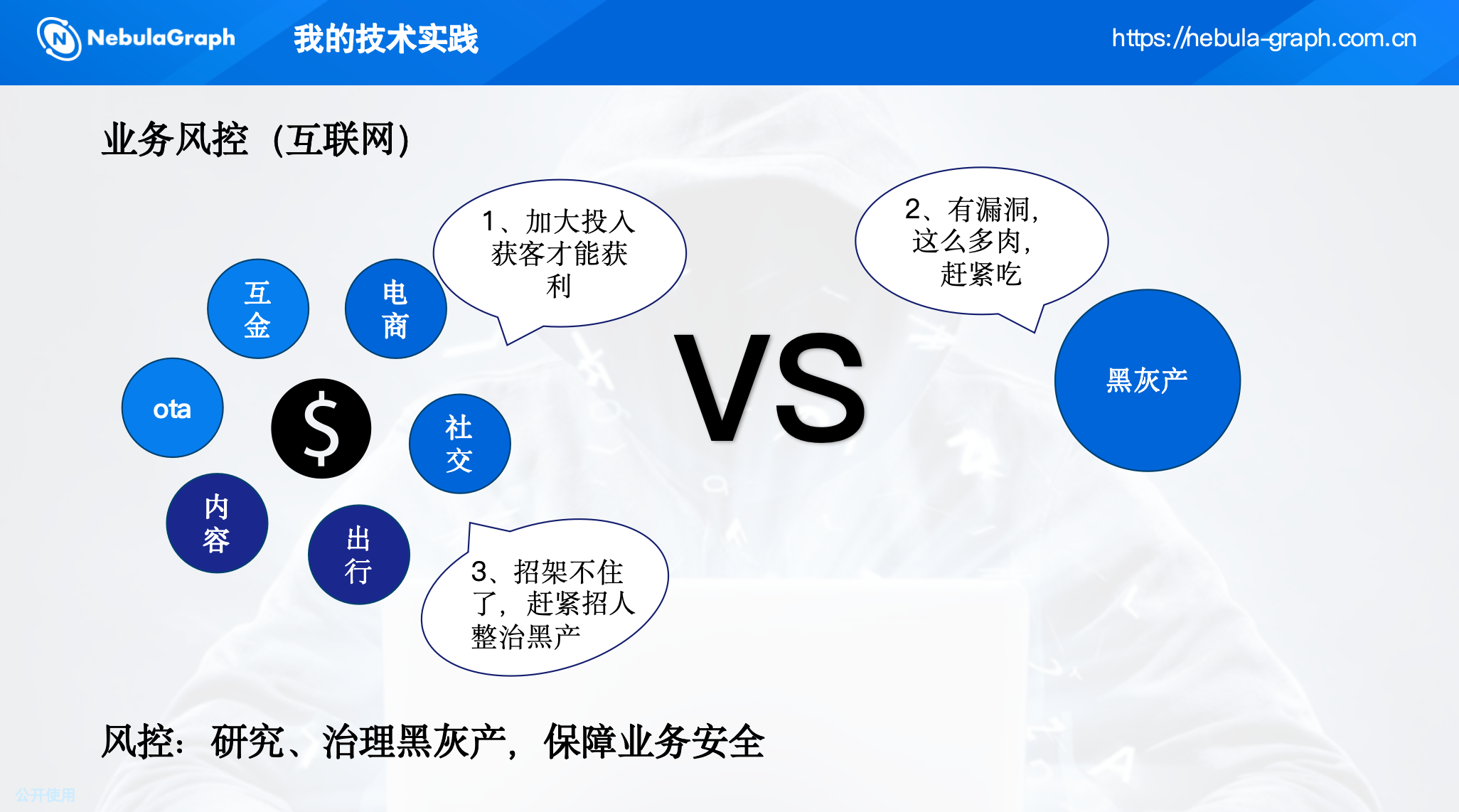
在酒店预订场景下,黑灰产呈现出明显的团伙化特征:他们利用大量账号协同操作,通过注册、抢优惠、虚假交易等方式牟利。单个账号的行为可能看似正常,但账号之间的关联关系(如共用设备、支付账户、手机号等)却能暴露其团伙属性。
传统的风控体系经历了从经验驱动(黑白名单、简单规则)到数据驱动(传统机器学习),再到AI驱动(深度学习、图计算)的演变。
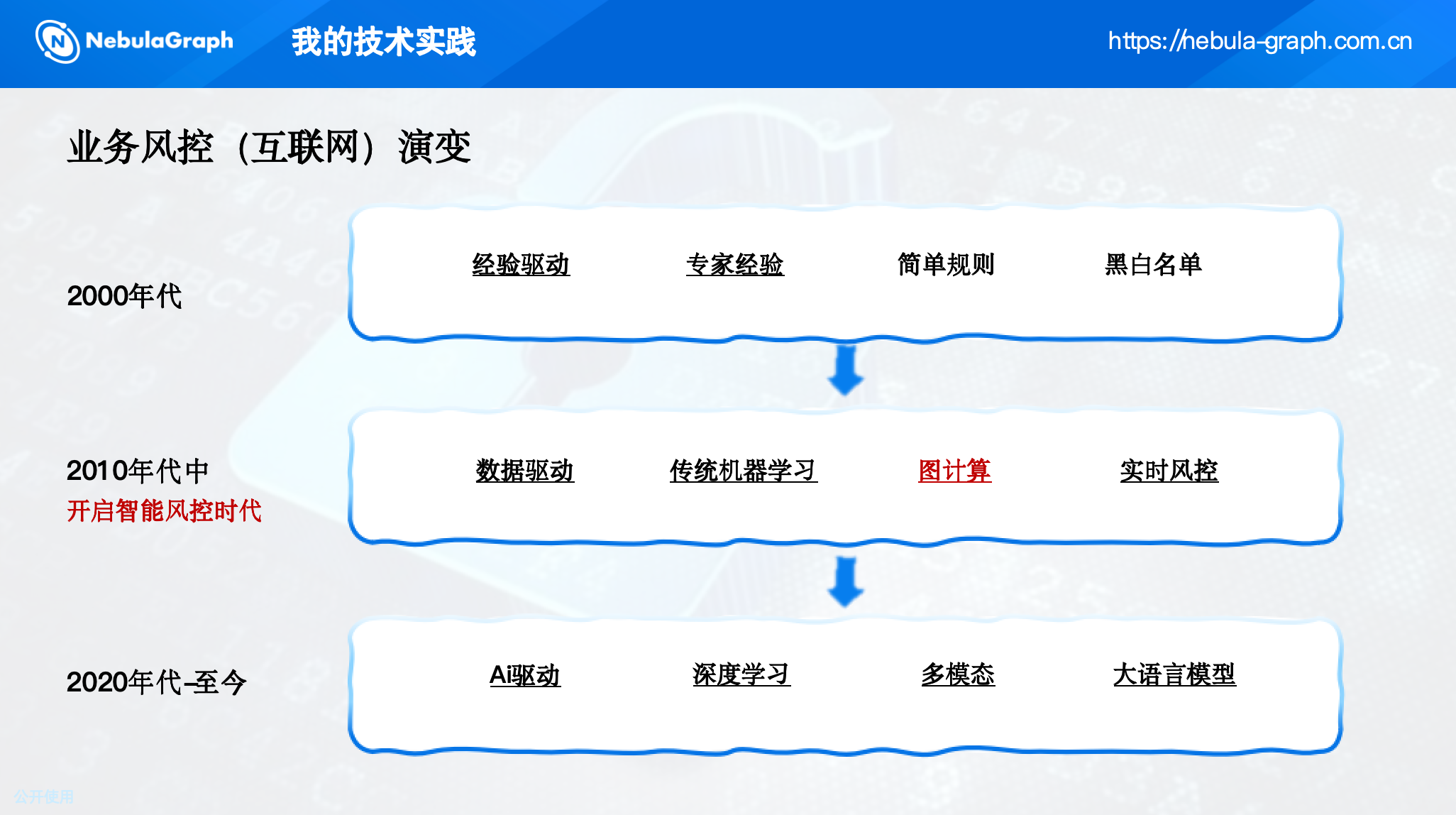
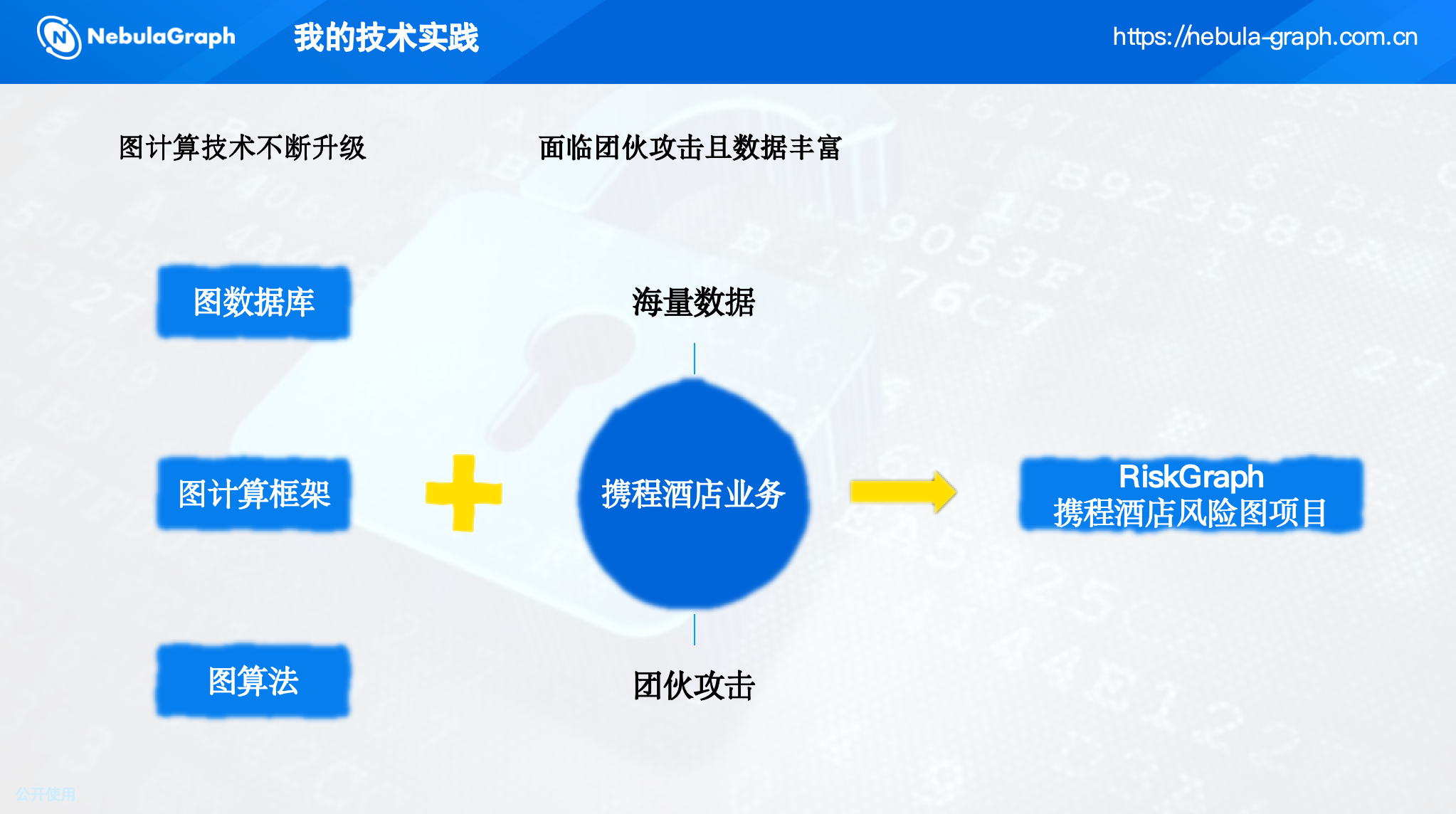
其中,图计算成为挖掘团伙的核心技术,因为它天然擅长刻画海量实体间的关联关系。酒店业务拥有千万亿级的用户行为数据,非常适合引入图技术进行团伙挖掘。
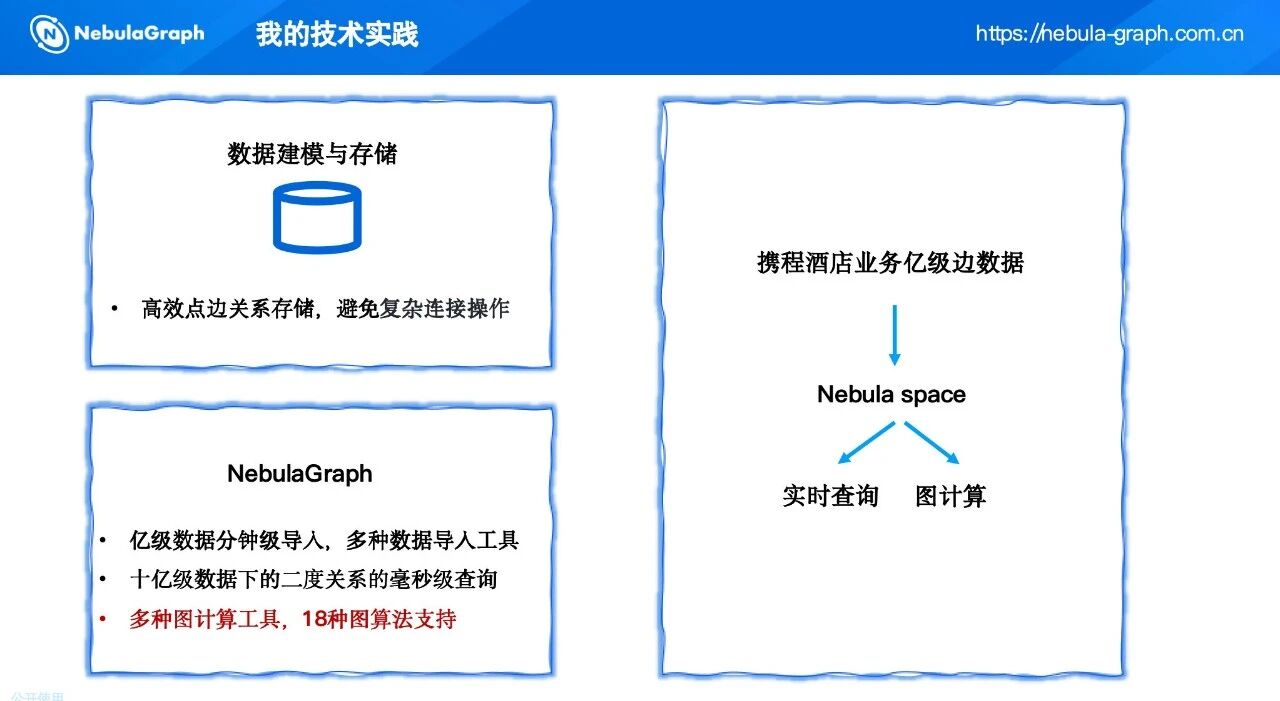
在项目初期,我们调研了市面上七八种图数据库,从数据导入性能、查询延迟、生态完备性等维度进行对比,最终选择了NebulaGraph.
主要原因如下:
- 数据导入性能:酒店业务每天产生亿级行为数据,需要图数据库能够快速导入。NebulaGraph的Exchange工具支持多种数据源(如Hive、Kafka),实测可达到亿级数据分钟导入,满足我们离线批处理的需求。
- 查询性能:风控场景需要实时或近实时的图查询,例如查询一个账号的二度关联关系。NebulaGraph在十亿级边规模下,二度关系查询可达毫秒级延迟,为未来实时风控提供了可能。
- 生态完善:NebulaGraph内置了18种图算法,并提供了与图计算框架的衔接能力。我们可以直接调用内置的连通组件算法进行预计算,再结合外部分布式框架做精细划分,极大降低了开发成本。
- 分布式架构:NebulaGraph原生支持分布式存储和计算,能够水平扩展,与大数据基础设施匹配良好。
为了全面刻画用户间的潜在关联,我们尽可能覆盖用户行为的全链路——从注册登录、酒店预订到履约售后,提取了多个维度的实体和关系。

- 点(实体):主要包括用户账号、设备指纹、IP地址、支付账号、手机号、邮箱等。
- 边(关系):基于业务行为构建了7种以上的边类型,例如:
- 登录关系(账号-设备)
- 支付关系(账号-支付账号)
- 预订关系(账号-订单)
- 通讯关系(账号-手机号)
- 赔付关系(账号-赔付记录)
- ……
不同关系对团伙挖掘的贡献度不同,例如设备共用的权重应高于偶尔的通讯。
因此我们引入了带权重的边,使关系强度更贴近实际业务。权重计算公式为:
边权重(W)=介质类型基础权重×交互频率×时间衰减因子
其中,介质类型基础权重根据业务经验预设(如设备共用权重最高),交互频率指一段时间内关系出现的次数,时间衰减因子采用指数衰减(近期行为权重更高)。
通过这种方式,我们得到了一个包含亿级点、数十亿级边的异构属性图,存储在NebulaGraph的Space中。
团伙挖掘本质上是社区发现问题,即将图中的节点划分为若干个内部紧密、外部稀疏的社区,每个社区可能对应一个黑灰产团伙。
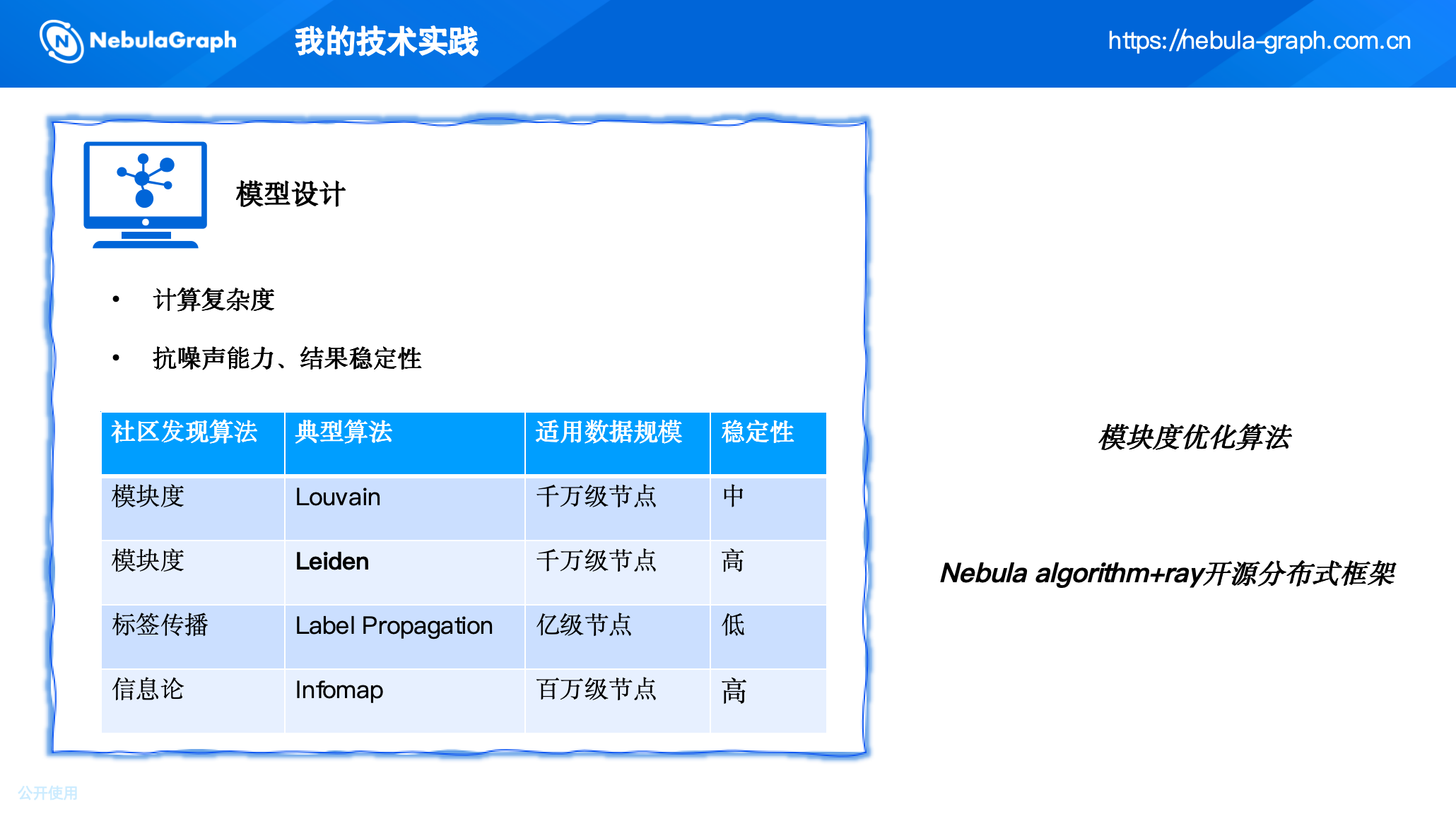
1.Louvain算法及其局限
初期我们尝试了NebulaGraph内置的Louvain算法。
Louvain是一种基于模块度优化的快速社区发现算法,能够处理大规模图。但在业务验证中我们发现一个问题:Louvain可能划分出非连通社区,即两个没有直接或间接边关联的节点被划为同一社区。
这在风控业务中意味着风险定性缺乏依据——如果两个账号没有任何关联,我们不能凭算法输出判定他们属于同一团伙。
2.转向Leiden算法
为了解决非连通问题,我们引入了Leiden算法。Leiden是对Louvain的改进,在迭代过程中保证社区内部的连通性,同时优化模块度。它能够产出完全连通的社区,更符合风控的业务逻辑。
然而,当时Leiden算法只有单机版本(如Python的leidenalg库),面对亿级图数据,单机串行计算耗时长达2-3小时,无法满足日常更新的时效要求。
为了在保证结果连通性的同时提升计算效率,我们做了两个关键优化。
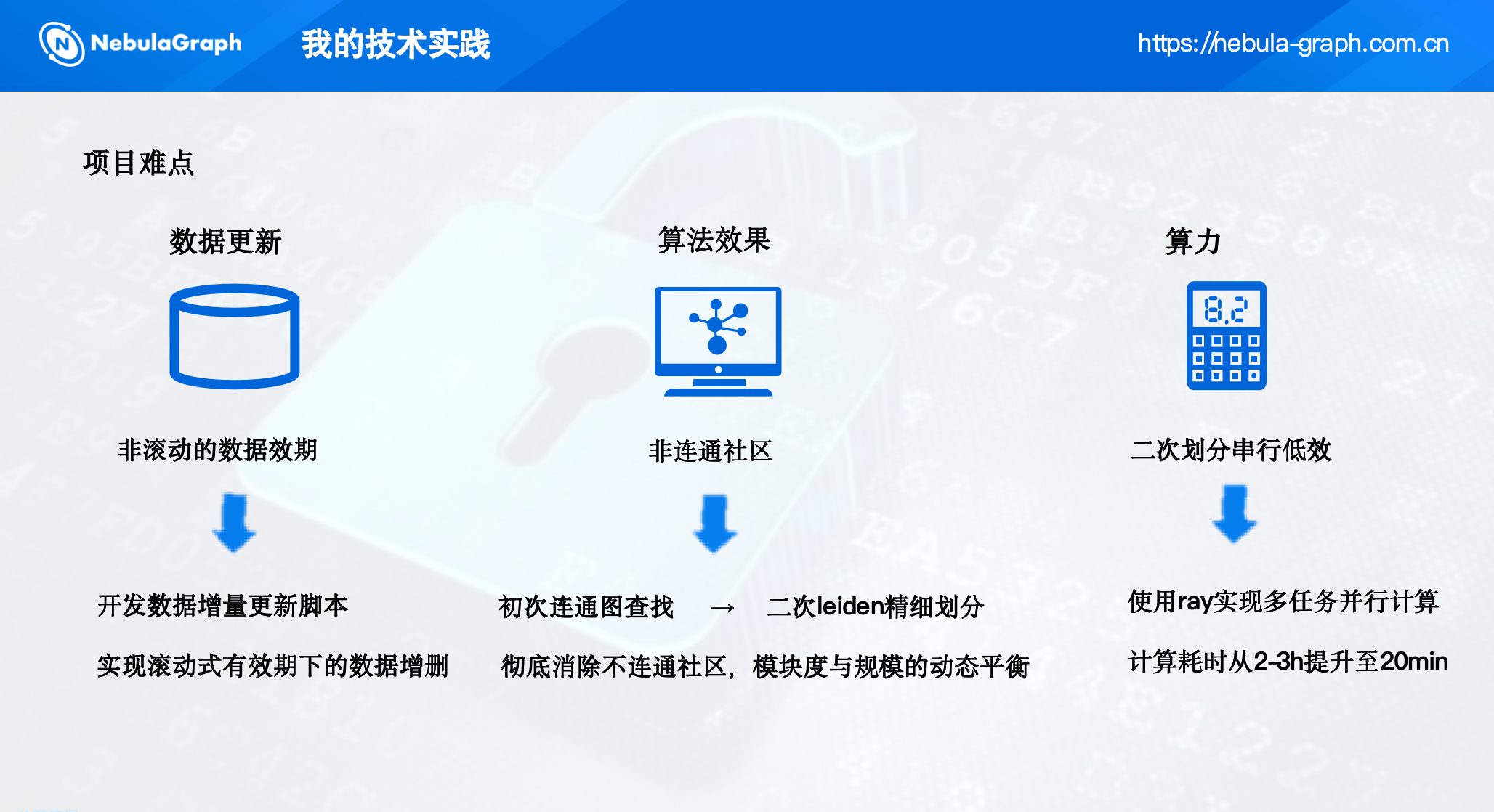
1.利用NebulaGraph进行连通图预划分
Leiden算法在整体图上运行效率低,但我们可以将大图拆解为多个互不连通的子图分别处理。
NebulaGraph内置了连通组件算法,能够快速找出图中所有连通分量。我们首先在NebulaGraph上运行连通组件算法,将原始图拆分为若干连通子图(每个子图内部节点相互可达,子图之间无连接)。
这样,每个连通子图可以独立进行社区发现,且子图规模远小于原图,适合并行处理。
2.引入Ray分布式框架并行计算
在连通子图划分完成后,我们需要对每个子图执行Leiden算法。
单机串行处理依然很慢,因此我们引入了Ray分布式计算框架。通过在公司内部跨团队沟通,我们借用了已有的Ray集群,将Leiden计算任务封装为Ray的远程任务,实现子图级别的并行处理。
具体实现上,我们使用Ray的@ray.remote装饰器将Leiden算法包装为分布式任务,将多个子图的数据分发到不同节点并行执行。得益于Ray的动态调度和容错机制,并行效率大幅提升。
改造后,整体计算耗时从2-3小时降至20分钟,完全满足日常更新的时效要求。
3.数据增量更新机制
业务数据具有时效性,例如用户关系会随时间变化,我们需要支持滚动周期的数据更新。为此,我们开发了一套基于Pythonnebula3客户端的增量更新脚本,实现以下功能:
- 新增数据:每日从数仓抽取新增的行为数据,通过NebulaGraph的nGQL语句插入新点和边。
- 过期数据:根据数据有效期(如90天),删除过期的点和边,保持图数据的时效性。
- 定时调度:将脚本部署在调度系统上,每日自动运行。
通过这种方式,我们实现了滚动式有效期下的数据增删,确保图数据始终反映最新业务状态。
4.完整的模型链路
综上,我们构建了如下模型链路:
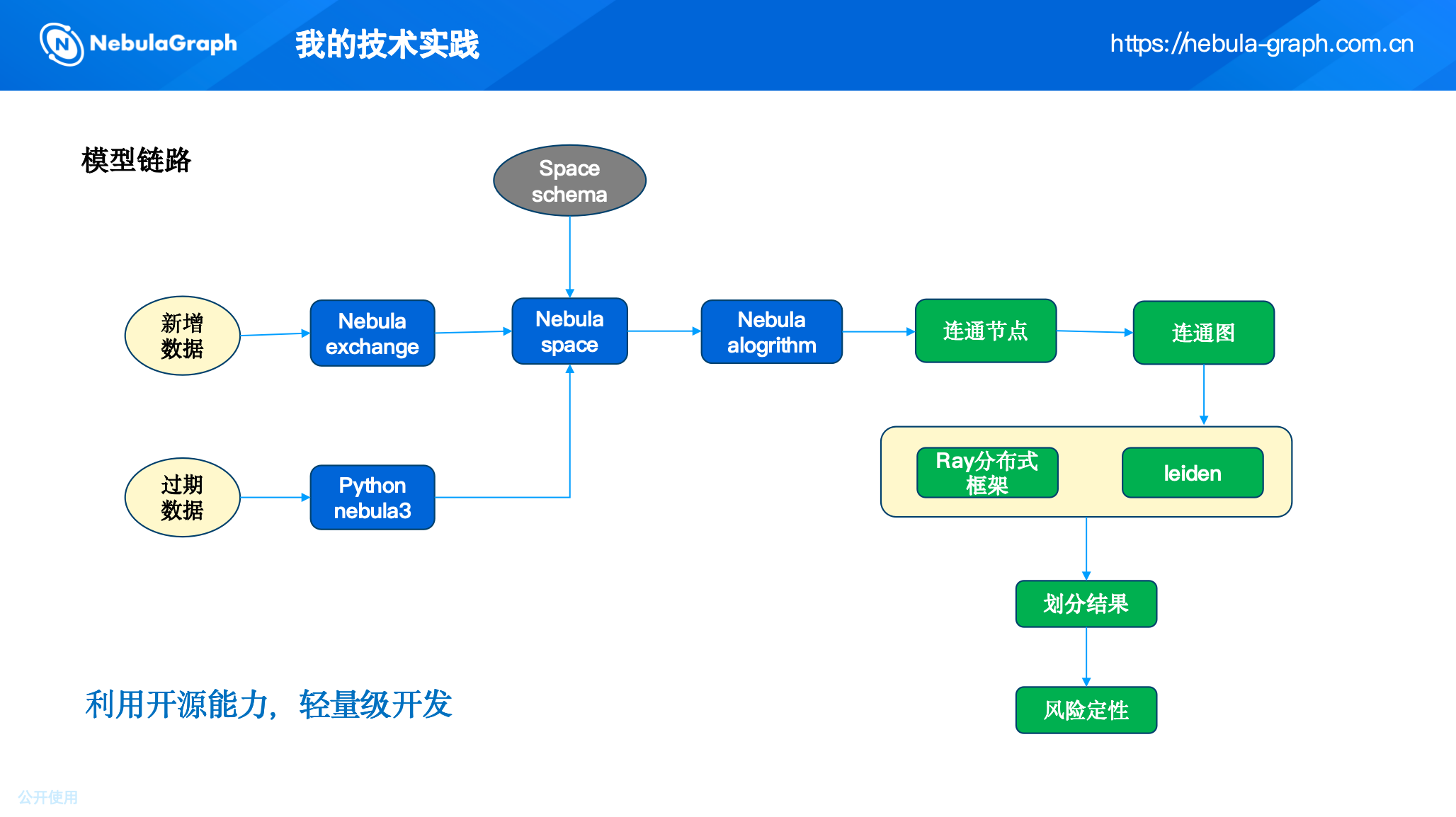
整个链路遵循轻量级开发
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
NanoClaw 开源轻量级个人AI助手 安全可靠的OpenClaw替代方案
MonsterClaw 采用 OpenClaw 技术打造的本地化AI运行平台
TinyClaw 由TinyAGI推出的开源轻量级多智能体协作框架
携程酒店业务借助NebulaGraph实现月均风控止损逾百万元
稀宇科技开源MiniMax Office Skills生产级办公文档引擎
ToClaw由ToDesk打造的专业定制AI智能体
TypeNo 免费开源的中文AI语音输入法 无需配置直接使用
Sub2API 开源人工智能API中转网关平台 具备多账户管理功能
阿里通义推出视频生成音频框架PrismAudio
Luma AI发布Uni-1模型实现图像理解与生成一体化
AI精选