

用一份“豪车购买预测数据”,带你玩转 Pandas
作者:互联网
2026-03-24
 AI模型库
AI模型库
无论你是数据分析新手,还是准备进入机器学习领域,Pandas 都是必须掌握的核心工具。今天,我们不讲枯燥理论,而是借助一份 真实案例数据——豪华汽车购买预测,带你从基础到建模一站式掌握 Pandas的常用操作与实战思维。
只要认真看完这篇文章,你会发现:
- Pandas并没有想象中那么难
- 原来数据分析流程就这么几步
- 机器学习建模也能变得很轻松
让我们开始吧!

1. 什么是Pandas?为什么人人都在用?
Pandas是Python中最强大的表格数据处理库,它能让你:
- 轻松读取 CSV、Excel、数据库
- 快速筛选、统计、清洗数据
- 让数据处理更像“操作Excel”一样自然
- 和机器学习框架(如 scikit-learn)无缝衔接
别人处理100W条数据可能要写几十行代码,而Pandas两三行就能搞定。
2. 准备数据:豪车购买预测表
汽车公司推出了新款豪华汽车,并收集了一批用户数据:
序号 | 预估薪资 | 是否会购买 |
1 | 43000 | 0 |
2 | 150000 | 1 |
3 | 57000 | 0 |
... | ... | ... |
目标很简单:根据“预估薪资”预测用户是否会购买豪车。
下面我们从Pandas开始,一步步完成这道机器学习题。
3. 从数据开始:Pandas 核心用法
(1) 读取数据
import pandas as pd
df = pd.read_csv('car_users.csv')- 1.
- 2.
Pandas会自动生成一个DataFrame(二维表格)。
(2) 数据清洗常用方法
df.isnull().sum() # 查看缺失值
df.dropna() # 删除缺失
df.fillna(0) # 填充缺失
df.drop_duplicates() # 去重
df.rename(columns={'旧名': '新名'}) # 改列名- 1.
- 2.
- 3.
- 4.
- 5.
(3) 查看数据结构
df.head() # 查看前5行
df.info() # 查看每列类型
df.describe() # 查看薪资的统计信息- 1.
- 2.
- 3.
只需三行代码,你就能对数据有完整的“第一印象”。

(4) 选择数据
选择一列:
df['预估薪资']- 1.
选择多列:
df[['预估薪资', '是否会购买']]- 1.
条件筛选:
df[df['预估薪资'] > 80000]- 1.

4. 数据建模
上面演示了数据读取和探索,现在我们来完成一个完整的训练模型流程。
(1) 划分特征 X 和标签 y
X = df[['预估薪资']]
y = df['是否会购买']- 1.
- 2.
- X 必须是二维
- y 是目标变量,只需要取一列
(2) 按 8:2划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)- 1.
- 2.
- 3.
- 4.
- 5.
- test_size=0.2 表示 20% 数据用于测试
- random_state 用于结果可复现
(3) 转换为二维数组
X_train = X_train.values
X_test = X_test.values- 1.
- 2.
为什么要这一步?
因为sklearn期望输入二维数组,而Pandas的Series是一维的。
(4) 定义逻辑回归模型并训练
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)- 1.
- 2.
- 3.
- 4.
逻辑回归非常适合二分类问题,例如“买/不买”。
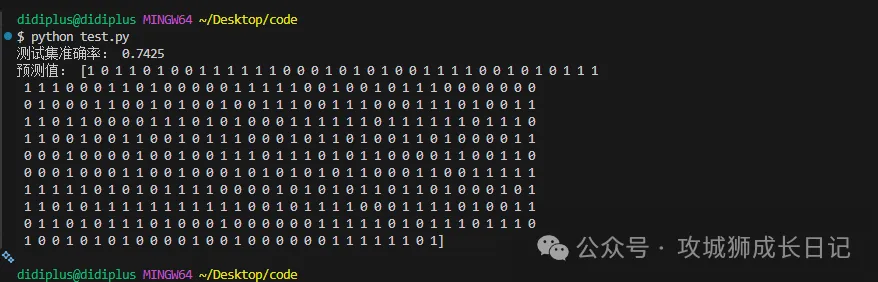
(5) 输出测试集准确率
print("测试集准确率:", model.score(X_test, y_test))- 1.
准确率越高,说明薪资与购买行为的关系越明显。
(6) 输出预测结果
y_pred = model.predict(X_test)
print("预测值:", y_pred)- 1.
- 2.
这就是模型对测试集所有用户的预测结果。
5. 小结
通过“豪车购买预测”这一贴近真实业务的案例,系统展示了如何使用Pandas进行数据读取、探索、清洗与特征处理,并进一步结合逻辑回归完成完整的机器学习建模流程。
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
NanoClaw 开源轻量级个人AI助手 安全可靠的OpenClaw替代方案
MonsterClaw 采用 OpenClaw 技术打造的本地化AI运行平台
TinyClaw 由TinyAGI推出的开源轻量级多智能体协作框架
携程酒店业务借助NebulaGraph实现月均风控止损逾百万元
稀宇科技开源MiniMax Office Skills生产级办公文档引擎
ToClaw由ToDesk打造的专业定制AI智能体
TypeNo 免费开源的中文AI语音输入法 无需配置直接使用
Sub2API 开源人工智能API中转网关平台 具备多账户管理功能
阿里通义推出视频生成音频框架PrismAudio
Luma AI发布Uni-1模型实现图像理解与生成一体化
AI精选