

Representation‑as‑a‑Judge | 不用GPT‑5也能当裁判!小模型颠覆 LLM-as-a-Judge范式
作者:互联网
2026-03-24
 ⼤语⾔模型脚本
⼤语⾔模型脚本

今天给大家分享一篇发表在2026 ICLR上非常有启发性的论文——重新思考LLM‑as‑a‑Judge,作者来自平安科技、匹兹堡大学、马里兰大学等。
这篇论文的核心观点是:小模型虽然生成很拉胯,但藏在隐层里的“评估能力”却很强,完全能当靠谱裁判。
论文地址:https://arxiv.org/pdf/2601.22588
项目地址:https://github.com/zhuochunli/Representation-as-a-judge- 1.
- 2.
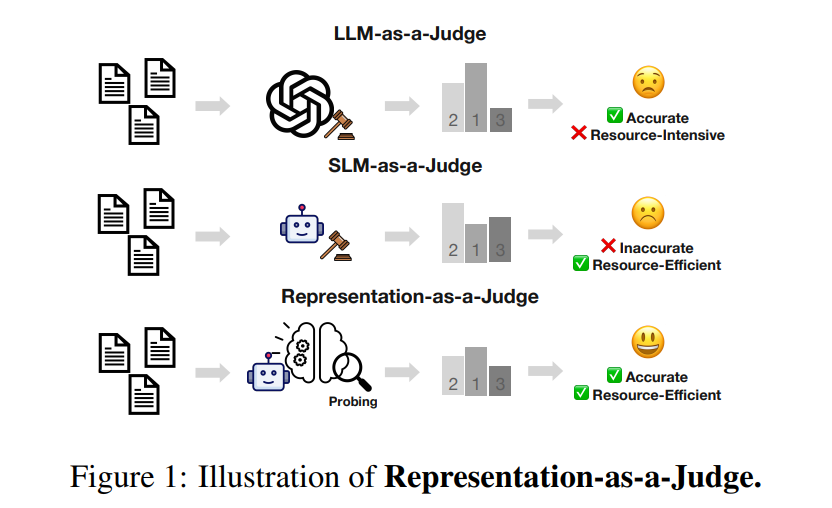
01、先看痛点:现在的LLM‑as‑a‑Judge太“贵”了
现在做无参考文本评估,基本都用LLM‑as‑a‑Judge——直接让GPT‑4、DeepSeek这类大模型当裁判打分。
但它有三个绕不开的问题:
- 成本高:自回归解码,算得慢、花钱多
- 不透明:闭源大模型内部怎么判的,完全看不见
- 不稳定:换个prompt,分数就飘,很难复现
直接给小模型写 prompt 当裁判?结果很惨 —— 小模型生成能力弱,评估结果一塌糊涂。
但这篇论文发现了一个关键现象:
小模型不是不懂评估,只是“说不明白”,评估信号早就藏在隐层里了。
02、核心假说:语义容量不对称
这篇工作最精彩的地方,是提出了一个简洁又有力的理论:
?语义容量不对称假说
评估任务需要的语义容量 << 文本生成需要的语义容量
小模型即使生成很差,中间层表征也足够支撑高质量评估。
简单说:
- 生成:要谋篇布局、长依赖、流畅表达,对容量要求极高
- 评估:只要判断对不对、通不通、乱不乱,中间层特征就够了
所以:小模型生成不行,但评估完全可以行。
基于这个想法,作者提出了一套全新范式:
? Representation‑as‑a‑Judge(表征裁判)
不靠生成文本,直接探查模型内部隐层表征做评估。
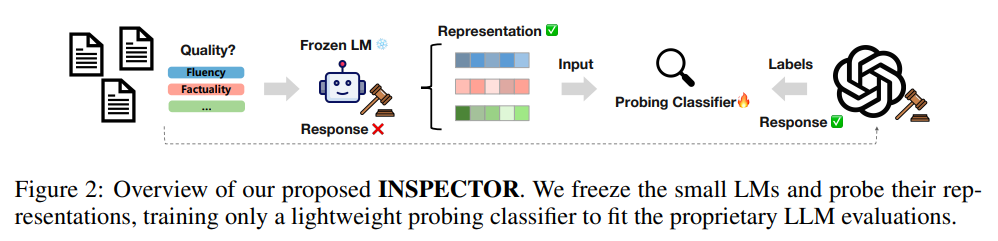
03、怎么实现?INSPECTOR框架
这个思路做成了可落地的框架--INSPECTOR,流程如下:
大模型评估标注
先用强 LLM 给一批样本打 “标准答案分数”。
评估维度:5 个通用维度
- 语义一致性
- 逻辑性
- 信息完整性
- 流畅性
- 事实准确性
简单来说,整个流程如下:
- 首先选取 GSM8K、MATH、GPQA 三个数学与科学推理基准数据集构建评估样本;
- 利用中等规模模型针对数据集中的问题生成对应回复,形成待评估样本;
- 使用顶尖大模型对每个样本在多个维度上进行 1–5 分打分,并将打分结果作为金标准标签;
- 由于中等模型在处理难度差异较大的问题时,会出现难题回复普遍错误、简单题回复准确率较高的情况,导致样本分数分布不均衡,因此通过对 1–5 分各分数段执行均衡下采样,统一各分数段样本数量以避免标签偏倚。
注意,选用中等模型生成回复是刻意设计的环节,目的是获取质量分布丰富、包含优劣不同结果的样本,确保探针能够有效学习评估信号。
小模型隐层探针
这是整篇论文的技术核心:
- 输入预处理 & 隐状态提取:把评估提示喂给小模型(0.6B/1.7B/1B/8B),完整采集每一层隐状态 + 注意力权重
- 多策略池化:把变长的 token 级隐状态,转化为固定长度的向量,包括5种池化方式 均值、末位、最小、最大、拼接
- 补充统计特征:除了隐状态本身,再补充能反映表征分布的统计特征,提升评估鲁棒性
注意力特征:对每一层每个注意力头计算「注意力熵」(衡量注意力分布的均匀性),再汇总成均值、标准差、最大值
池化向量统计特征:对每个池化后的向量,计算范数(向量长度)、方差(数值波动)、熵(分布复杂度) - 特征组装 & 降维:把「PCA 降维后的池化向量」+「统计特征」+「注意力摘要」沿特征维度拼接,形成最终特征矩阵。
小模型隐维度通常是 768/1024,直接用维度太高,训练数据少(每个分数段不足 100 样本)易过拟合 - 逐层探针测试 & 层排序:定位小模型哪一层的表征,最能拟合大模型的金标准分数
一句话:用小模型隐层特征,预测大模型裁判的分数。
训练探针分类器
- 选 Top‑K 最优层
- 多层特征拼接
- 训练轻量分类器(逻辑回归最好用)
- 得到一个超小、超快、可解释的评估器
最终效果:只看小模型隐层,不生成任何文字,就能逼近大模型裁判精度。
04、实验结果
论文在 GSM8K / MATH / GPQA 三个数学推理基准上做了大量实验,结论如下:
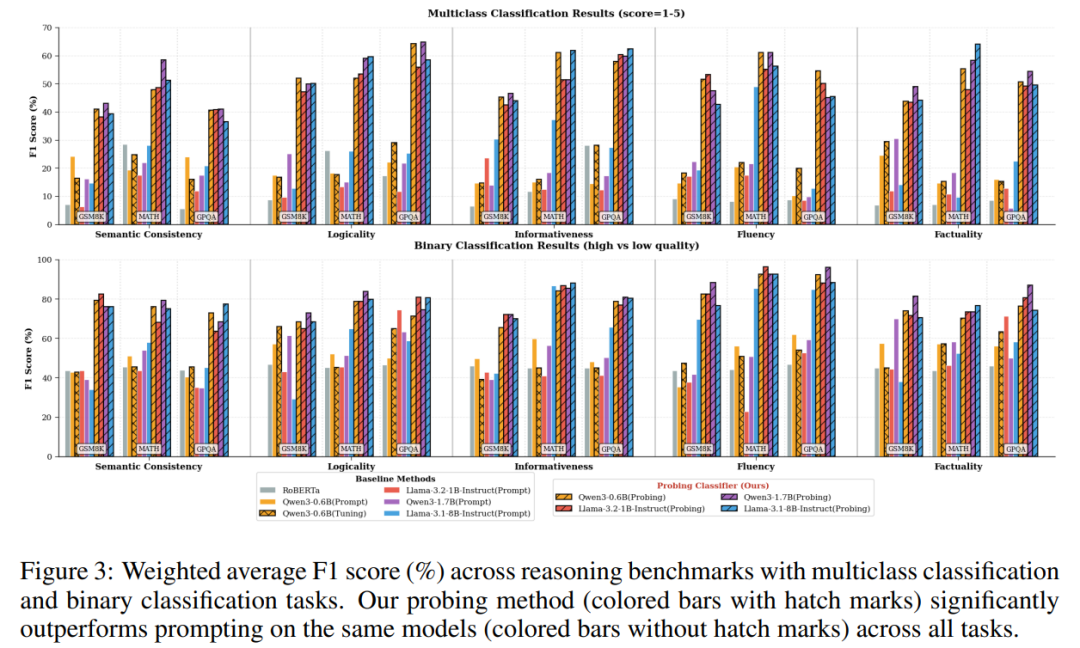
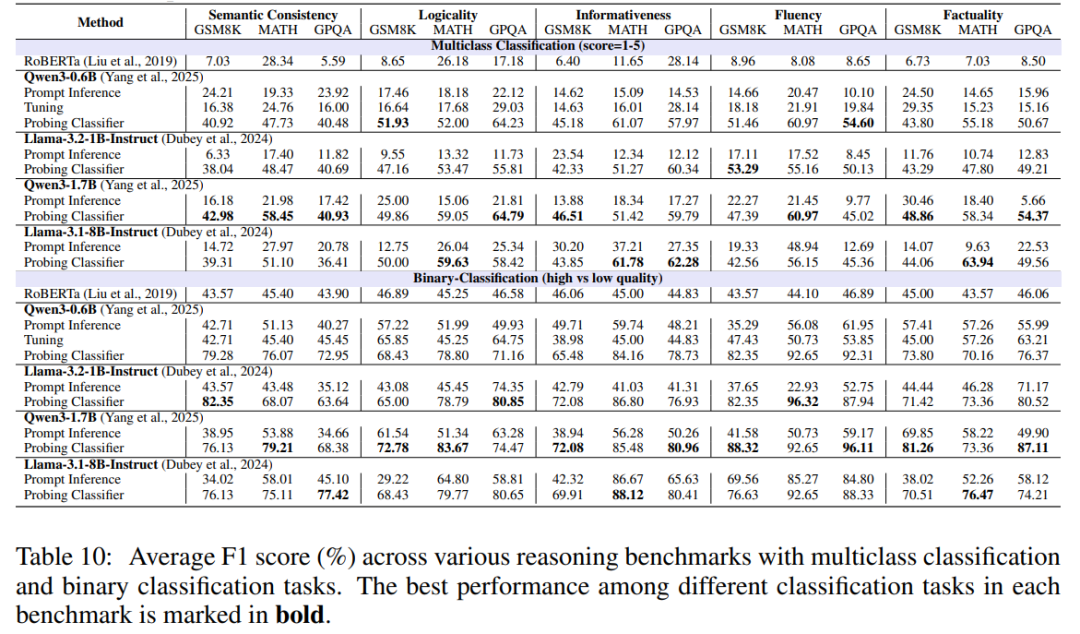
1. 探针 >> 直接 prompt
不管是 Qwen3 0.6B/1.7B,还是 Llama 1B/8B,探针方式都大幅超越提示式评估。
说明:
- 小模型不是没能力,是生成环节把信号弄丢了
- 内部表征比表层输出更可靠
2. 模型越大 ≠ 评估越强
很反直觉,但实验实锤:
- 8B 模型不一定比 1.7B 强
- 同一系列里,规模和评估能力不成正比
- 不同模型在不同维度各有优势
这意味着:评估不需要无脑堆参数量。
3. 二分类探针结果可靠
多分类(1–5分)大概50%–60% F1,符合预期,拟合大模型本来就难;
但二分类(高质量/低质量)F1可以达到80%–90%。
这意味着:
小模型探针可以当高性价比的数据过滤器。
4. 泛化性强
在 AlpacaEval 2.0 上同样有效,证明不局限于推理任务,通用生成也能打。
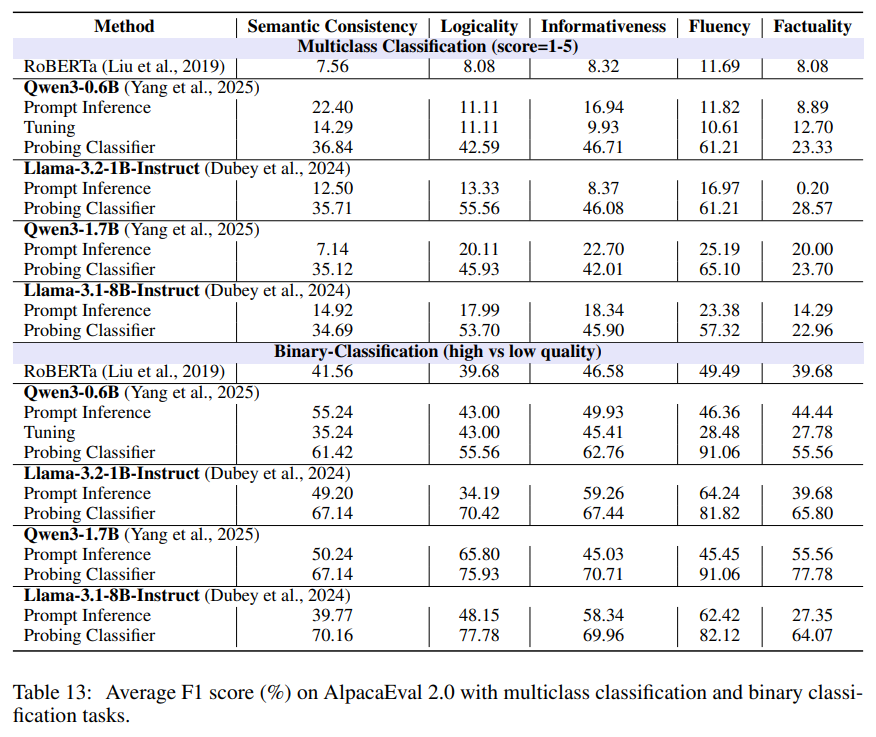
05、深度分析
1. 池化与分类器消融实验
作者在 MATH 数据集的信息完整性维度,对 Qwen3-0.6B 和 Llama-3.2-1B-Instruct 做了系统的二分类消融实验。
关键结论:
- 均值池化(mean pooling)显著优于其他所有池化均值能在保留全局信息的同时,得到紧凑稳定的特征,最适合评估任务。
- 逻辑回归 > 随机森林、MLP、线性 SVM在小数据、带噪声的 LLM 评分标签下,逻辑回归的概率校准 + 正则化能带来更稳定的 F1。
结果展示:简单 = 更强,复杂探针并不比 “均值池化 + 线性分类器” 更好。
最终,全数据集、全维度、全模型的最优配置几乎都是:均值池化 + 逻辑回归。
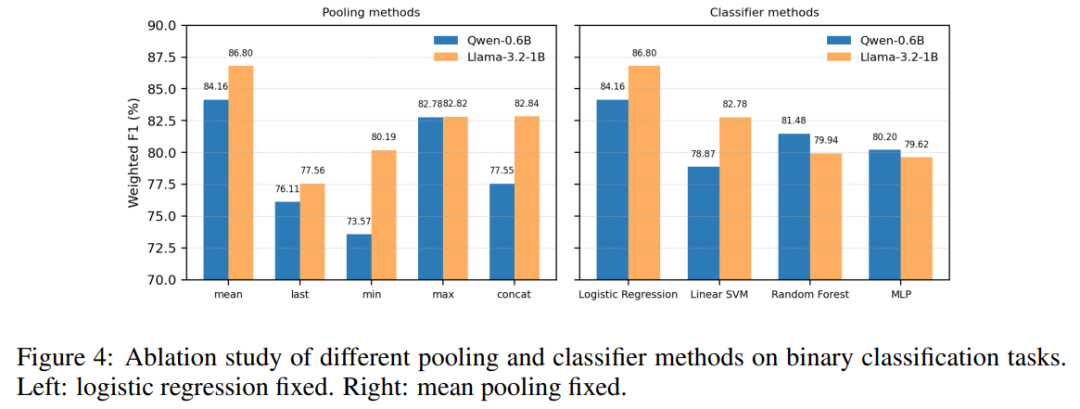
2. 数据筛选 + SFT:探针筛选 ≈ 大模型筛选
把训练好的 Qwen3-1.7B 探针用在知识蒸馏 + 有监督微调场景:
对每条模型回复,探针分类器先在五个评估维度分别输出 0/1 二分类得分,求和得到 0–5 的总分;按总分从高到低排序构建训练集,再以10% 为步长逐步扩大数据量,完成学生模型的有监督微调。
- 教师:Llama-3-8B-Instruct
- 学生:Llama-2-7B-Chat
- 对比:DeepSeek-V3 筛选 / 随机筛选
三条关键结论:
1)探针筛选 ≈ 大模型筛选用探针筛出来的数据训模型,效果几乎追平 DeepSeek-V3 裁判。
2)质量筛选 >> 随机筛选证明高质量数据对下游训练至关重要。
3)小数据看质量,大数据看数量曲线呈现 “上升–下降–回升”:
- 数据少时:质量决定上限
- 数据变大:数量逐渐主导
这意味着:探针可以直接放进工业级数据清洗流水线。
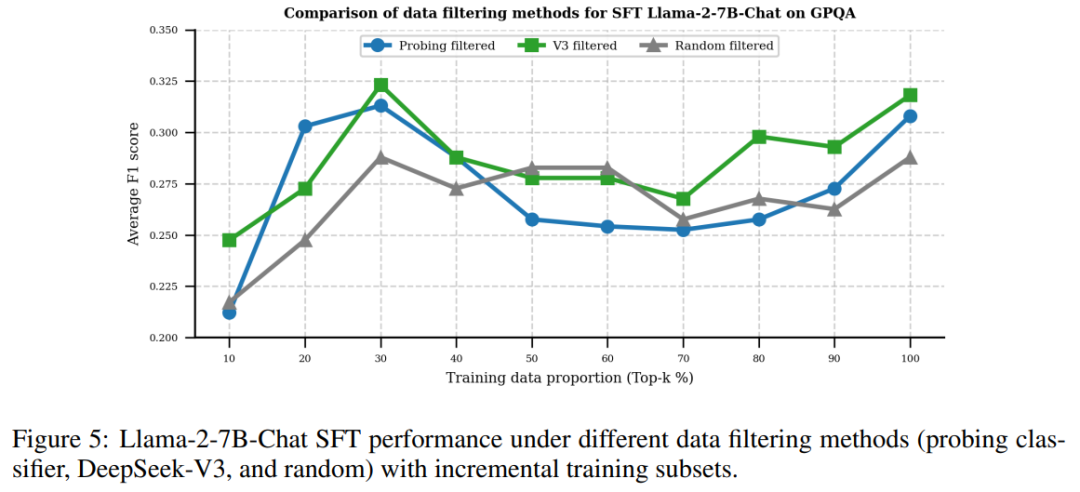
3. 中间表征里的评估信号
为了解释 “小模型为什么能评估”,作者做了逐层探针分析,把 5 个维度的信号分布全部画了出来:
(1)事实准确性 Factuality + 语义一致性 Semantic Consistency
- 信号主要集中在模型中上层
- 越靠近输出层越强
- PCA 特征 >> 统计特征 + 注意力特征直接证明:小模型中间层就包含强评估信号,不需要等到输出层。
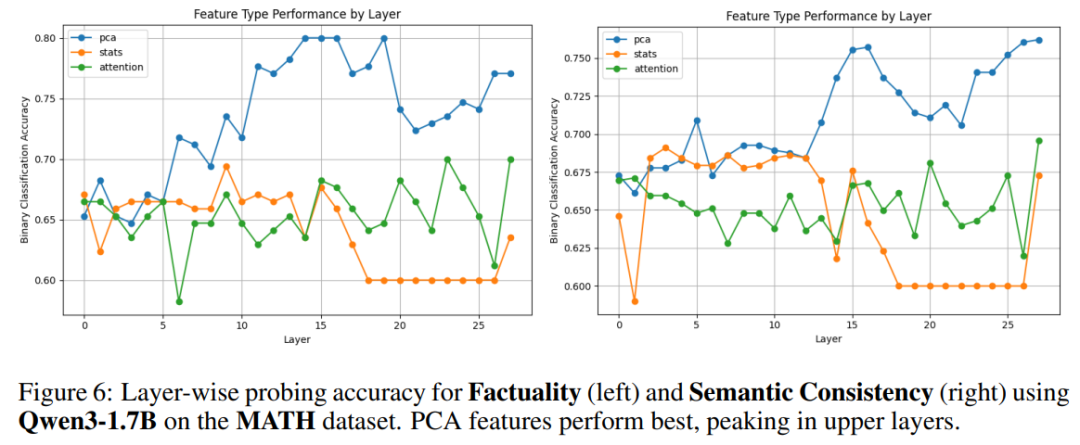
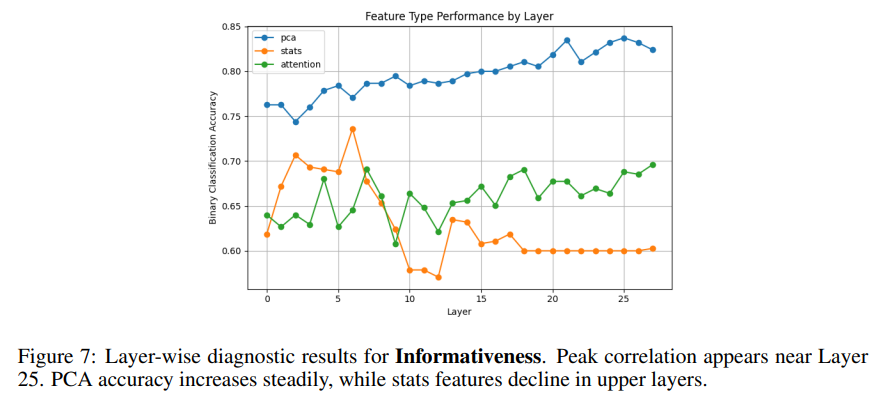
(2)信息完整性 Informativeness
- 评估信号主要集中在模型中层
- 中层已经能捕捉 “步骤够不够、全不全”
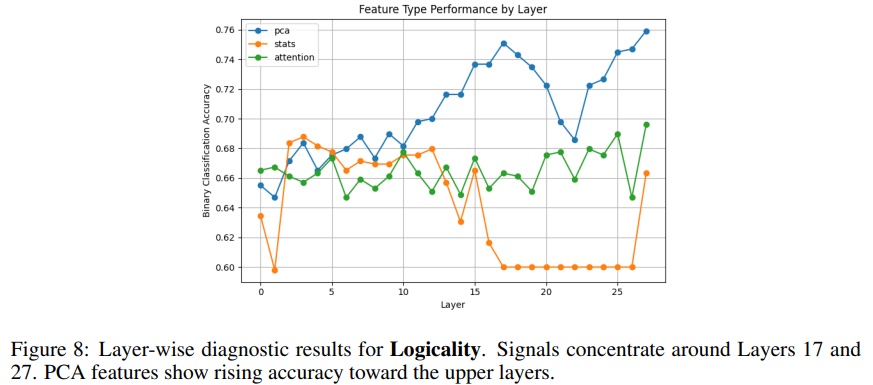
(3)逻辑性 Logicality
- 在第 17 层、第 27 层出现两个明显峰值
- 越深层信号越强说明:逻辑推理这类高级语义,藏在模型深层。
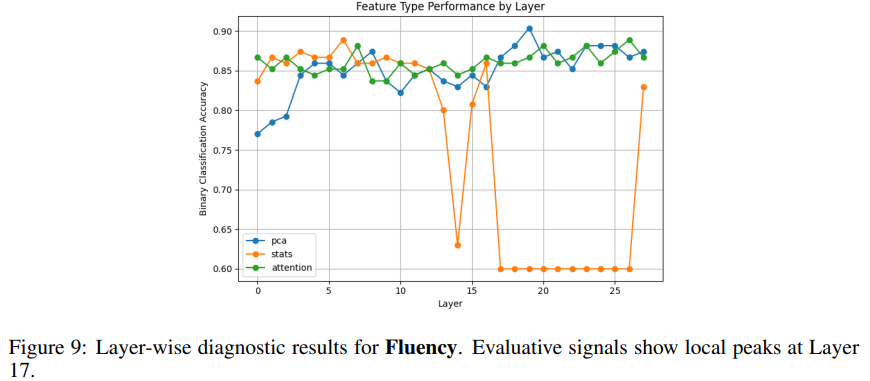
(4)流畅性 Fluency
在第 17 层附近达到最强峰说明:流畅性这种浅层语言特征,在中层就被稳定编码。
4. 最终理论:语义容量不对称假说
所有层信号、消融、SFT 结果,共同指向一个真理:
评估需要的语义容量 << 生成需要的语义容量
- 生成:需要篇章规划、长程依赖、流畅输出 → 高容量
- 评估:只需要识别错误、矛盾、缺失、事实偏差 → 低容量
- 这些判别信号在中间表征就已存在,不需要走完解码生成
这就是为什么:小模型生成拉胯,却能当好 “裁判”。
06、总结
本研究提出的Representation-as-a-Judge(表征裁判)范式,很有启发的一篇工作,适用于文本生成质量评估、数据筛选与清洗、大模型对齐数据过滤、有监督微调前的数据质量打分等低成本、无参考评估的场合。
但是该研究在实验验证上仍存在一定欠缺,尤其缺乏对 Representation-as-a-Judge 范式输出分数可靠性的细粒度分析。例如,探针模型在高分段样本与低分段样本上的预测准确性并未分别验证,无法明确其在高置信度样本上是否稳定可靠、在低质量样本上是否存在误判;同时也未对预测分数的排序一致性、分数误差分布等进行深入分析,难以全面衡量探针输出的评分是否真正具备与 LLM-as-a-Judge 一致的判别能力。这些内容的缺失使得探针打分的可信度与实用性未能得到充分支撑。
另外,对于评估精度要求高、同时待评估数据量极大的场景,Representation-as-a-Judge 可以与 LLM-as-a-Judge 形成分级评估 pipeline:先用轻量高效的 Representation-as-a-Judge 探针对海量样本进行快速初筛,剔除明显低质量、错误或无效的内容;再将初筛后保留的高质量候选样本,交给 LLM-as-a-Judge 进行细粒度、高精度终审。这种结合方式既利用探针实现了大规模数据的低成本快速过滤,大幅减少需要大模型参与评估的样本数量,又依靠大模型裁判保证最终结果的准确性,在效率与精度之间实现最优平衡。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据

相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
10款免费AI语音输入工具与软件 轻松实现语音转文字
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
SkyBot由Skywork研发的云电脑AI助手
AI Agent 智能体 - Multi-Agent 架构入门
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
一文搞懂卷积神经网络经典架构-LeNet
一文搞懂深度学习中的池化!
AI精选