

线程同步全解析:mutex、条件变量、读写锁、死锁,一次全搞懂
作者:互联网
2026-03-24
 ⼤语⾔模型脚本
⼤语⾔模型脚本
上一篇讲了进程与线程的创建原理。
有了线程,就有了一个新问题:多个线程同时访问共享数据,会出什么事?
int counter = 0; // 共享变量
void *inc(void *arg) {
for (int i = 0; i < 100000; i++)
counter++; // 看起来一行,实则三条指令
return NULL;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
两个线程跑完,counter 应该是 200000。实际运行一下:
$ ./a.out
counter = 153271 // 每次不一样,必然不到 200000- 1.
- 2.
这就是竞态条件(Race Condition)——这篇文章要解决的核心问题。

一、为什么 counter++ 不是原子的?
counter++ 在汇编层面是三条指令:
LOAD r0, [counter] // 把 counter 读到寄存器
ADD r0, r0, 1 // 加 1
STORE [counter], r0 // 写回内存- 1.
- 2.
- 3.
两个线程同时执行,可能出现这种情况:
线程A:LOAD r0=5
线程B:LOAD r0=5
线程A:ADD r0=6
线程B:ADD r0=6
线程A:STORE counter=6 ← A 的结果被 B 覆盖
线程B:STORE counter=6 ← 本该是 7,实际是 6- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
两次 ++,只加了 1。这就是竞态,解决它需要同步机制。
二、mutex:最基础的互斥锁
mutex(互斥量)是最常用的同步原语,保证同一时刻只有一个线程能进入临界区。
原理很简单:进入临界区前加锁,离开后解锁。如果锁已被持有,其他线程阻塞等待。
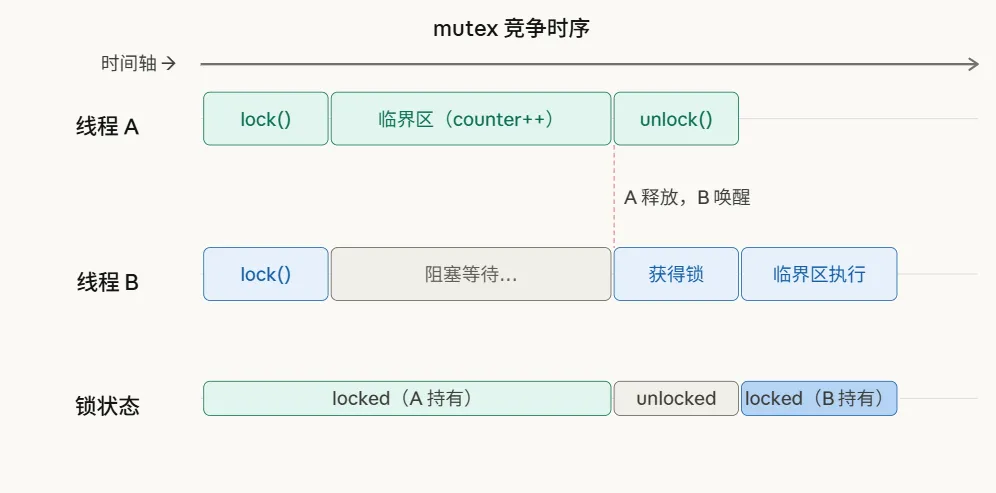
从时序图可以清楚看到:线程 B 在 A 持锁期间只能阻塞等待,A 释放锁后 B 才能进入临界区,两者的临界区执行绝对不会重叠。
pthread_mutex_t mu = PTHREAD_MUTEX_INITIALIZER;
int counter = 0;
void *inc(void *arg) {
for (int i = 0; i < 100000; i++) {
pthread_mutex_lock(&mu);
counter++; // 临界区
pthread_mutex_unlock(&mu);
}
return NULL;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
加锁之后,counter 结果稳定是 200000。
注意两个坑:
- 一是锁的粒度要尽量小——lock 和 unlock 之间只放必须保护的代码,不要把耗时操作(IO、sleep)放进去,否则其他线程全部干等。
- 二是必须配对——加了锁一定要解锁。C++ 里推荐用 std::lock_guard 或 std::unique_lock 自动管理,防止中间 return 或异常导致锁没释放:
std::mutex mu;
void safe_inc() {
std::lock_guard<std::mutex> lg(mu); // 自动加锁
counter++;
} // 函数返回时自动解锁,不管是 return 还是异常- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
三、条件变量:让线程优雅地等待"某个条件"
mutex 解决了互斥问题,但有些场景需要线程等待某个条件成立才继续执行,比如生产者-消费者模型:消费者发现队列为空,应该等待而不是一直轮询。
如果用轮询:
// 错误示例:忙等,浪费 CPU
while (queue_empty()) { /* spin */ }- 1.
- 2.
CPU 100% 空转,不可接受。
条件变量(pthread_cond_t)配合 mutex,让等待的线程进入睡眠,直到另一个线程发出信号才唤醒,实现零 CPU 消耗的等待。
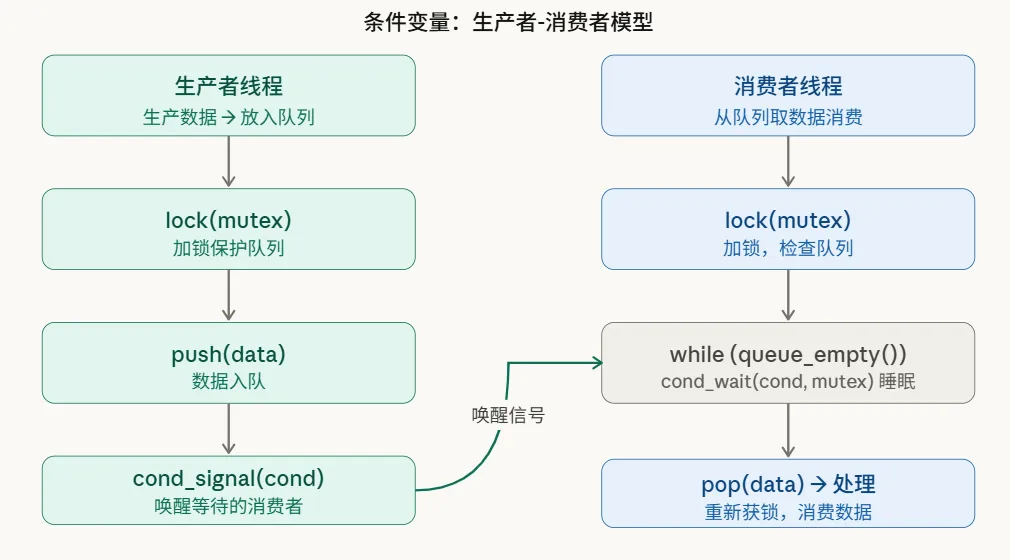
代码模板如下:
pthread_mutex_t mu = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
// 消费者
pthread_mutex_lock(&mu);
while (queue_empty()) // 注意:必须用 while,不能用 if
pthread_cond_wait(&cond, &mu); // 原子地:释放锁并睡眠
item = queue_pop();
pthread_mutex_unlock(&mu);
// 生产者
pthread_mutex_lock(&mu);
queue_push(item);
pthread_cond_signal(&cond); // 唤醒一个等待者
pthread_mutex_unlock(&mu);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
这里有个极其重要的细节:消费者必须用 while 而不是 if。因为 cond_wait 返回后需要重新检查条件——可能存在虚假唤醒(spurious wakeup),也可能多个消费者同时被唤醒但只有一份数据。用 while 确保条件真正满足才继续。
四、读写锁:读多写少场景的性能救星
如果共享数据大多数时候只是被读取,偶尔才写入,mutex 就太保守了——它连并发读都不允许。
读写锁(rwlock) 解决这个问题,规则很简单:
- 读锁:多个线程可以同时持有(并发读)
- 写锁:独占,持有写锁时没有任何读/写锁
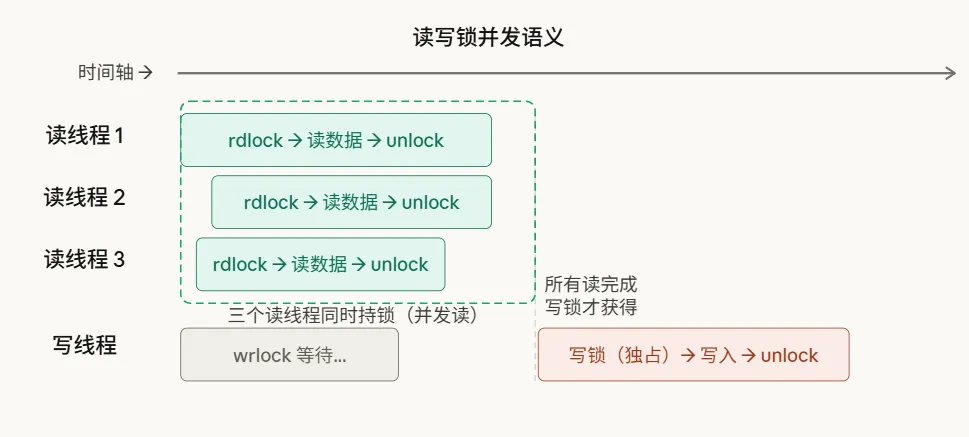
pthread_rwlock_t rwlock = PTHREAD_RWLOCK_INITIALIZER;
// 读者(多个可同时持有)
pthread_rwlock_rdlock(&rwlock);
read_data();
pthread_rwlock_unlock(&rwlock);
// 写者(独占)
pthread_rwlock_wrlock(&rwlock);
write_data();
pthread_rwlock_unlock(&rwlock);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
读写锁适合读多写少的场景,比如配置缓存、路由表、DNS 缓存。如果写操作频繁,读写锁反而比 mutex 慢,因为它维护的状态更复杂。
五、死锁:最难调试的并发 bug
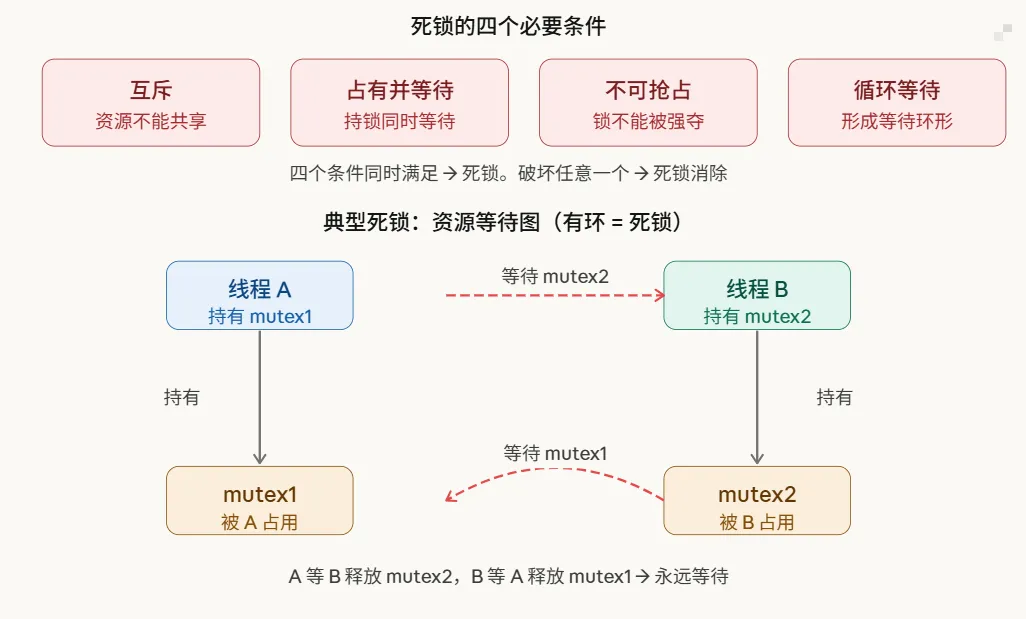
死锁是指两个或多个线程相互等待对方释放锁,导致所有人都永远卡住。
教科书经典案例:哲学家就餐问题。这里用更贴近实际的例子说明:
线程 A:lock(mutex1) → 等待 lock(mutex2) ...
线程 B:lock(mutex2) → 等待 lock(mutex1) ...- 1.
- 2.
两人各持一把锁,都在等对方先放手——永远等不到。
死锁产生需要同时满足四个必要条件,缺一不可:
1. 死锁的代码复现
pthread_mutex_t m1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t m2 = PTHREAD_MUTEX_INITIALIZER;
void *thread_a(void *arg) {
pthread_mutex_lock(&m1);
sleep(1); // 故意让出 CPU,制造时序问题
pthread_mutex_lock(&m2); // 等待 B 释放 m2,但 B 在等我
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
returnNULL;
}
void *thread_b(void *arg) {
pthread_mutex_lock(&m2);
sleep(1);
pthread_mutex_lock(&m1); // 等待 A 释放 m1,但 A 在等我
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
returnNULL;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
程序运行后永远卡住,ps 可以看到两个线程状态都是 S(睡眠)。
2. 如何避免死锁
(1) 方法一:固定锁的顺序(最简单最常用)
所有线程始终按照相同的顺序加锁,就不会形成循环等待:
// 规定:全程按 m1 → m2 的顺序加锁
void *thread_a(void *arg) {
pthread_mutex_lock(&m1); // 先 m1
pthread_mutex_lock(&m2); // 再 m2
/* ... */
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
}
void *thread_b(void *arg) {
pthread_mutex_lock(&m1); // 先 m1(和 A 一样)
pthread_mutex_lock(&m2); // 再 m2
/* ... */
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
(2) 方法二:尝试加锁 + 超时回退(trylock)
while (1) {
pthread_mutex_lock(&m1);
if (pthread_mutex_trylock(&m2) == 0) {
// 成功获取两把锁,执行业务
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
break;
}
// m2 获取失败,释放 m1,稍后重试
pthread_mutex_unlock(&m1);
usleep(1000); // 退避一下再试
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
(3) 方法三:C++ 的 std::lock(一次性获取多把锁)
std::mutex m1, m2;
// std::lock 用死锁回避算法,保证安全地同时获取多把锁
std::lock(m1, m2);
std::lock_guard<std::mutex> lg1(m1, std::adopt_lock);
std::lock_guard<std::mutex> lg2(m2, std::adopt_lock);- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
六、补充:自旋锁与原子操作
除了 mutex,还有两个常见的同步手段值得了解。
自旋锁(Spinlock):获取锁失败时,线程不睡眠,而是一直循环检查(忙等)。适合持锁时间极短(微秒级)的场景,避免了睡眠/唤醒的上下文切换开销。
pthread_spinlock_t spin;
pthread_spin_lock(&spin);
/* 极短的临界区 */
pthread_spin_unlock(&spin);- 1.
- 2.
- 3.
- 4.
如果临界区执行时间较长,自旋锁会白白浪费 CPU——持续空转等待。
原子操作:对于简单的计数器或标志位,直接用 CPU 硬件提供的原子指令,完全不需要锁:
#include <atomic>
std::atomic<int> counter{0};
void *inc(void *arg) {
for (int i = 0; i < 100000; i++)
counter++; // 原子操作,无需加锁,性能最高
return NULL;
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
std::atomic 底层用 lock xadd 等 CPU 原子指令保证操作不可分割,性能远优于 mutex。适合简单的整数操作,复杂数据结构还是要用 mutex。
七、同步手段选型速查
场景 | 推荐方案 |
保护普通共享数据 |
+ |
等待某个条件 |
+ |
读多写少的数据 |
/ |
简单计数器/标志位 |
|
极短临界区(<1μs) | 自旋锁 |
跨进程同步 | 信号量( |
八、高频面试题精析
Q:cond_wait 为什么要传入 mutex,它们是什么关系?
cond_wait 内部是原子操作:释放 mutex + 进入睡眠。之所以要原子,是为了防止"丢失唤醒"的竞态——如果先解锁再睡眠,解锁和睡眠之间恰好被 signal 打断,则这次唤醒会丢失,线程会一直睡下去。
Q:为什么 cond_wait 返回后必须用 while 而不是 if 重新检查条件?
两个原因:第一,存在虚假唤醒(spurious wakeup),POSIX 规范允许 cond_wait 在没有 signal 的情况下偶尔返回;第二,多消费者场景下,一个 signal 可能唤醒多个线程,但数据只有一份,第一个消费完后,后面的线程必须重新检查条件。
Q:mutex 和自旋锁怎么选?
临界区执行时间短(比如几条 CPU 指令):用自旋锁,省去睡眠唤醒开销。临界区涉及 IO、系统调用、长时间计算:用 mutex,否则其他线程白白空转浪费 CPU。
Q:读写锁会不会导致写线程"饥饿"?
会。如果读线程源源不断,写线程可能一直等不到机会。不同的 rwlock 实现有不同的策略:Linux 的 pthread_rwlock 默认写优先(有写线程等待时,新来的读线程也要排队),但配置不当仍可能出现饥饿。
九、结语
从 mutex 到条件变量,从读写锁到死锁预防,线程同步的本质只有一句话:在正确的时机,让正确的线程访问正确的数据。
选对了工具,并发程序又快又安全。选错了,轻则数据错误,重则死锁程序永远卡住。
理解这些,你才能真正看懂 std::shared_mutex、std::condition_variable 的设计思路,才能在 code review 里一眼看出潜在的竞态条件,才能在面试里把并发这道大题答得层次分明。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
10款免费AI语音输入工具与软件 轻松实现语音转文字
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
SkyBot由Skywork研发的云电脑AI助手
AI Agent 智能体 - Multi-Agent 架构入门
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
一文搞懂卷积神经网络经典架构-LeNet
一文搞懂深度学习中的池化!
AI精选