

通义实验室推出视频环境音生成框架PrismAudio
作者:互联网
2026-03-26
 AI快讯
AI快讯
阿里通义实验室最新发布的PrismAudio框架创新性地融合强化学习与思维链技术,专注于视频环境音效的智能生成。该系统能精准合成与画面同步的各类背景声效,为视听体验带来全新突破。
PrismAudio 仅需 5.18 亿参数即可实现高效音频生成,处理9秒音频仅耗时0.63秒。该研究成果已被ICLR 2026收录,即将开放源代码。其核心创新在于"先思考后发声"机制,并引入四位专业评审进行多维度评估:
- 语义评审确保声音与画面内容精确匹配,例如准确识别马蹄声而非鸟鸣
- 时序评审严格把控音画同步,精确到毫秒级别
- 美学评审从音质角度评估,要求声音自然且富有层次感
- 空间评审验证声源定位,确保方位感真实可信
在声音生成前,系统会进行多角度预分析:识别视频内容要素、确定音效类型、规划时间节点、设计声音质感、处理空间定位等关键要素。通过将思考过程拆解为四个独立模块,最终整合成完整的执行方案。
每位评审都配备了专业评估工具:
- 语义评审采用MS-CLAP系统验证音画匹配度
- 时序评审使用Synchformer进行毫秒级同步检测
- 美学评审依托Meta Audiobox Aesthetics多维度音质分析
- 空间评审通过StereoCRW校验声源定位准确性
综合四项评分形成最终质量指标,促使模型持续优化生成策略。这种多维度评估机制避免了单一标准的局限性,确保各环节质量均衡发展。
团队研发的Fast-GRPO强化学习算法将随机探索控制在关键节点,大幅提升训练效率。实验数据显示,该方法仅需200步训练即可达到传统方法600步的效果。
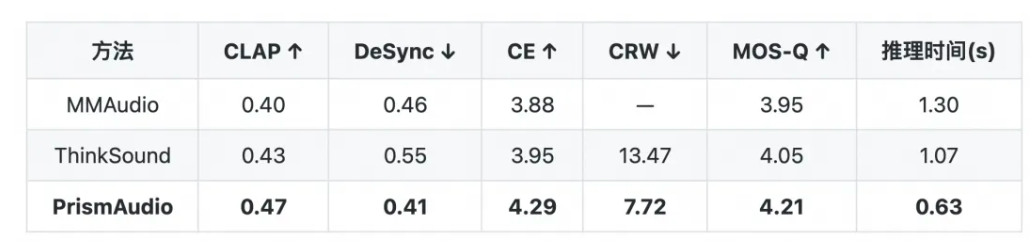
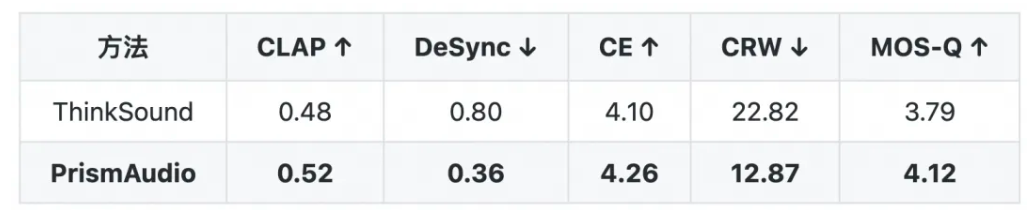
PrismAudio通过创新的思维链架构和多维评估体系,为智能音效生成树立了新标准,其高效性能与精准控制能力展现出广阔的应用前景。
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
贝叶斯不确定性引导的早停框架ESTune与OceanBase校企联合研究
杈炬ⅵ&浜哄ぇ閲戜粨閫傞厤瀹炴垬锛歋eaTunnel鍦ㄤ俊鍒涙暟鎹钩鍙颁腑鐨勫簲鐢ㄤ笌韪╁潙鎬荤粨
2026年1月中国数据库流行度排行榜:OB连冠领跑贺新元PolarDB跃居次席显锐气
社区译文解析FUD与真相MySQL是否真的被弃用了
英伟达重新规划AI推理加速布局 暂停Rubin CPU转攻Groq LPU
gpress v1.2.2 全新上线 Web3内容平台迎来更新
CMake 4.3.0 正式推出
短剧采用AI换脸技术使角色酷似明星 制作方与播出方构成侵权
微信整治AI生成恶意链接 黑灰产利用人工智能批量炮制违规网页遭重拳打击
宜家发布Varmblixt氛围灯 采用甜甜圈设计并兼容Matter协议
AI精选