

2000万浏览!拆解Karpathy爆火推文LLM Wiki:AI 知识库的尽头是“记忆”
作者:互联网
2026-04-14
 AI快讯
AI快讯
前几天,Andrej Karpathy 在 X 上发了一条关于“LLM 知识库”的实操推文,顺便附上了一个 GitHub Gist。
结果数据炸了:推文揽下 2000 万展现量和 10 万收藏,那份仅有设计思路、没有一行代码的 Gist 也狂揽近 5000 个 Star。
顶尖大佬随手的一个分享,为什么能引发全网狂欢?因为它精准狙击了当下每个重度 AI 用户都在默默忍受,却说不出来的痛点。
以下是我对这套方案的深度拆解,以及由此延展出的、关于 AI 产品下一步该往哪走的思考。
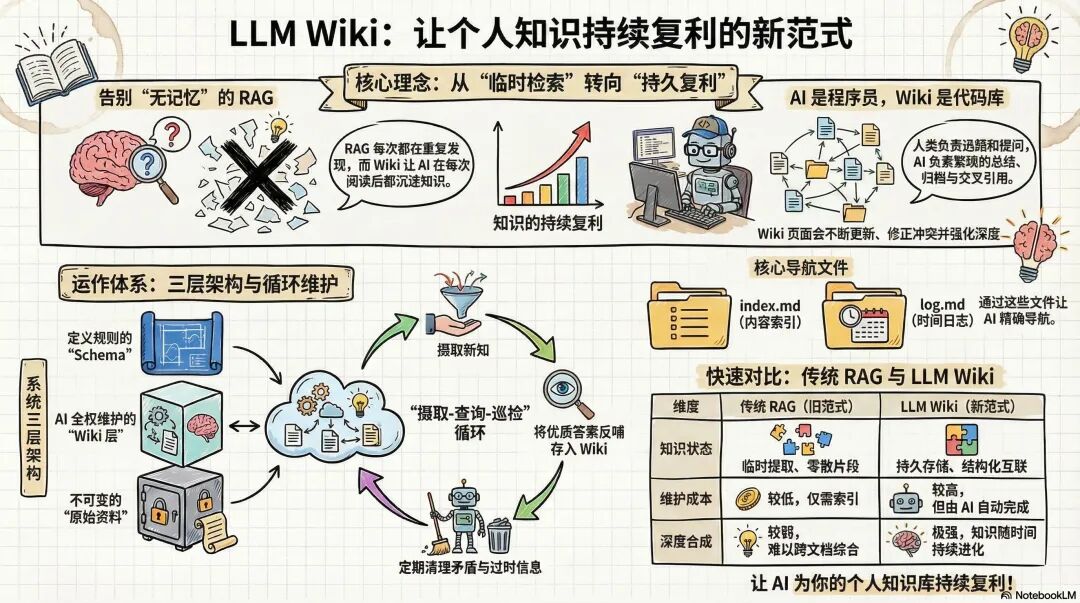
一、 传统 RAG 的死穴:为什么你的 AI 总是“原地重启”?
目前市面上绝大部分文档对话产品(包括 ChatGPT 上传文件、NotebookLM 等),底层用的都是 RAG(检索增强生成)技术。也就是:你丢一堆文件进去,提问时 AI 像个图书管理员一样,跑进书库里抽出几页相关的,拼凑出一个答案给你。
Karpathy 敏锐地点出了这个模式的致命伤:系统没有“记忆沉淀”。
在 RAG 模式下,AI 永远是一条只有 7 秒记忆的金鱼。你上周引导它结合 5 份研报得出了一个极其深刻的行业洞察,下周你再问相关问题,它依然得从零开始重新翻书、重新推理。
辛苦探索出的高价值认知,一旦关闭对话框就灰飞烟灭。Karpathy 认为,真正的解法不是让大模型去做“被动的检索器”,而是让它成为“主动的维基百科(Wiki)维护者”。 知识应该被编译、关联并持续生长,而不是每次都在沙滩上建城堡。
二、 “三层解耦”:把大模型变成严谨的档案管理员
在他的构想中,一座具备复利效应的知识库,必须有森严的等级划分。他提出了一个极为优雅的“三层架构”:
第一层:原始输入层(Raw Sources)。 你扔进来的论文、数据、长文。这条底线是:大模型只读不写。这就保住了我们常说的“Ground Truth”(绝对真理),随时可以溯源,不怕 AI 瞎编乱造。第二层:知识重构层(The Wiki)。 整个系统的核心。这不仅是搬运,而是大模型消化原始资料后,撰写的一系列 Markdown 文件(概念解析、实体对比、核心摘要等)。大模型负责写,你负责看。第三层:最高法则层(The Schema)。 类似一份《系统宪法》(如 CLAUDE.md)。它强行规定了 AI 应该用什么格式写笔记、怎么做链接、怎么回答问题。没有这个紧箍咒,大模型很快就会把知识库搞成一堆杂乱无章的废纸。这其实是经典软件工程中“控制面与数据面分离”的思想在 Prompt 领域的绝佳应用。
三、 拒绝“聊完就丢”:让知识产生复利的四大工作流
搭建好架构,这台机器是怎么转起来的?Karpathy 设定了四个标准动作:
- 摄入(Ingest): 丢新资料进去时,他不主张全自动批量吞噬,而是强调“人在回路”。AI 提取要点,你来把关方向,人机共创一个新页面,并更新关联链接。查询(Query): 这是最颠覆我的一点。他提出:所有高质量的问答结果,必须作为新页面存回 Wiki 中。 你让 AI 做的每一次深度对比表格、每一次逻辑推演,都应该变成知识库的新养分。巡检(Lint): 设定一个定时任务,让 AI 自己去给知识库“找茬”。查缺补漏、修复死链接、标出前后矛盾的观点。用自动化流程对抗知识的熵增。索引日志(Indexing & Logging): 靠一个简单的 index.md(链接+一句话摘要)来统领全局。在百十篇文档的体量下,根本不需要复杂的向量数据库,大模型直接读目录反而更精准。
四、 千万爆款背后的逻辑与“极客方案”的硬伤
这条推文之所以能拿下一千多万流量,除了大佬本人的光环,更重要的是它用一种“平视”的实操视角,给出了一个普通人半小时就能用 Obsidian + 本地大模型跑通的 MVP(最小可行性产品)方案。他还留了一句极具煽动性的话:“这里完全有空间诞生一个不可思议的新产品。”
但如果我们从工程落地的角度来看,这个极客手搓的系统是有明显天花板的:
上下文崩塌: 几百篇文档还能靠 Index 文件硬扛,一旦到了几十万字甚至百万字,现有的 Token 上限绝对撑不住。全局一致性失控: 知识图谱越来越庞大时,大模型在单次操作中无法纵览全局,极其容易在不同角落写下自相矛盾的结论。协作盲区: 这本质上是个“单机游戏”,一旦引入多用户或多 Agent 同时操作,Git Merge 级别的冲突合并根本无法解决语义上的冲突。五、 趋势洞察:AI 产品的下半场,拼的是“状态”与“积累”
跳出技术本身,这次千万级曝光实际上揭示了 AI 行业竞争维度的重大拐点。
过去两年,百模大战卷的全是“单次生成质量”:看谁代码写得快、谁图画得逼真。但这只是最基础的“无状态”(Stateless)比拼。
接下来的主战场,将转向“积累能力”(Stateful)。未来的 AI 产品,比拼的是谁能随着时间的推移,越用越厚实、越用越懂你。就像当年搜索引擎从单纯比拼“网页相关度”,进化到推荐系统比拼“用户画像深度”一样。
谁能在“持续编译、持续积累”这个思路上做出顶级的体验,谁就能拿到 AI 下半场的船票。这就是为什么我说,未来的产品绝不仅是个“套壳笔记”或“进阶版 RAG”,而是一个全新的物种——AI 原生的知识伴侣。
本文转载自后向传播,作者: 张发恩
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
RAG当主力,MemPalace把记忆准确率干到 96.6%,token 成本为0
决策树的启发方式深度解析
评审也不靠人,每天消耗10亿token!OpenAI核心工程师自曝极限经历:对代码细节没执念了!MCP早死了!软件依
OpenClaw会变Close?龙虾之父:不让OpenAI参与太多!梦境是从CC泄露的源码发现的!token处理会越来越快!
Hermes Agent 技术架构全解:当"自进化"被拆解为工程实现
大模型的“隐秘脑回路” | Claude Mythos是如何靠1个比特位翻转拿下Linux Root 的?
扒一扒Meta全新大模型Muse Spark里藏着的PDR技术
2026 新版 OpenClaw Windows 安装教程|一站式部署指南
2026 新版 OpenClaw Windows 极简安装教程|本地AI智能体快速上手全攻略
2026 新版 OpenClaw Windows 安装教程|本地 AI 智能体一键部署完整指南
AI精选