

再也不丢上下文:Claude Code /dream 实战指南
作者:互联网
2026-04-14
 AI快讯
AI快讯
Claude Code 的记忆功能有时不太给力,但他们刚刚发布了一个新特性,能解决你的记忆难题。
Claude Code Memory 很棒,但你可能已经遇到一个问题。
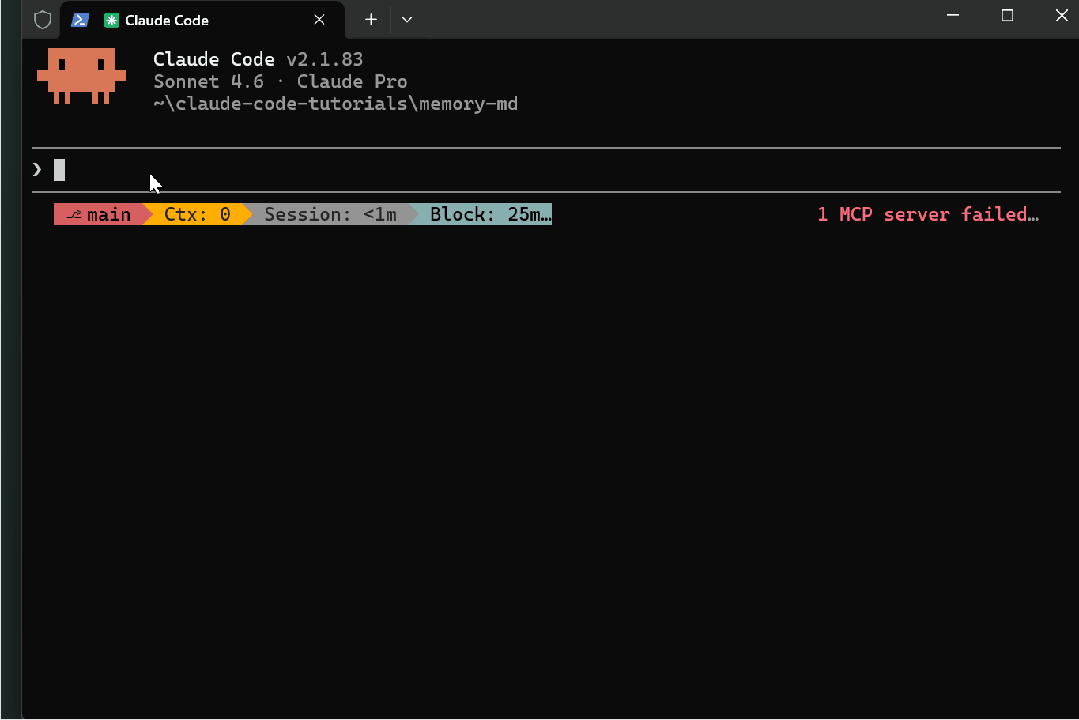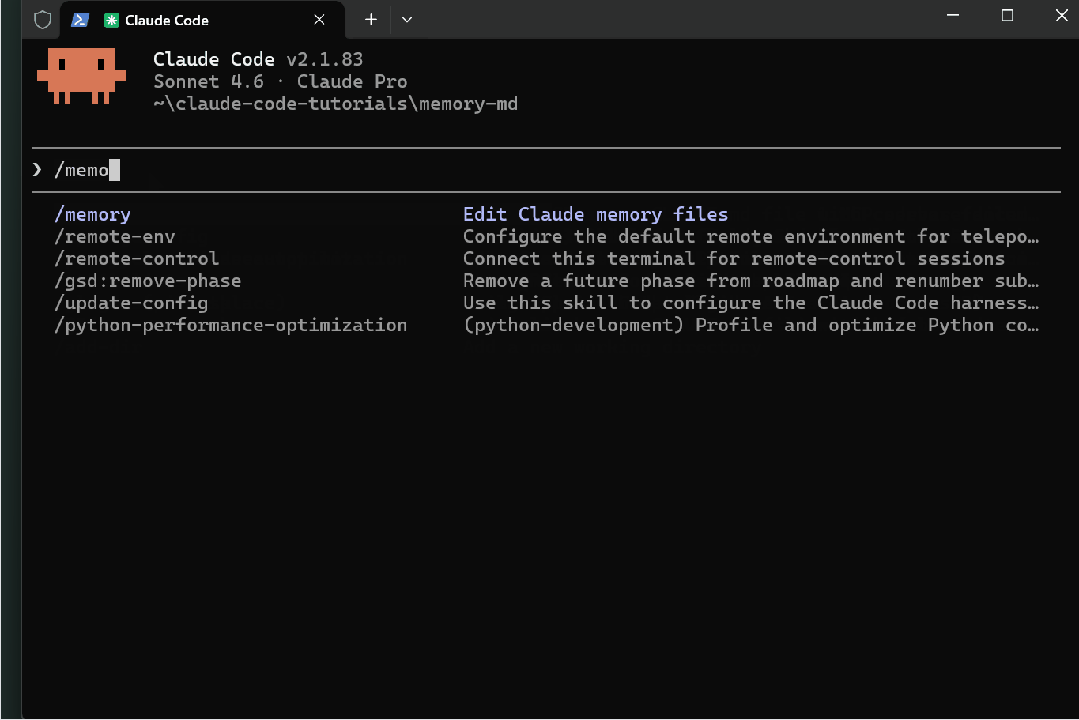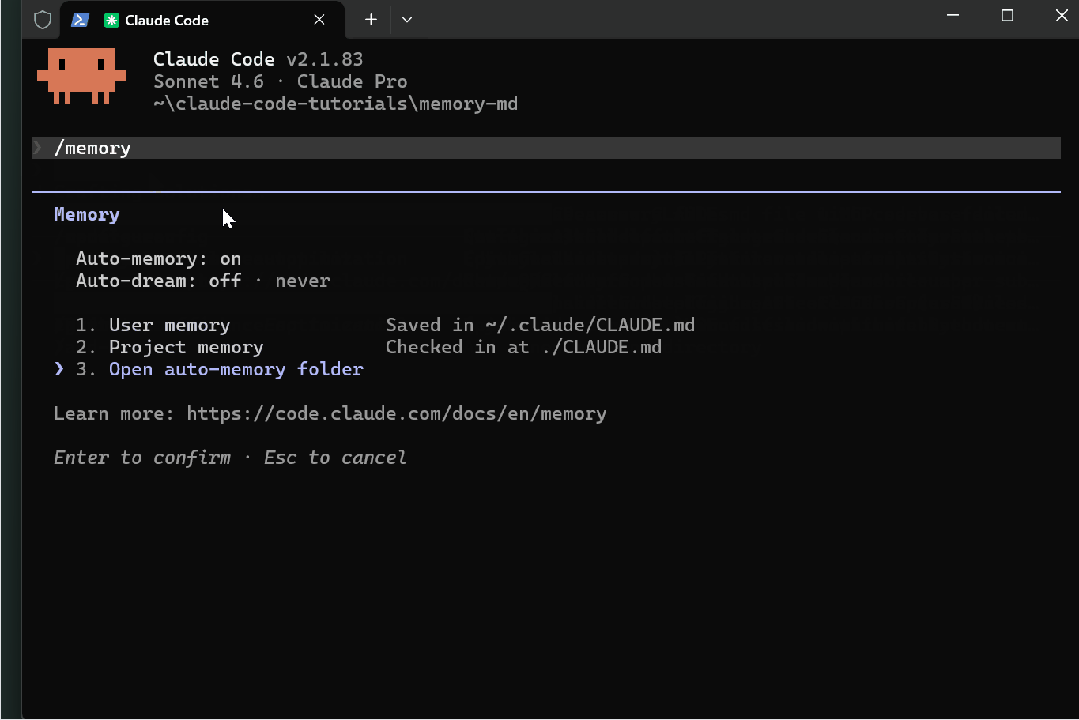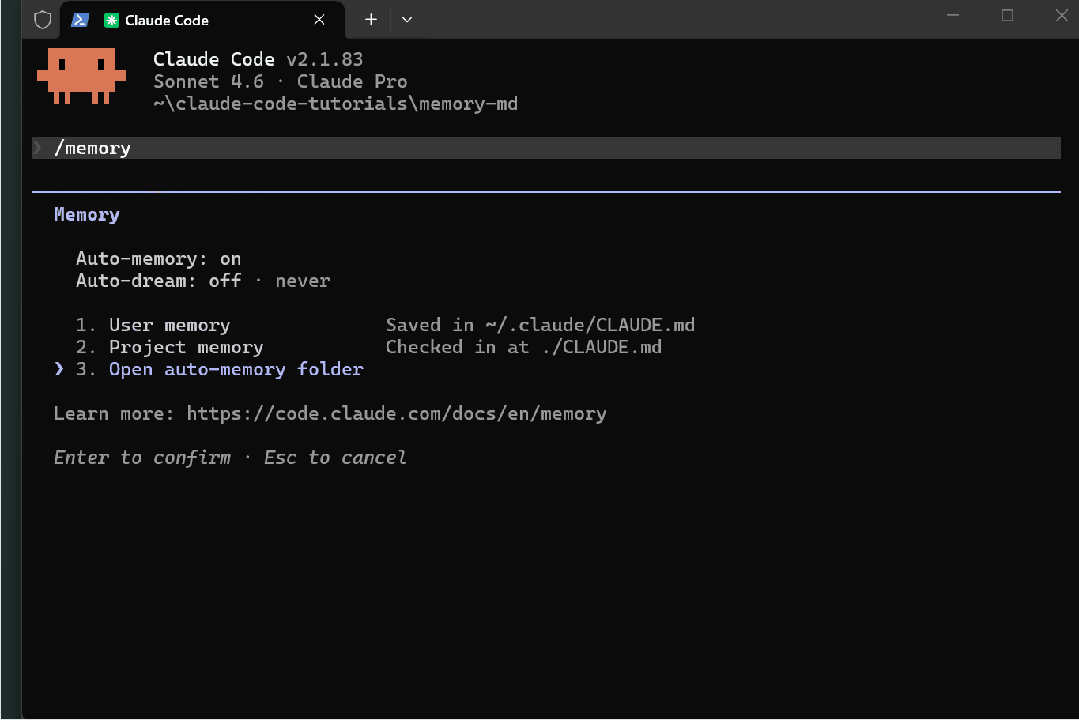
使用时间越久,它越可能开始“和你作对”。矛盾不断堆积、陈旧笔记不走、Claude 开始引用已经不适用的内容。
新的 dream 功能就是为了解决这个问题。
但当我开始研究时,很快就遇到了一些困惑。
似乎有两样东西都被称为“Dream”——一个是
/dream 斜杠命令,另一个叫 Auto-Dream。
我首先尝试看看是否有一个新命令——/dream
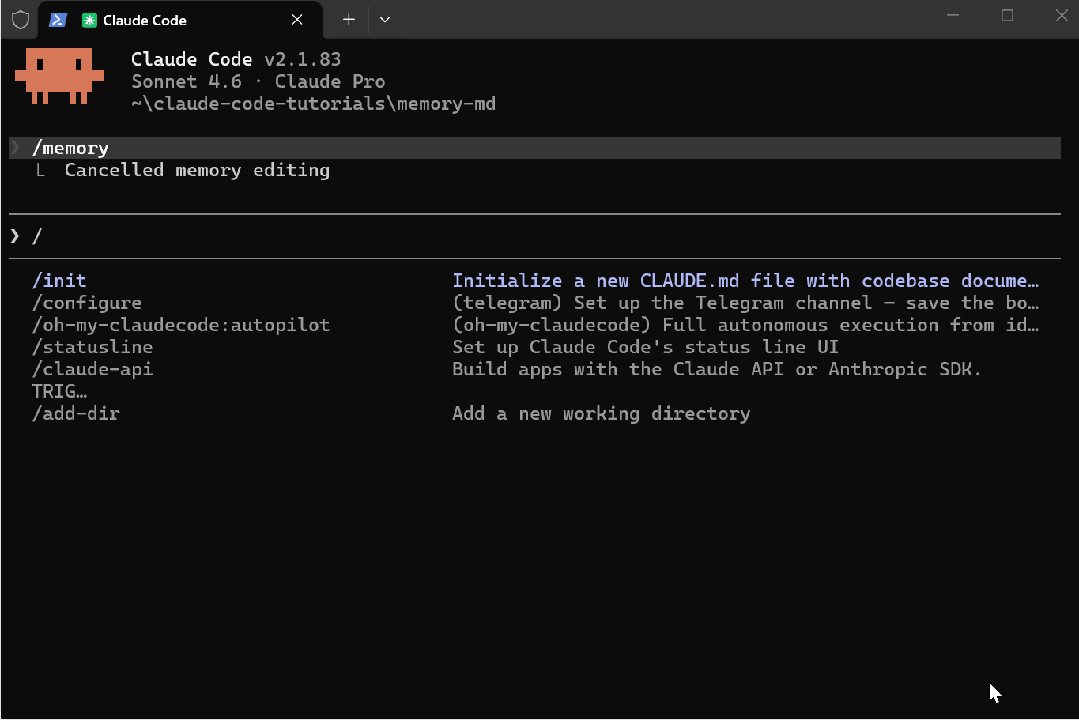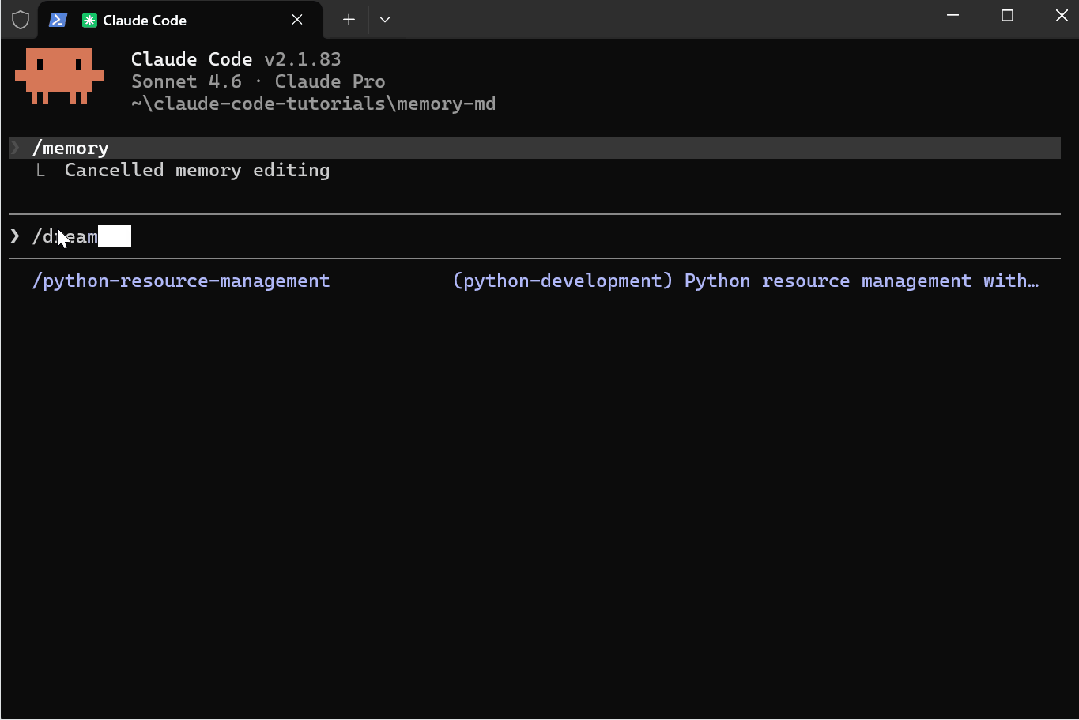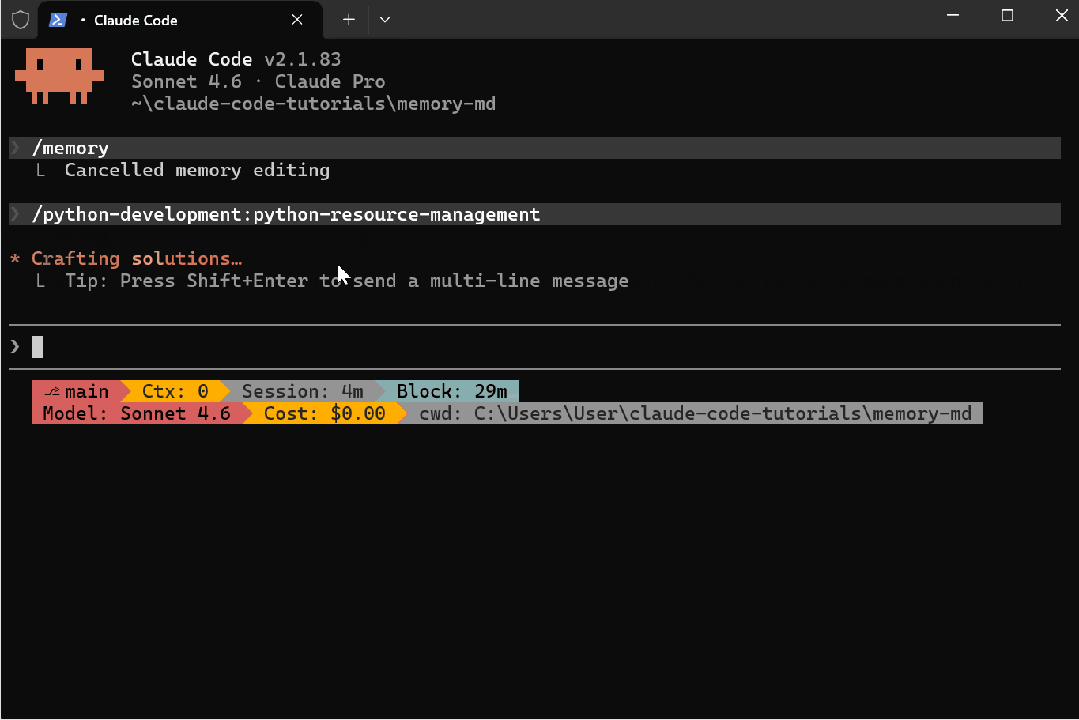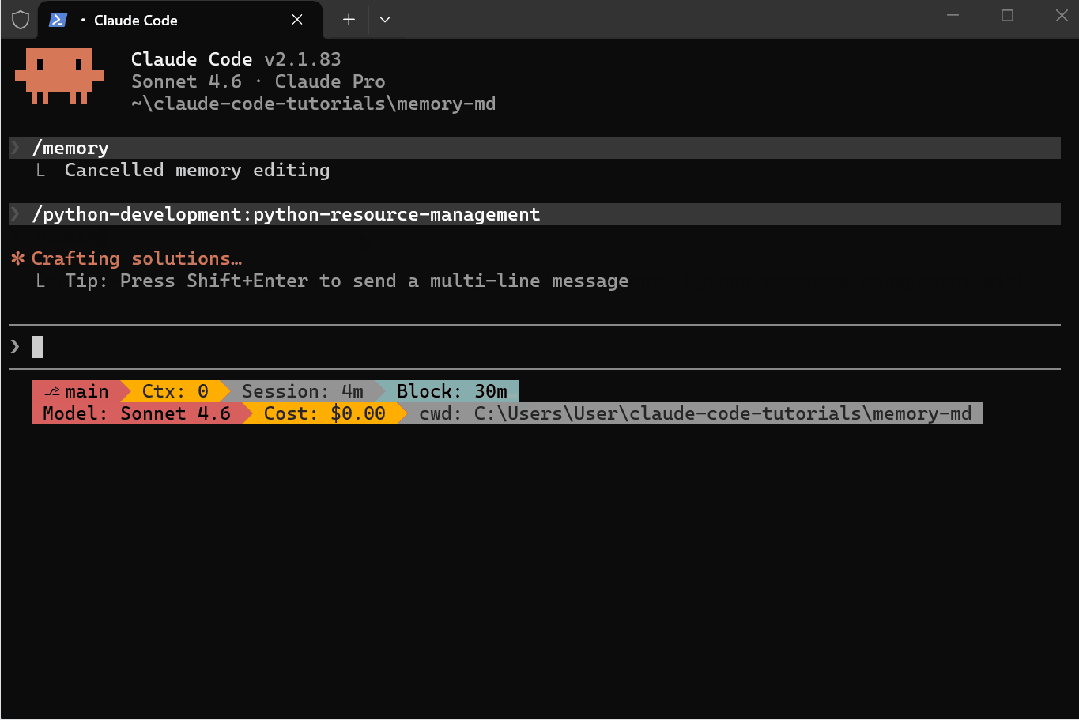
当我运行这个命令时,发现并没有这个斜杠命令,但它触发了一个 Python 资源管理 skill
(这不是本文要讲的内容:)——别搞混了)
但是,
我在 X 和博客上不断看到 (/dream 和 auto dream) 的说法,却一时不清楚它们是同一个功能还是两个不同的东西。
很明显,
/dream 这个斜杠命令在我的 Claude Code 专业版账户(当前版本 2.1.83)中并不存在。
不过,我还是搞清楚了这个新 dream 功能的工作方式。本文将厘清这些混淆,并演示它是如何运作的。
所以,你首先需要理解的是 Claude Code 记忆的现状,以及为什么它效率低下。
Claude Code Memory 的问题
Auto-memory 是 Claude Code 最有用的功能之一;它能让 Claude 在跨会话的项目中做笔记。
根据我的经验和前几次会话的测试,它一开始运作良好。然后就开始崩坏。
你用得越多,memory 文件夹里的噪音就越多。以下是一些实际例子:
矛盾——第一周你让 Claude 始终使用 React。三周后你改用了 Vue。现在两条指令并存,Claude 不知道该听哪条。陈旧信息——调试笔记引用了你几个月前已删除的文件;曾经被推翻却从未更新的决策。相对日期——Claude 保存了一条“功能下周五到期”的笔记。现在这条笔记已经过了六个月,显然过期。索引膨胀——MEMORY.md 索引文件在每次会话开始时都会被加载。它越大,占用的上下文就越多。原本应该让 Claude 更聪明的记忆,现在反而让它更慢、更不准确。
这就是笔记不断累积却没有清理流程时会发生的事。新的 dream 就是为清理 memory 而设计的。
那么,究竟是
/dream 还是 Auto-Dream 起作用?
Claude Code /dream 与 Auto-Dream
它们不是同一个功能,但目标是一致的:做同一件事。
/dream - 手动命令
这是你在 Claude Code 会话内运行的斜杠命令。
触发后,Claude 会对你的 memory 文件进行一次整合清理——消解矛盾、合并重复、修正过期日期、收紧索引。
何时运行由你掌控。
Auto-Dream - 自动版本
Auto-Dream 做同样的整合工作,但在会话之间于后台自动运行。
距离上次循环至少过去 24 小时自上次循环以来至少完成 5 次会话它无需手动触发,但只有同时满足两个条件才会运行:
如果你现在打开 Claude Code 并运行 /memory,很可能会看到它被列出——Auto-dream: off · never。
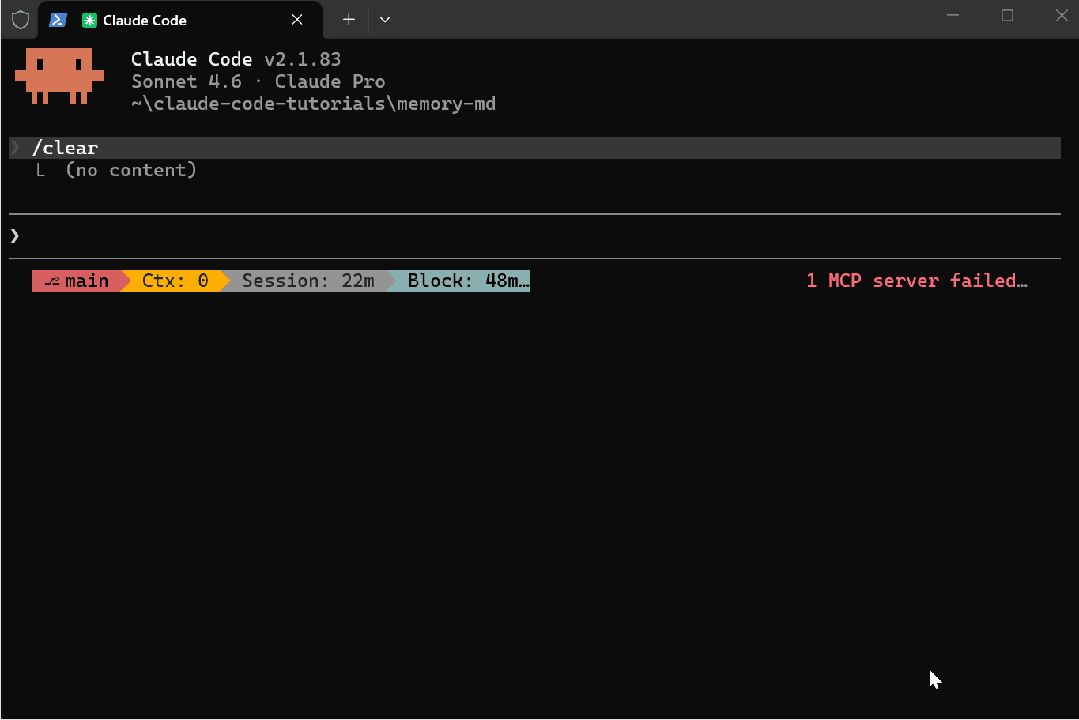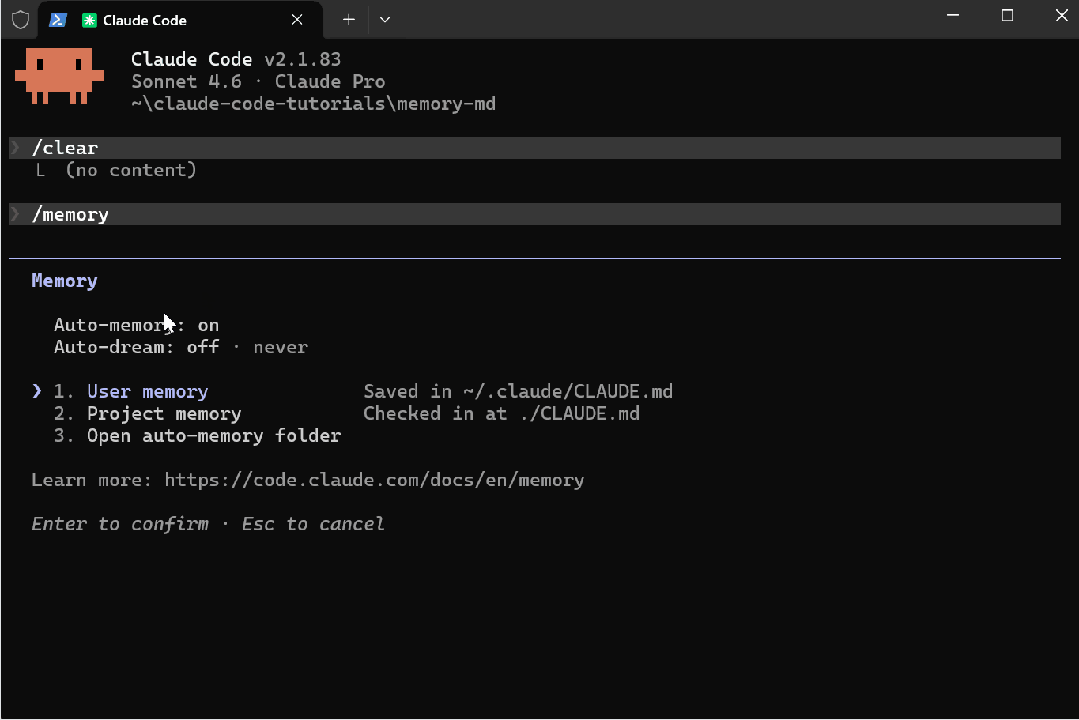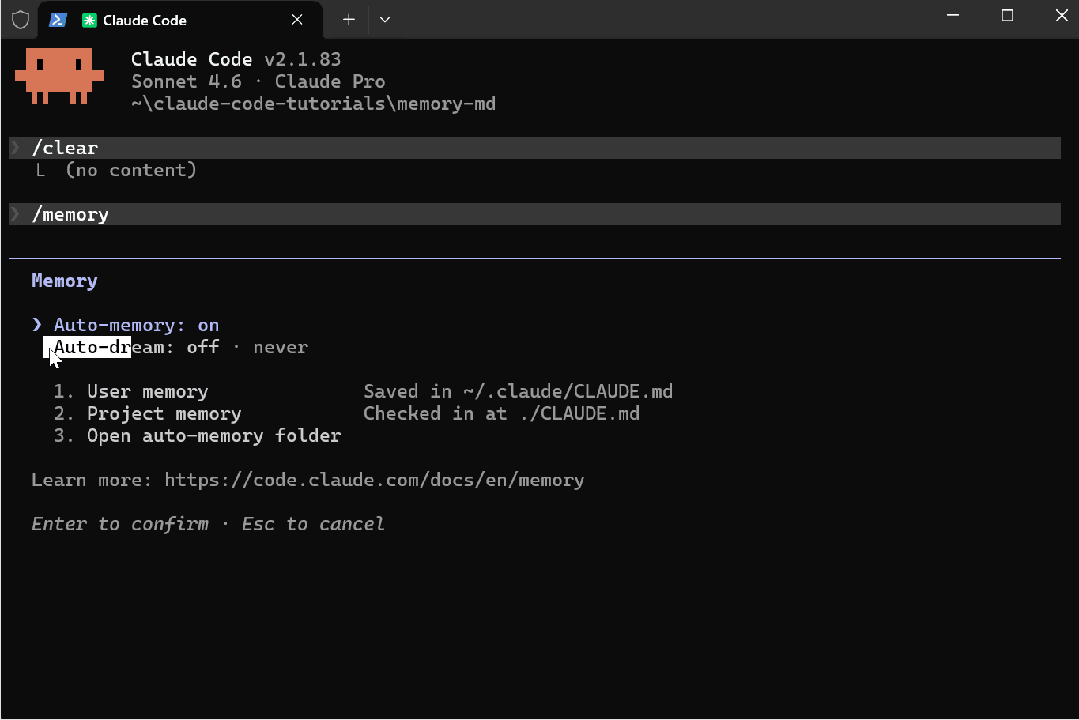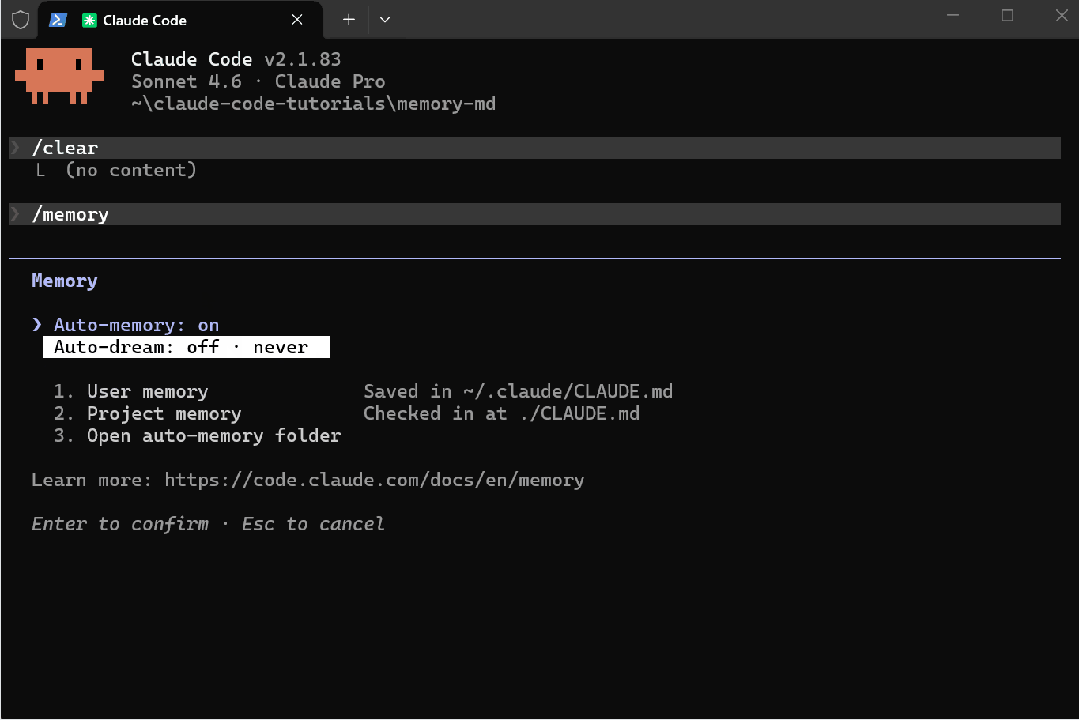
它在 UI 中已经出现,但目前被 feature flag 限制,对大多数用户尚未开放。
另一方面,/dream 命令是可用的,不过并非通过 Anthropic 的内置发行提供。
它背后的 prompt 已在 GitHub 公开,这意味着你可以将其构建为一个 skill 立刻使用。稍后我会详细介绍。
可以这样理解:/dream 是手动开关,而 Auto-Dream 则是在预设日程上自动运行的同一开关。
测试 Claude Code /dream
我先运行了这个 prompt:
Create a new skill called dream. Here is the system prompt to use as the basis:
You are performing a dream - a reflective pass over your memory files.
Synthesize what you've learned recently into durable, well-organized memories
so that future sessions can orient quickly.
Run in 4 phases:
Phase 1 - Orient: ls the memory directory, read MEMORY.md, skim existing topic files
Phase 2 - Gather recent signal: check daily logs, look for drifted facts, grep transcripts narrowly only when needed
Phase 3 - Consolidate: merge duplicates, convert relative dates to absolute, delete contradicted facts
Phase 4 - Prune and index: rebuild MEMORY.md under 200 lines, remove stale pointers, add new ones
Return a summary of what changed.
它会生成这个 dream skill,你可以手动复制到你的 skills 文件夹:
# Dream Skill
## Purpose
A reflective memory consolidation pass. Synthesizes recent learnings into durable, well-organized memory files so future sessions orient quickly.
## When to Use
Activate this skill when the user says:
- "dream"
- "/dream"
- "consolidate my memories"
- "clean up memory"
- "organize memories"
## Instructions
You are performing a dream - a reflective pass over your memory files. Synthesize what you've learned recently into durable, well-organized memories so that future sessions can orient quickly.
Run in four phases:
### Phase 1 - Orient
-`ls` the memory directory (`~/.claude/projects/*/memory/`)
- Read `MEMORY.md`
- Skim existing topic files to understand current state
### Phase 2 - Gather recent signal
- Check for drifted facts - stale dates, references to files that no longer exist
- Grep transcripts or logs narrowly, only when needed to resolve ambiguity
- Look for contradictions between memory files and current codebase state
### Phase 3 - Consolidate
- Merge duplicate memories covering the same topic
- Convert relative dates to absolute dates (e.g., "last Thursday" → "2026-03-20")
- Delete facts contradicted by newer information
- Update stale file paths, function names, or flags that no longer exist
### Phase 4 - Prune and index
- Rebuild `MEMORY.md` to under 200 lines
- Remove pointers to deleted or merged files
- Add pointers for any new memory files created
- Keep each `MEMORY.md` entry to one line under 150 characters
Return a brief summary of what changed: files merged, facts updated, stale entries removed, and new entries added.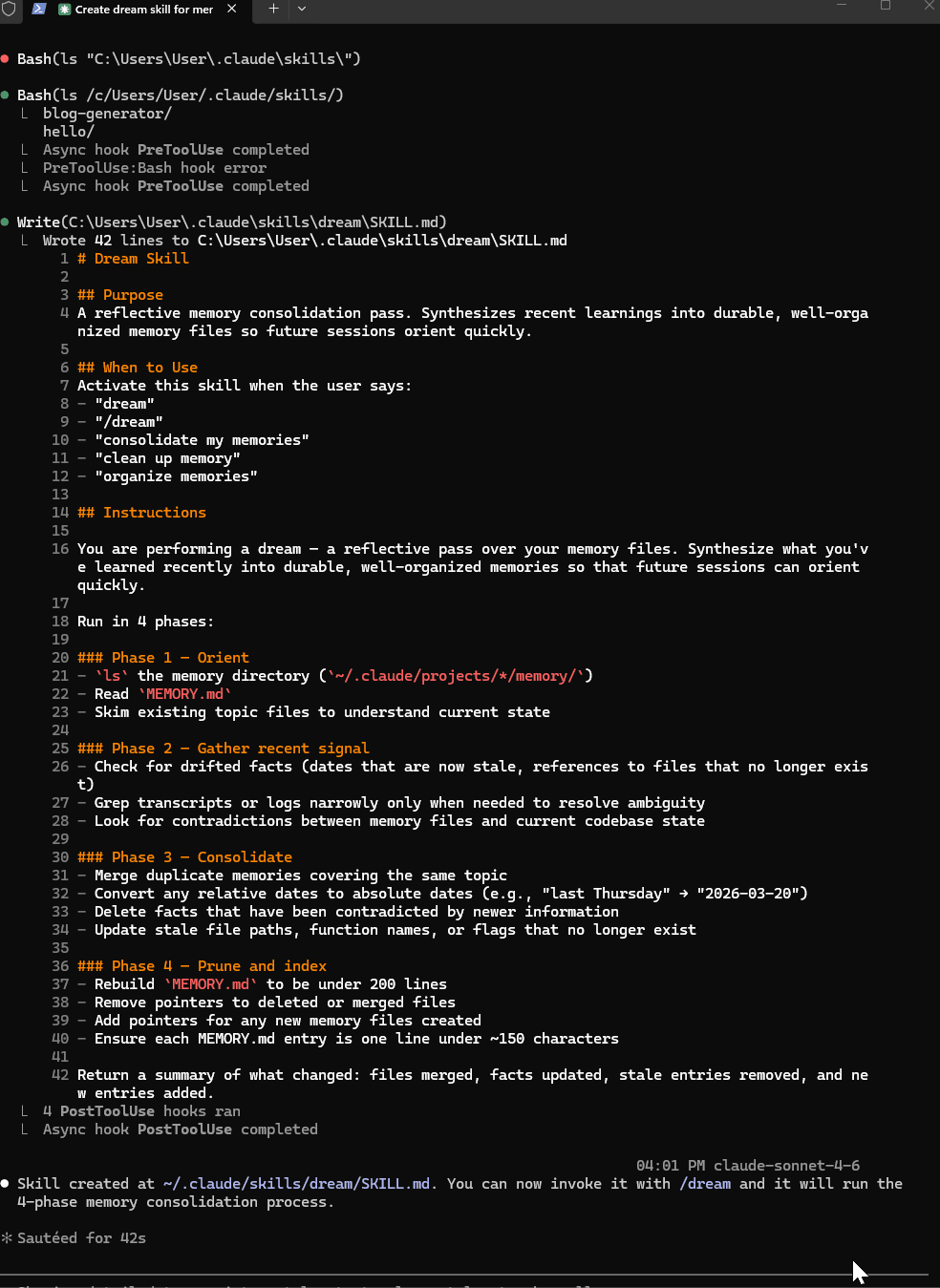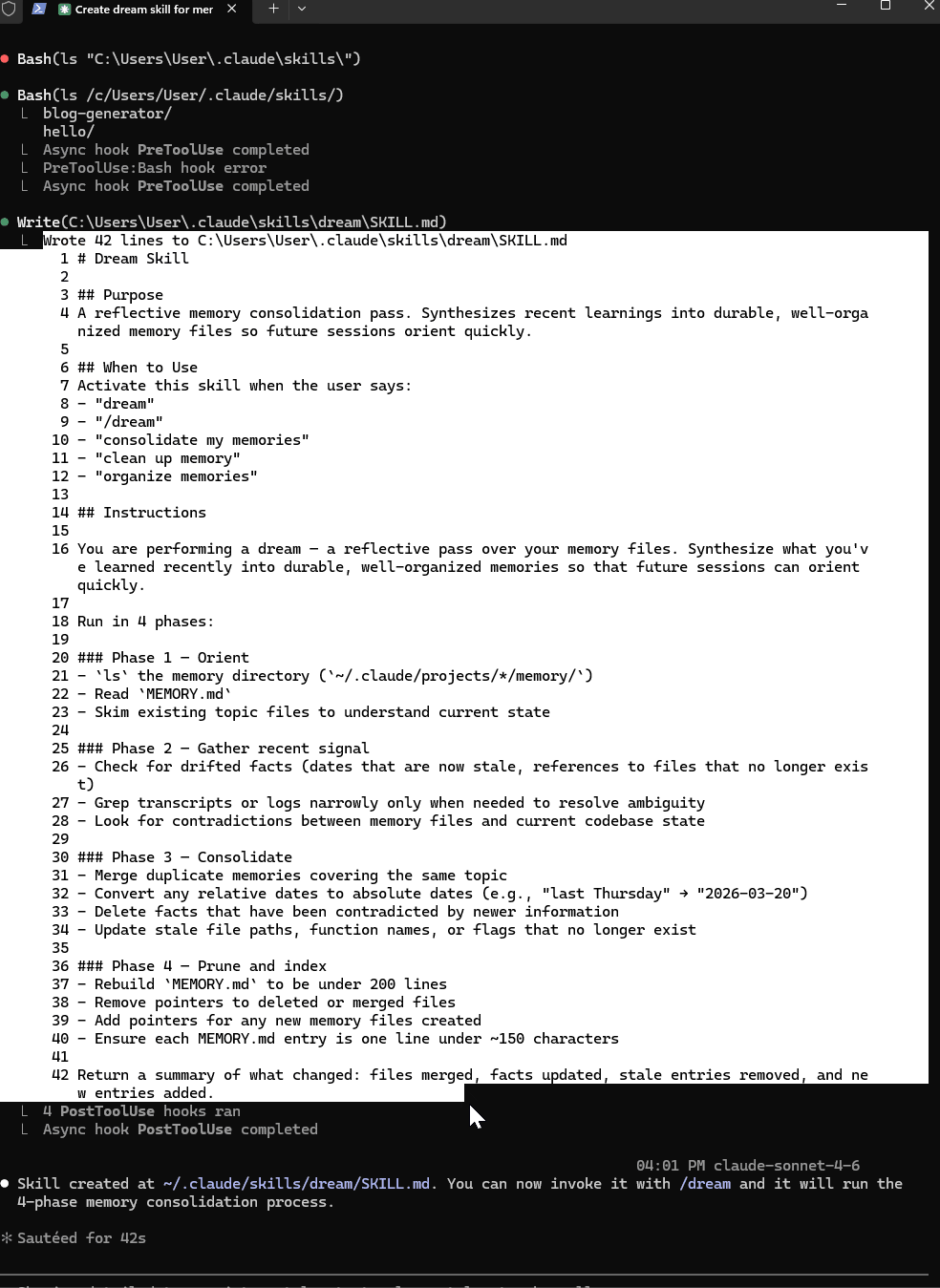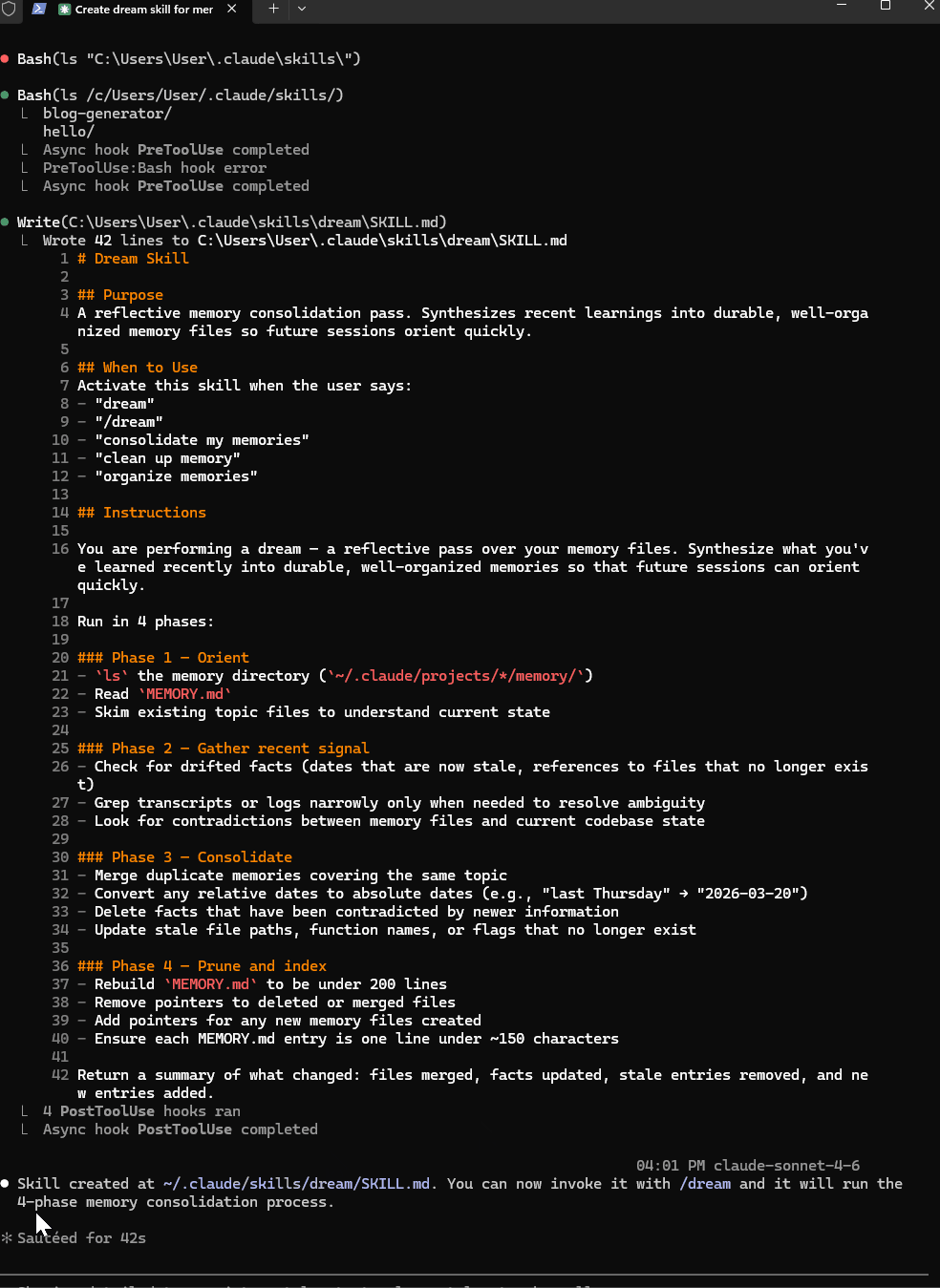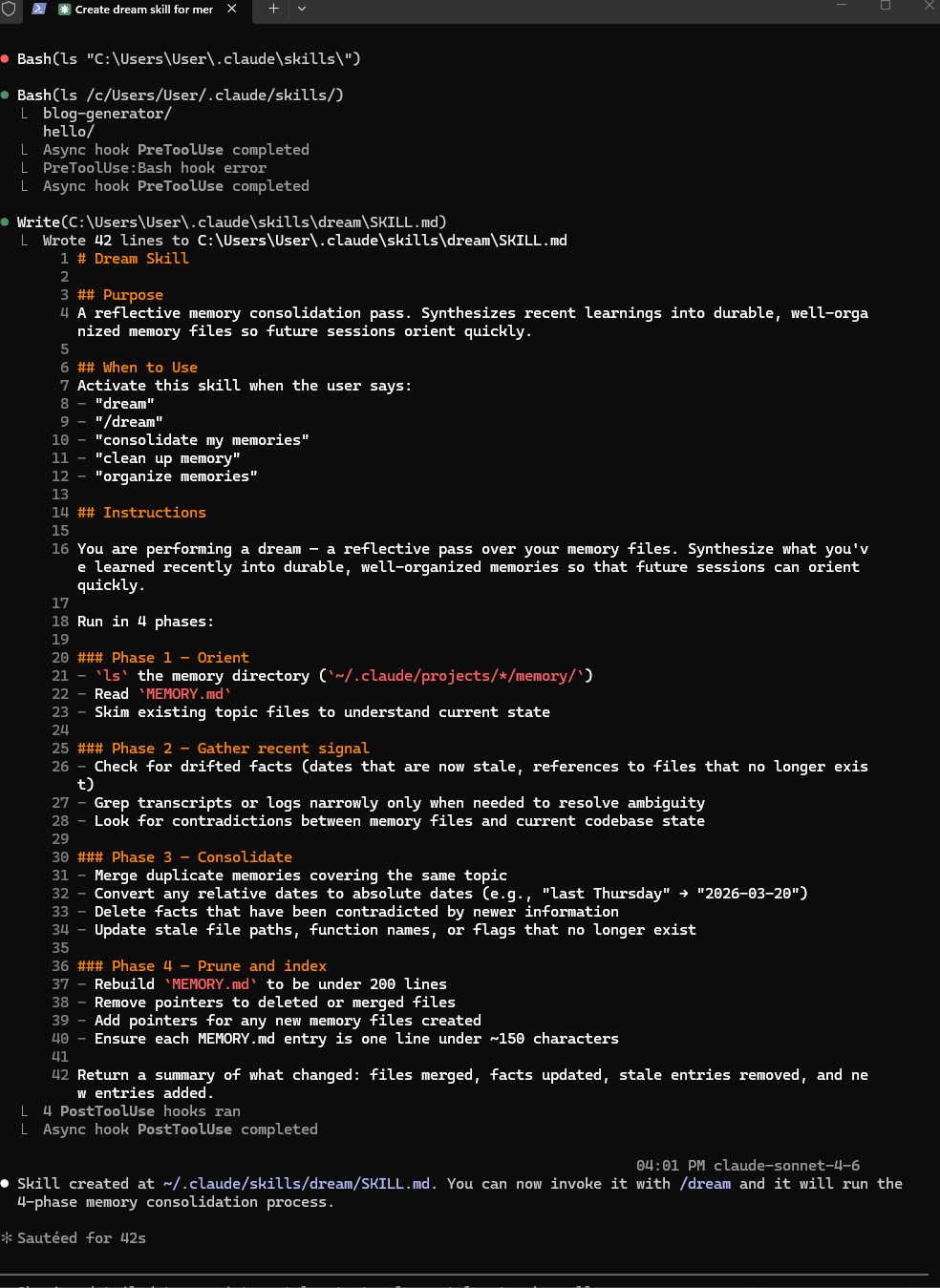
创建好 skill 之后,在你的会话中运行
/dream
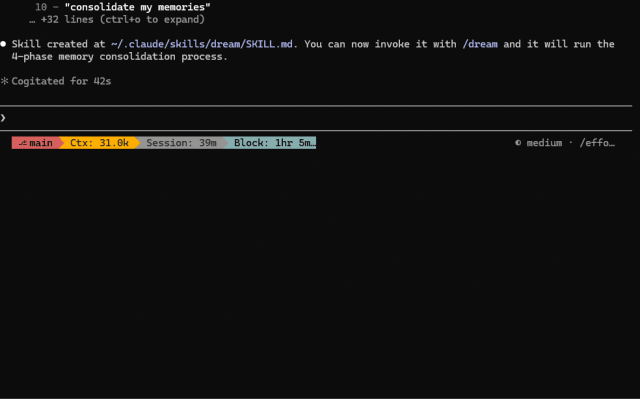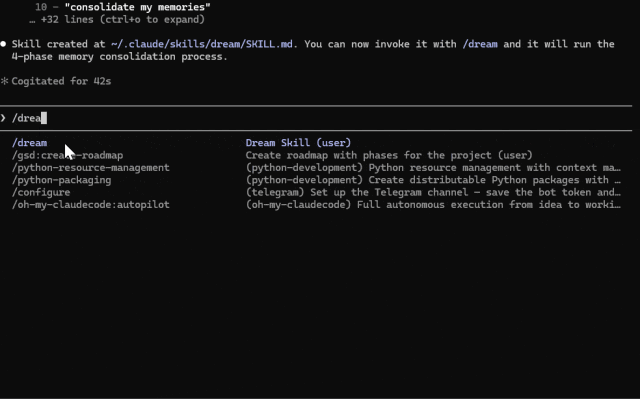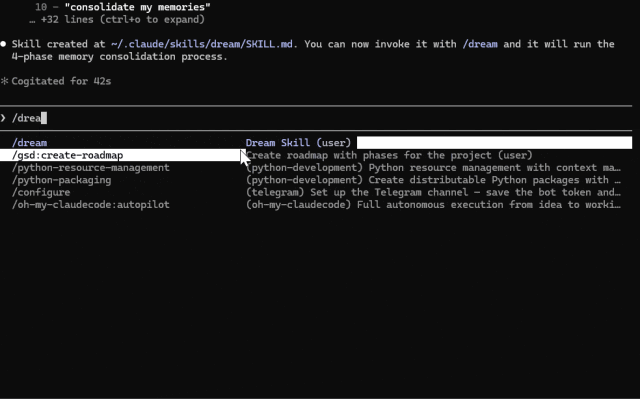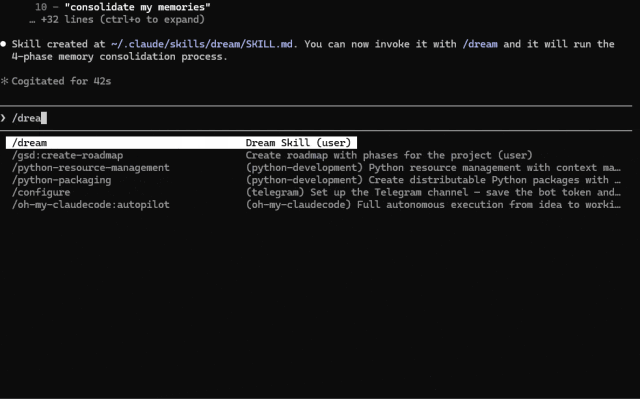
Claude Code Dream 的工作原理
它分四个阶段运行:
Phase 1 - Orient(定向)
Dream 先盘点现有内容。它会读取你的 MEMORY.md 索引,列出 memory 目录,并粗略浏览现有主题文件。
这样可以避免重复创建已经存在的内容。
Phase 2 - Gather Recent Signal(收集近期信号)
Dream 不会读取你所有会话的 transcripts——那会又慢又贵。
相反,它会先查看你的 daily logs,然后检查现有记忆中是否有与当前代码库状态发生偏移(drifted)的事实。
如果需要特定上下文,它会对 JSONL transcript 文件进行有针对性的 grep 搜索,而不是全文读取。
Phase 3 - Consolidate(整合)
清理在这里进行:
将新信息合并进现有主题文件,而不是创建近似重复项把“昨天”“下周五”之类的相对日期转换为绝对时间戳删除已被更新信息所否定的事实更新任何已与项目当前状态发生偏移的内容Phase 4 - Prune and Index(修剪与索引)
Dream 会重建你的 MEMORY.md 索引,并遵循一个规则:不超过 200 行。
索引的定位是“轻量的指针文件”,而不是“内容堆场”。详细信息保存在各个主题文件中。
最后,Dream 会返回它所更改、合并或移除内容的摘要。如果你的 memory 本来就很干净,它会据实相告并退出。
最后想法
Auto-Dream 目前对大多数用户还未上线,但你已经可以使用它,因为 Dream 的 prompt 在 GitHub 上是公开的。
你可以把它做成一个 Claude Code 的 skill,并像我上面演示的那样手动运行。
构建 Dream Skill
想要快速开始,在任意项目里打开 Claude Code 并运行:
Create a new skill called dream using the Dream memory consolidation prompt
from https://github.com/Piebald-AI/claude-code-system-promptsClaude 会拉取该 prompt、创建 skill 文件,你就可以用 /dream 触发它。
运行方式
创建好 skill 后,你有三种选择,取决于你想整合的范围:
/dream——仅对当前项目的 memory 进行整合/dream user——对你的用户级 memory 进行整合(适用于所有项目)/dream all——同时对两者进行整合先在有多次历史会话的项目上运行
/dream。历史越多,它能清理出来的东西就越多。
合理的做法是在一次长或复杂的会话之后运行它,或者当你注意到 Claude 引用过时信息或自相矛盾时运行。
一旦 Auto-Dream 全量推出,这很可能会自动完成。
本文转载自AI大模型观察站,作者:AI研究生
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
RAG当主力,MemPalace把记忆准确率干到 96.6%,token 成本为0
决策树的启发方式深度解析
评审也不靠人,每天消耗10亿token!OpenAI核心工程师自曝极限经历:对代码细节没执念了!MCP早死了!软件依
OpenClaw会变Close?龙虾之父:不让OpenAI参与太多!梦境是从CC泄露的源码发现的!token处理会越来越快!
Hermes Agent 技术架构全解:当"自进化"被拆解为工程实现
大模型的“隐秘脑回路” | Claude Mythos是如何靠1个比特位翻转拿下Linux Root 的?
扒一扒Meta全新大模型Muse Spark里藏着的PDR技术
2026 新版 OpenClaw Windows 安装教程|一站式部署指南
2026 新版 OpenClaw Windows 极简安装教程|本地AI智能体快速上手全攻略
2026 新版 OpenClaw Windows 安装教程|本地 AI 智能体一键部署完整指南
AI精选