

MindVLA-o1-理想发布新一代自动驾驶基础模型
作者:互联网
2026-03-21
 AI模型库
AI模型库
作为自动驾驶领域的突破性创新,MindVLA-o1通过原生多模态架构实现了视觉、语言和行为三者的深度融合,为具身智能发展树立了新标杆。
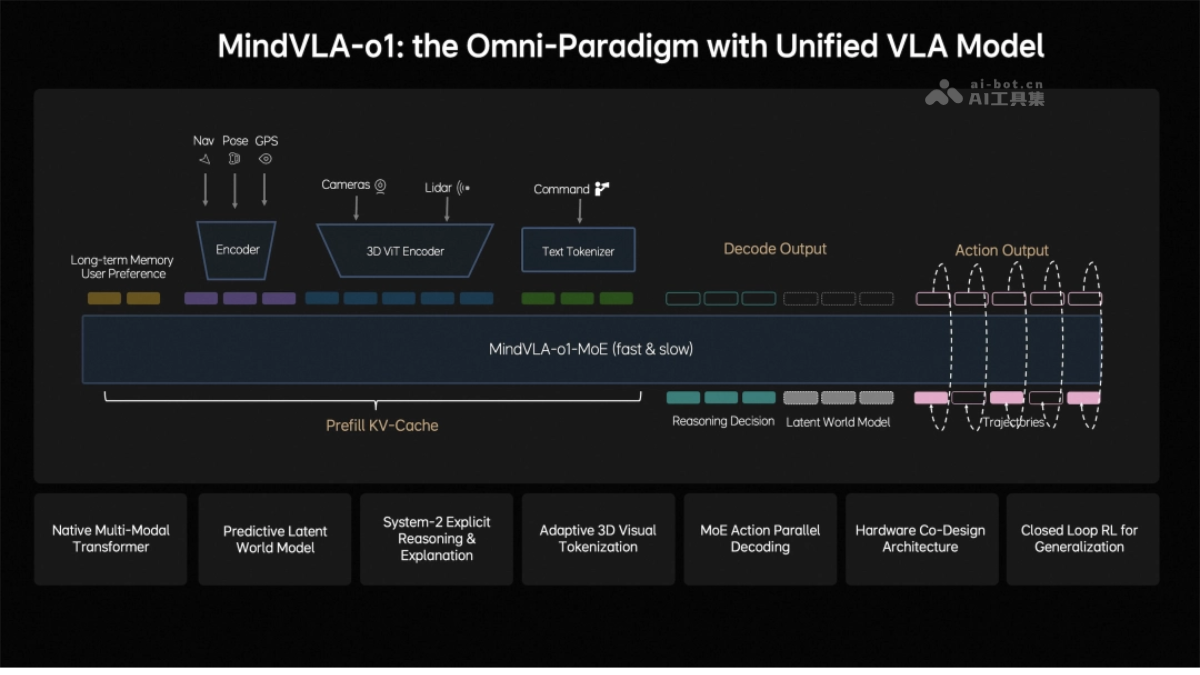
MindVLA-o1的主要功能
- 采用3D ViT编码器与前馈式3DGS表示技术,系统可精准识别静态环境和动态物体,实现三维空间的高精度感知。
- 通过预测式隐世界模型,在隐空间中推演未来场景变化,完成视觉理解和语言推理的深度结合。
- 借助VLA-MoE架构与并行解码机制,生成符合动力学约束的驾驶轨迹,满足实时性要求。
- 基于Feed-forward场景重建与强化学习框架,模型在仿真环境中持续优化,突破真实数据规模限制。
- 运用软硬件协同设计定律,在车载芯片上实现高效部署,平衡模型精度与推理效率。
MindVLA-o1的技术原理
- 3D自监督视觉编码技术利用LiDAR点云作为几何提示,通过下一帧预测任务完成自监督训练,使模型兼具语义理解和三维感知能力。
- 预测式隐世界模型在紧凑隐空间中进行高效预测,经三阶段训练构建未来场景的推演能力,实现当前理解与未来预测的统一。
- VLA-MoE架构中的Action Expert专门处理驾驶轨迹生成,采用并行解码一次性输出所有轨迹点,通过离散扩散进行多轮优化。
- 将传统逐步优化式重建升级为Feed-forward场景重建,结合生成式模型扩展仿真能力,实现低成本高效率的强化学习闭环。
- 基于Roofline模型评估近2000种架构配置,在端侧场景下发现更宽更浅的模型架构更为高效,大幅缩短架构探索周期。
MindVLA-o1的关键信息和使用要求
- 该模型定位为面向具身智能的原生多模态VLA架构,是下一代自动驾驶的基础模型。
- 2026年3月17日由基座模型负责人在行业大会上正式发布。
- 核心技术包括3D空间理解、多模态思考、统一行为生成等五大创新。
- 代表技术演进方向,从端到端到VLA再到原生多模态,开启物理AI时代。
- 同一套VLA模型可同时控制车辆与机器人,实现应用扩展。
- 需要统一VLA数据引擎支持大规模驾驶数据的采集、清洗和标注。
- 依赖可控多模态世界模型与强化学习基础设施,支持大规模闭环训练。
- 基于特定计算平台部署,需满足模型精度与推理延迟的最优配置。
- 依托统一3DGS渲染引擎与分布式训练框架,实现高效强化学习迭代。
MindVLA-o1的核心优势
- 采用原生多模态统一架构,实现视觉、语言、行为三模态的联合训练与对齐,提升效率与泛化能力。
- 通过3D ViT编码器与前馈式3DGS表示,突破传统BEV和OCC的局限,获得更深度的3D空间理解。
- 预测式隐世界模型在紧凑隐空间中完成高效推演,避免直接生成图像的高计算成本。
- VLA-MoE架构结合Action Expert等技术,确保轨迹生成兼具精度与实时性。
- 软硬件协同设计大幅缩短架构探索周期,在车载芯片上找到最佳平衡点。
MindVLA-o1的同类竞品对比
| 对比维度 | MindVLA-o1 | 特斯拉 FSD | 华为 ADS |
|---|---|---|---|
| 架构路线 | 原生多模态VLA统一架构 | 端到端纯视觉 | 端到端+多传感器融合 |
| 感知方案 | 视觉为主+LiDAR几何提示 | 纯视觉 | 多传感器融合 |
| 推理能力 | 隐世界模型预测未来 | 端到端隐式推理 | 规则+AI混合 |
| 行为生成 | MoE+并行解码+离散扩散 | 端到端直接输出 | 分段式决策 |
| 仿真训练 | Feed-forward重建+强化学习 | 影子模式+仿真 | 数据闭环为主 |
| 部署优化 | 软硬件协同设计定律 | 自研芯片Dojo/HW4.0 | 昇腾芯片优化 |
| 应用扩展 | 车辆+机器人通用VLA | 专注自动驾驶 | 专注自动驾驶 |
| 技术阶段 | 物理AI/具身智能 | AI-based端到端 | AI-based端到端 |
MindVLA-o1的应用场景
- 作为自动驾驶基础模型,可处理城市道路、高速公路等全场景
相关标签:
AI工具
AI项目和工具
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
NanoClaw 开源轻量级个人AI助手 安全可靠的OpenClaw替代方案
03/30
MonsterClaw 采用 OpenClaw 技术打造的本地化AI运行平台
03/30
TinyClaw 由TinyAGI推出的开源轻量级多智能体协作框架
03/30
携程酒店业务借助NebulaGraph实现月均风控止损逾百万元
03/30
稀宇科技开源MiniMax Office Skills生产级办公文档引擎
03/27
ToClaw由ToDesk打造的专业定制AI智能体
03/26
TypeNo 免费开源的中文AI语音输入法 无需配置直接使用
03/26
Sub2API 开源人工智能API中转网关平台 具备多账户管理功能
03/26
阿里通义推出视频生成音频框架PrismAudio
03/26
Luma AI发布Uni-1模型实现图像理解与生成一体化
03/25
AI精选