

豆包语音2.0字节跳动升级版AI语音模型
作者:互联网
2026-03-20
 ⼤语⾔模型脚本
⼤语⾔模型脚本
豆包语音2.0作为新一代AI语音解决方案,集成了三大核心技术模块,在语音识别、合成和音色复刻方面实现重大突破。这项创新技术正在重塑人机语音交互体验。
豆包语音2.0的核心技术
这款升级版AI语音系统包含三大核心模型:语音识别2.0、语音合成2.0和声音复刻2.0。语音识别模型显著提升了推理能力,通过深度上下文理解使关键词召回率提高20%;具备多模态视觉识别功能,不仅能处理语音还能解析图像;支持13种外语的精准识别。语音合成模型实现对话式合成,情感表达更自然,复杂公式朗读准确率达90%。声音复刻模型仅需5秒即可克隆音色,支持多语言情感传递。
核心功能详解
- 语音识别模型2.0
- 推理能力显著增强:采用PPO强化学习方案,无需依赖历史词汇即可准确识别专有名词和多音字。
- 视觉辅助识别:新增图像理解能力,通过单图或多图内容辅助语音识别,降低易混淆词的错误率。
- 多语言支持:在保持中英文高准确度基础上,新增13种语言的精准识别功能。
- 复杂场景优化:针对历史人物讨论、图片创作等特殊场景,通过逻辑推理提升识别准确度。
- 技术架构:基于Seed混合专家大语言模型架构,延续20亿参数音频编码器优势。
- 语音合成模型2.0
- 智能对话合成:通过指令和上下文信息精确控制语音的情感、语气和语调。
- 专业公式朗读:专项优化教育场景,覆盖全学科公式,朗读准确率高达90%。
- 多场景适配:广泛应用于教育辅助、情感陪伴、内容配音等领域。
- 声音复刻模型2.0
- 极速音色克隆:仅需5秒即可完成音色复刻,支持多种语言。
- 情感表达能力:复刻的声音能传递贴合语境的情绪,实现多角色演绎。
- 应用场景:适用于语音交互、有声读物、播客制作等场景。
性能表现
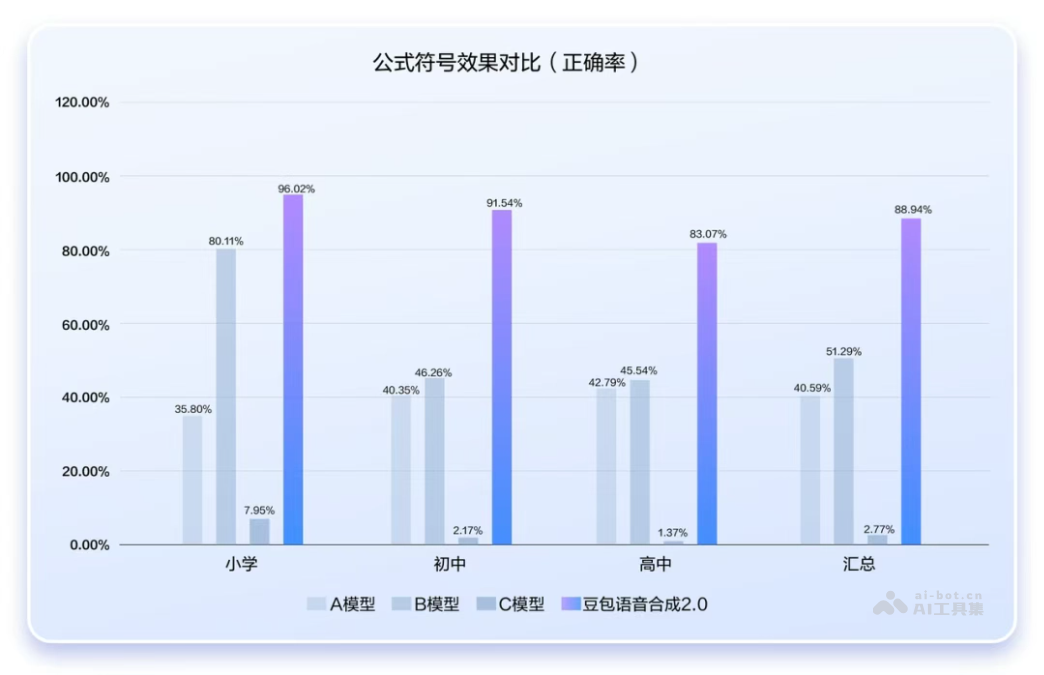
在教育场景专项优化中,该模型将复杂公式符号朗读准确率提升至90%,远超传统模型50%的水平,为教育领域提供更高效的语音解决方案。
应用场景
- 教育辅导:为中小学全学科提供精准语音辅助,准确率达90%。
- 情感陪伴:实现自然真实的情感表达,提升交互体验。
- 内容创作:广泛应用于视频配音、有声读物制作等领域。
- 文学演绎:支持多角色情感表达,增强故事表现力。
- 播客制作:理解多轮对话上下文,实现流畅的语音互动。
豆包语音2.0通过三大核心技术突破,为人机语音交互带来更智能、更自然的体验,正在教育、娱乐等多个领域展现其变革性价值。
相关标签:
豆包
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字
03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
03/30
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
AI精选