

开源视频生成模型Open-Sora及其类Sora架构复现方案
作者:互联网
2026-03-22
 ⼤语⾔模型脚本
⼤语⾔模型脚本
Open-Sora作为开源视频生成领域的创新项目,采用DiT架构实现文本到视频的智能转换。这个由Colossal-AI团队打造的解决方案完整公开了训练流程与技术细节,为开发者提供了宝贵的学习资源。
Open-Sora的技术解析
该项目基于DiT架构进行创新设计,通过三阶段训练实现高质量视频生成。首先进行图像预训练建立基础视觉理解,随后通过视频数据学习时序关系,最终采用优质素材提升输出效果。整个技术方案涵盖数据处理到模型训练的全流程。

项目资源获取途径
- 官方项目主页:https://hpcaitech.github.io/Open-Sora/
- GitHub代码库:https://github.com/hpcaitech/Open-Sora
核心架构设计
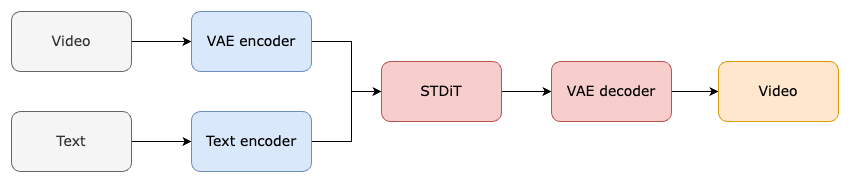
该模型采用Diffusion Transformer架构,在PixArt-α图像生成模型基础上扩展时间维度。其创新性地引入空间-时间注意力机制,实现视频数据的多维度处理。
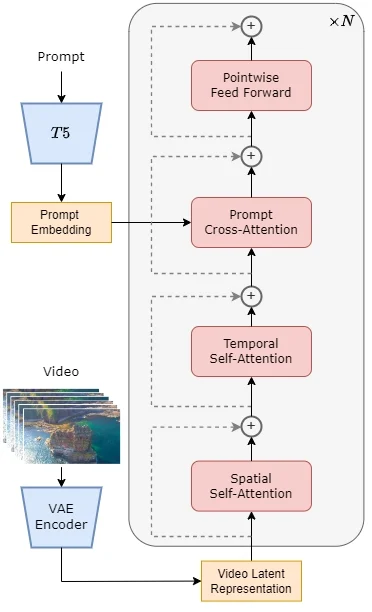
关键组件构成
- VAE组件:负责视频数据的压缩与重建,训练时编码输入视频,推理时生成潜在特征。
- 文本编码器:将文字描述转化为语义向量,指导视频生成的内容方向。
- STDiT模块:通过空间和时间注意力机制,协同处理视频的视觉特征与时序关系。
创新架构特点
- 双重注意力机制:空间模块处理单帧特征,时间模块分析帧间关联,实现视频理解。
- 语义对齐设计:交叉注意力层确保生成内容与文本提示保持高度一致。
- 完整工作流程:从数据压缩到特征生成,形成端到端的视频创作解决方案。
分阶段训练方案
参考SVD的工作方法,采用渐进式训练策略。首先建立图像生成能力,再扩展到时序理解,最终优化输出质量,形成完整的提升路径。
图像预训练阶段
利用海量图像数据初始化模型参数,继承现有图像生成模型的视觉理解能力,为后续训练奠定基础。
视频预训练阶段
引入时序注意力模块,通过多样化视频素材训练,使模型掌握动态场景的连续变化规律。
质量优化阶段
精选高质量视频数据进行微调,提升生成内容的细节表现力和视觉真实感。
Open-Sora通过创新的架构设计和严谨的训练方案,为开源社区贡献了可靠的视频生成解决方案,推动AI创作技术的发展。
相关标签:
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
SkyBot由Skywork研发的云电脑AI助手
AI Agent 智能体 - Multi-Agent 架构入门
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
一文搞懂卷积神经网络经典架构-LeNet
一文搞懂深度学习中的池化!
厦门大学DeepSeek大模型助力高校企业政府发展 PDF文件 AI教程资料
RAG 不一定非得靠向量库:一套更偏工程落地的“结构化推理检索”方案
北京大学DeepSeek与AIGC应用PDF AI教程资料
开源项目 superpowers 深度解读:把 AI Coding Agent 变成遵守工程流程的协作伙伴
金灵AI深度体验报告 CSDN推出金融投研AI智能助手
AI精选