

VASA-1微软发布静态照片生成对口型视频技术框架
作者:互联网
2026-03-22
 ⼤语⾔模型脚本
⼤语⾔模型脚本
微软亚洲研究院推出的VASA-1框架,实现了从静态照片到动态视频的突破性转变。这项技术通过单张人脸照片和语音音频,即可生成高度逼真的3D说话面部动画。
VASA-1的功能特性
- 精准的唇音同步效果:系统能够根据语音内容精确控制唇部动作,确保口型与发音完美匹配。
- 多样化的表情呈现:除了基础唇部动作外,还能展现各种复杂表情,包括细微的情感变化。
- 拟真头部动作模拟:自动生成自然的头部转动和倾斜动作,大幅提升动画的真实感。
- 高效的视频输出能力:支持实时生成512×512分辨率、40帧/秒的高清视频,延迟极低。
- 灵活的参数控制:可通过调整视线方向、头部距离等参数,实现个性化的动画效果。
- 广泛的输入兼容性:不仅支持常规照片,还能处理艺术肖像、歌唱音频等特殊输入。

VASA-1的技术实现
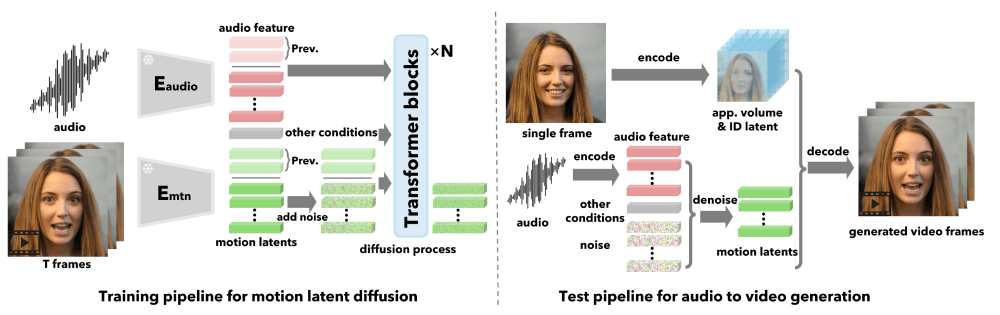
- 输入数据准备:系统需要一张静态面部图像和一段语音音频作为基础素材。
- 特征提取过程:通过面部编码器获取3D外观体积、身份特征等关键信息。
- 潜在空间构建:建立能区分面部动态与其他因素的专业建模空间。
- 模型训练方法:采用基于扩散的变换器模型进行专业训练。
- 控制信号处理:将视线方向等参数作为生成条件输入模型。
- 动态生成阶段:根据音频特征生成面部动作和头部运动的代码序列。
- 最终视频合成:利用面部解码器将生成的动态代码转换为视频帧。
相关资源链接
- 项目主页:https://www.microsoft.com/en-us/research/project/vasa-1/
- 技术论文:https://arxiv.org/abs/2404.10667
VASA-1通过创新的面部动态生成技术,为数字内容创作开辟了新的可能性,其逼真的效果和高效的处理能力展现了人工智能在视觉生成领域的突破。
相关标签:
Diffusion
相关推荐
专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
OpenClaw 真正的效率开关,不是 Prompt,而是多会话和子代理
03/30
10款免费AI语音输入工具与软件 轻松实现语音转文字
03/30
MCP 协议深度解析:构建 AI Agent 的「万能接口」标准
03/30
WorkAny Bot 云端AI Agent工具采用OpenClaw框架构建
03/30
Anthropic 的 Harness 启示:当 AI Agent 开始「长跑」,架构才是真正的天花板
03/30
SkyBot由Skywork研发的云电脑AI助手
03/30
AI Agent 智能体 - Multi-Agent 架构入门
03/30
Nano Banana 2 国内使用指南 LiblibAI 无需翻墙教程
03/30
一文搞懂卷积神经网络经典架构-LeNet
03/30
一文搞懂深度学习中的池化!
03/30
AI精选