

数据调度选型之ApacheDolphinScheduler为何能取代Airflow
作者:互联网
2026-03-20
 AI模型库
AI模型库
当团队面临数据平台选型时,一个轻量级且易于维护的调度系统成为迫切需求。Airflow的复杂性让我们开始寻找更优解决方案。
当时确实感到非常困扰。Airflow系统庞大,需要配置Python环境、Celery Executor以及Redis或RabbitMQ,大规模部署还需Kubernetes支持。对于人员有限的数据团队来说,维护成本实在太高。难道要退回到使用Crontab脚本的时代?这显然不是明智之选。
经过深入调研,我们在Apache孵化器中发现了DolphinScheduler(海豚调度)。这个由易观团队开源的项目已获得14.1K Stars,采用Apache 2.0协议,并成功晋升为Apache顶级项目。实际测试后,其表现令人惊喜。
与Airflow的Python代码配置DAG不同,DolphinScheduler提供了直观的可视化拖拽界面。通过简单的鼠标操作就能完成任务依赖关系的设置,大大降低了使用门槛。
系统支持30多种任务类型,包括Shell、SQL、Spark、Flink等,几乎涵盖所有大数据处理场景。例如执行Hive SQL任务时,只需拖拽SQL节点,配置数据源和脚本,连接上游依赖即可完成。整个过程无需编写Python代码,也不需要处理BashOperator或SparkSubmitOperator。
这种设计对非技术人员特别友好,数据分析师可以独立配置工作流,不再需要频繁求助开发人员。
DolphinScheduler采用去中心化架构,由五大核心组件构成:
- API Server:作为前端交互入口,负责工作流配置和用户权限管理
- Master Server:执行DAG解析和任务分发,支持多Master并行工作
- Worker Server:接收并执行Master分配的任务,完成后返回结果
- Alert Server:提供告警通知功能,支持多种消息渠道
- Registry:实现服务发现和分布式锁,可选JDBC、ZooKeeper或Etcd
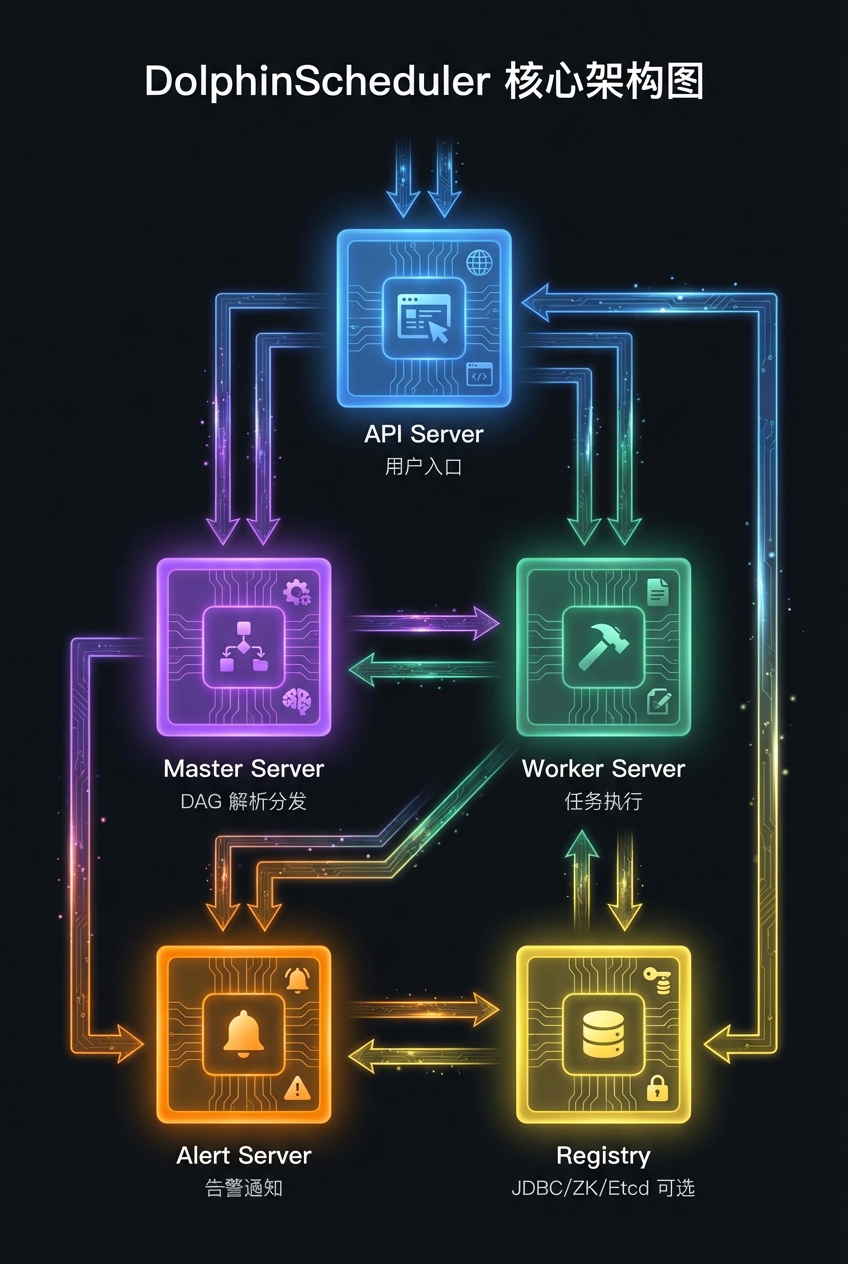
Master节点的去中心化设计尤为出色。多个Master之间不存在主从关系,它们通过Registry注册后,采用槽位分片算法分配任务。
具体分片机制基于ID取模运算。例如3台Master时,Command ID为1001的任务会分配给槽位1(1001%3=2,槽位从0开始计数)。当某台Master故障时,其槽位会被其他Master接管,确保任务不丢失。
相比Airflow复杂的Scheduler HA机制,这种设计更加简洁高效,Master节点可以轻松横向扩展。
DolphinScheduler提供三种注册中心选项。官方推荐使用JDBC,可直接复用现有业务数据库,无需额外部署ZK或Etcd集群,这对中小团队尤为有利。
当然,若已有ZK集群或需要处理高并发调度(上万任务),仍可选择ZK或Etcd方案。
与Airflow的Celery Executor不同,DolphinScheduler采用主动推送机制。Master通过Netty RPC直接将任务推送给Worker,避免了队列积压问题。
任务分配时实施动态加权轮询策略,综合考虑Worker的CPU、内存和线程池使用情况,确保负载均衡。当Worker接近满载时,Master会自动将任务调度到其他节点。
这种推送方式显著降低了调度延迟,Master能实时掌握Worker状态,任务不会在队列中长时间等待。
系统的插件化架构非常完善:
- 任务插件:内置30多种任务类型,支持自定义扩展
- 告警插件:集成多种通知渠道,可轻松添加新方式
- 数据源插件:支持上百种数据源连接
- 存储插件:任务日志和资源文件可存储于多种介质
扩展新功能十分便捷,只需开发对应插件打包部署即可,无需修改源代码。
官方提供四种部署方案:
- Standalone:单机模式,适合开发测试
- Cluster:集群部署,生产环境标准配置
- Docker:快速体验完整环境
- Kubernetes:云原生团队首选方案
快速体验推荐使用Docker Compose命令启动,几分钟内即可通过浏览器访问系统界面,使用默认账号即可开始配置工作流。
生产环境建议部署至少3台Master和若干Worker,数据库采用MySQL主从或PostgreSQL,注册中心选择JDBC即可。官方文档详细全面,部署过程较为顺畅。
最新3.4.0版本主要优化了以下功能:
- 任务优先级队列:支持高优任务插队执行
- 动态资源分配:Worker可根据任务类型调整线程池
- 工作流版本管理:自动保存历史版本,支持回滚
- 血缘分析增强:可视化展示数据依赖关系
其中任务优先级队列特别实用,紧急任务不再需要手动暂停其他任务来腾出资源。
DolphinScheduler特别适合以下场景:
- 10人以下的数据团队,运维资源有限
- 以离线批处理为主的工作场景
- 需要低代码平台支持业务人员参与
- 已有MySQL/PostgreSQL环境
不太适用的场景包括:
- 实时流式任务为主
- 需要大量自定义代码的复杂工作流
- 超大规模并发调度需求
总体而言,DolphinScheduler定位明确:易用、稳定、轻量。虽然不如Airflow灵活多变,但核心功能完善且维护成本显著降低。
我们团队迁移后,集群规模缩减40%,运维工作量减少50%。数据分析师现在可以自主配置工作流,极大提升了工作效率。
选择调度系统需要根据团队实际情况评估。若正在寻找Airflow的替代方案,DolphinScheduler值得认真考虑,它可能就是您需要的理想解决方案。
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
NanoClaw 开源轻量级个人AI助手 安全可靠的OpenClaw替代方案
MonsterClaw 采用 OpenClaw 技术打造的本地化AI运行平台
TinyClaw 由TinyAGI推出的开源轻量级多智能体协作框架
携程酒店业务借助NebulaGraph实现月均风控止损逾百万元
稀宇科技开源MiniMax Office Skills生产级办公文档引擎
ToClaw由ToDesk打造的专业定制AI智能体
TypeNo 免费开源的中文AI语音输入法 无需配置直接使用
Sub2API 开源人工智能API中转网关平台 具备多账户管理功能
阿里通义推出视频生成音频框架PrismAudio
Luma AI发布Uni-1模型实现图像理解与生成一体化
AI精选