

(四)为何你的数据仓库常在ADS层失控DWS才是破局关键
作者:互联网
2026-03-30
 AI快讯
AI快讯
在数据仓库架构中,DWS与ADS层是数据建模向业务交付转化的关键环节,其设计质量直接影响数据复用效率和业务响应速度。
若DWS层建设不足,指标将在ADS层重复生产导致口径混乱;而ADS层失控则会侵蚀公共层,形成难以维护的数据资产。健康的数据体系需在"公共沉淀"与"灵活交付"间建立清晰边界,本文将从四个维度系统解析DWS/ADS层的设计方法论。
DWS层常被低估甚至弱化,导致所有需求堆积到ADS层解决。这种短期看似灵活的方式,长期必然引发数据失控。
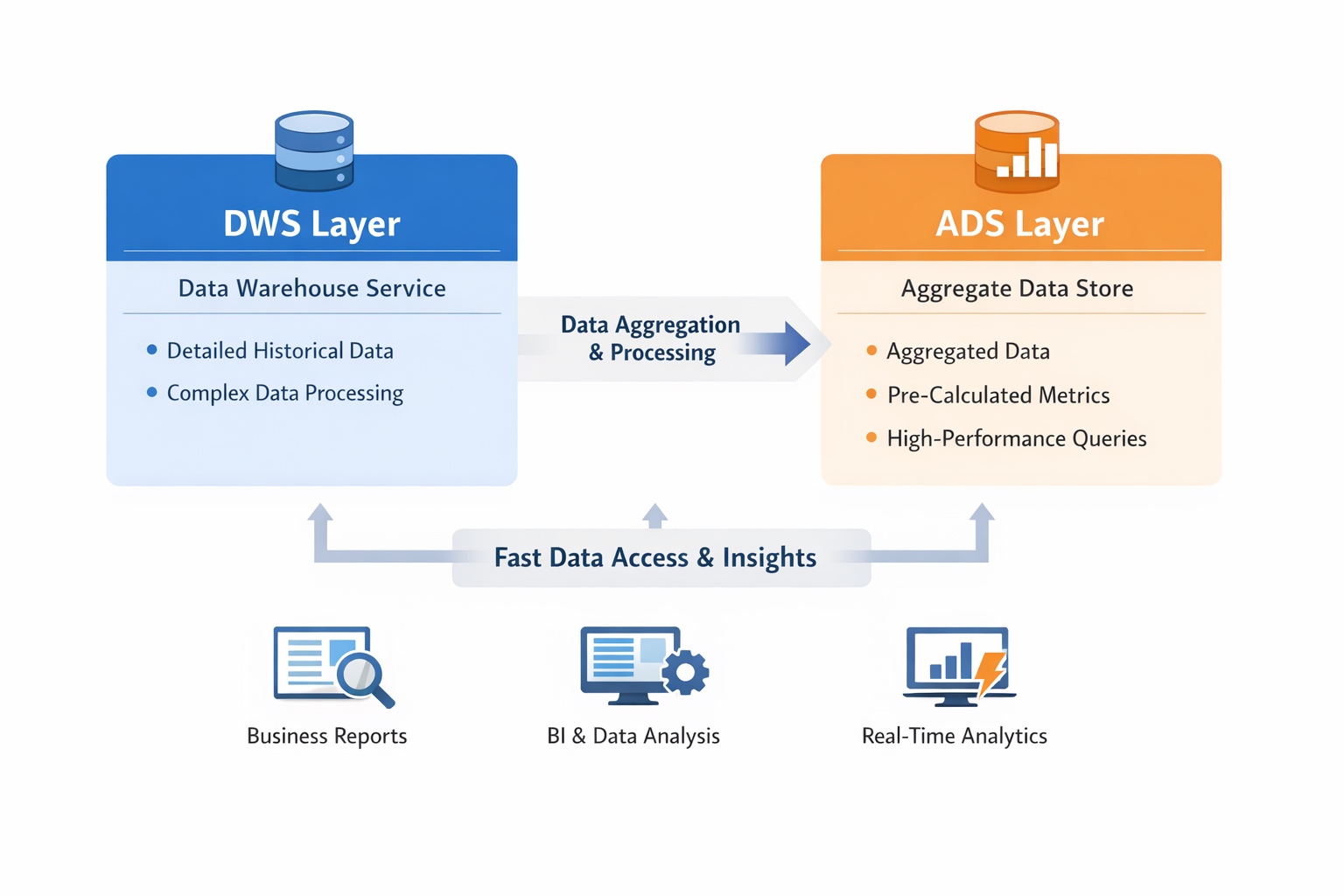
作为公共汇总与复用层,DWS应为多应用共享提供统一数据基础。建设不足会导致每个新需求都需重新计算定义,产生互不兼容的结果。
理想状态下,约70%分析需求可通过DWS组合完成。这种"拿来即用"能力是复用价值的核心体现,避免了重复建表的资源浪费。
当各部门都拥有独立ADS表时,同名指标对不上、重复计算等烟囱化问题将大量消耗团队时间。DWS通过沉淀高频维度聚合结果、构建主题宽表和统一指标口径,将分散计算前置到离线层,显著提升查询性能和成本控制。
DWS还改变了团队协作方式,使指标以数据资产形式存在:具备owner、定义、血缘和质量规则,将口径争议转化为资产治理问题。但前提是DWS必须可治理,否则会沦为"无人敢用的宽表集合"。
DWS设计围绕两类表展开:公共汇总表强调清晰定义聚合粒度、维度组合和度量口径;主题宽表侧重易用性,需避免不断膨胀的问题,可基于字段使用频率进行治理。
混合不同聚合层级是常见设计误区,应按层级拆分表或在命名上做强约束。所有设计的前提是核心维度必须统一编码和口径。
性能优化方面,DWS应采取"预聚合优先"策略,先通过离线计算减少扫描规模,再考虑索引等优化手段。
指标体系分为原子指标、派生指标和复合指标三个层级。原子指标需明确定义统计对象和范围;派生指标须继承原子指标口径;复合指标则最易产生歧义。
每个指标应具备业务定义、计算公式、统计范围和时间口径四要素,并实施版本管理。原子指标应沉淀在DWS层,ADS层仅负责轻量组合与展示。
ADS层面向具体消费场景,强调"好用"而非"通用",设计应遵循"一表一场景"原则。底线是所有核心指标必须源自DWS,ADS不得发明新口径。
更新频率需根据业务SLA明确约束,频率越高越需控制字段规模和计算复杂度。虽然可按部门划分数据集市,但必须基于统一维度与指标体系构建。
健康的数据体系应使公共层逐步增厚,交付层保持轻量,持续将通用能力回收沉淀到DWS。交付表需具备生命周期管理能力,及时下线低价值表。
成熟的数据体系不在于建设速度,而在于可持续使用。DWS与ADS的科学分层设计,正是支撑数据资产长期价值的关键保障。
- 数据湖仓架构搭建与开发规范全攻略:数据仓库与数据湖概述
- AI加持下的新兴数据湖仓架构与开发规范解析
- ODS/明细层落地设计要点:打造稳定可运维的基础设施
数据仓库建设规范与命名体系解析
相关标签:
相关推荐

专题
+ 收藏
+ 收藏
+ 收藏
+ 收藏
+ 收藏
最新数据
相关文章
总台马年春晚机器人团队将亮相2026人形机器人半程马拉松赛事
韩国Upstage计划逐步采用AMD Instinct MI355加速器
Meta发布AI支持助手全天候解决Facebook和Instagram账户问题
WTO数据显示AI商品贸易占比六分之一却贡献2025年四成以上增长
Firefox新设计语言Nova亮相 圆润界面风格引发与Chrome相似争议
阿里巴巴蔡崇信称CEO职位始终稳固智能体无法替代CEO
活动回顾她这种节点关于女性无限可能的MeetUp
2026年2月中国数据库排行榜:PolarDB登顶夺魁占鳌头TiDB扬帆破浪开新篇
六大主流数据同步工具深度评测DataXAirbyteCanalDebeziumFivetran与ApacheSeaTunnel
一文读懂OceanBase物化视图功能
AI精选